
人間とLLMは、次に来る言葉をどう予測するのか

一般的に、大規模言語モデル(以下、LLM)がテキストを出力する過程は「次の文字(厳密にはトークン)を次々に予測している」といった形で説明されます。一方、私たち人間も、会話や文章を理解するときに次に来る言葉をある程度先回りして予測していると考えられています [1] [2] [3] 。
では、人間の脳とLLMの予測メカニズムには、どのような共通点や違いがあるのでしょうか。
今回の研究は、脳波(EEG)と脳磁図(MEG)を同時に計測し、自然な音声を聞いている最中の脳の予測活動を品詞ごとに分析したうえで、LLM(Llama 3.2)の内部表現と比較した、という内容になります。
研究の方法
実験は、29名の健康な参加者(平均年齢22.8歳)を対象に実施されました。参加者は約50分間のドイツ語のSFオーディオブックを聴き、その間248チャンネルのMEGと64チャンネルのEEGで、脳の活動の様子を同時に記録しています。
記録にあたっては、音声中の各単語の開始のタイミングを正確に特定し、名詞、動詞、形容詞、固有名詞といった品詞ごとに脳がどのように反応するのかのパターンを分析しました。
さらに、同じオーディオブックのテキストをLlama 3.2に入力し、LLMの中で品詞の情報がどのように表現されるかを調べたうえで、その結果を人間の脳活動の結果と見比べています。
結果
1. 人間の脳活動は
名詞では、単語が始まる前から予測に関係する脳活動が確認されました。つまり、脳は名詞が来ることを事前に予測していることが示唆されています。
形容詞や固有名詞でもEEGでは似たような傾向が見られましたが、MEGで同じような傾向があったのは名詞のみでした。
一方、動詞では早い段階の脳活動はあまり確認されませんでした。
また、実際に人間が名詞を聞いたときには、側頭葉や前頭葉だけでなく、体の動きや感覚に関係する脳の領域(感覚野・運動野)に近い場所まで、脳活動が広がるパターンが確認されました。
著者らはこの結果から、名詞は動詞と比較して、実際の経験や体の感覚と結びついた意味を持ちやすいのではないか、と考察しています。
どういうことかといいますと、例えば人間が「りんご」と聞いたとき、その文字だけでなく、りんごの形、色、実際に触った感じなどを、これまでの経験からイメージすることが可能です。
そのため、名詞を理解するときには、言葉の意味を考える脳の働きだけでなく、感覚や動きに関わる広いネットワークも一緒に働きやすいと考えることができます。
2. Llamaの分析結果は
Llamaの分析では、埋め込み層の段階(浅い部分)で既に品詞ごとのまとまりがある程度見られ、層が深くなるにつれて、特に固有名詞は区別されやすくなっていました。
また、Llamaにこれまでの文脈から次の単語を予測させる実験では、名詞が他の品詞よりも高い確率で正確に予測されました。これは、名詞が予測されやすいという意味で人間の脳活動の結果と共通する面もありますが、著者らは「両者が単純に一致するわけではない点にも注意が必要」と述べています。
注意点
MEGのソース解析に関して、感覚野・運動野の活動として報告された結果は、近接する聴覚野からの信号の漏れの影響を受けている可能性があります。
参加者はすべてドイツ語を母語とする若年成人であり、他の言語や年齢層に一般化できるとは限りません。
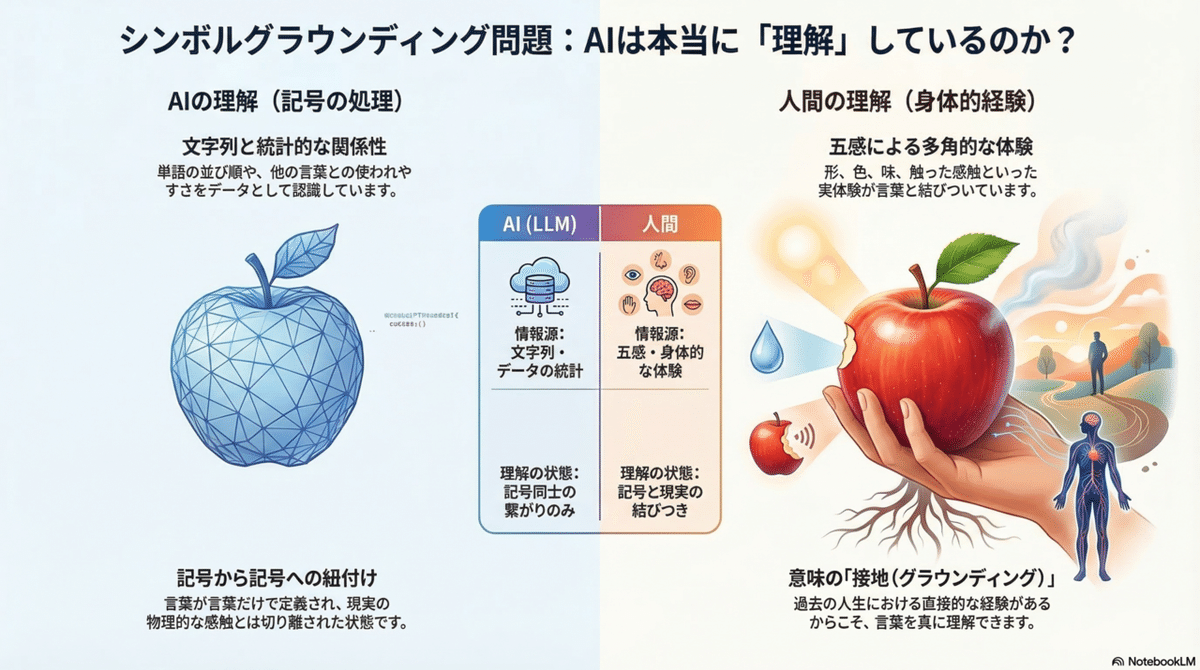
シンボルグラウンディング問題
シンボルグラウンディング問題とは、「言葉や記号で表されるものを、AIがどうやって認識・理解するのか」というものになります。
再度「りんご」の例を挙げると、少なくとも2026年3月現在のAI(LLMに限らず)は、「りんご」という文字列、他の単語との関係、文章の中でどのように使われやすいか、といったことを認識していると考えられますが、人間の場合はこれらの情報に加えて、りんごの形、色、味、そして触った感じやかじった感じ…といった内容をこれまでの人生で体験しているので、りんごという単語を聞いたときにこれらの情報を結びつけて理解することができます。
この違いを踏まえると、単語が単語だけで定義されている状態、または現実世界の経験に結びついていない状態のAIは、本当に意味を理解していると言えるのか、という疑問が出てきます。これがシンボルグラウンディング問題です。
これは、一見人間のように理解しているような出力をするLLM(生成AI)も例外ではありません。
そして、これを踏まえて今回の論文の示唆を振り返ると、
LLM:「この文脈なら、次は名詞が来そう」「この単語のあとには、こういう単語が出やすい」という規則性をうまく使っている
人間:「この流れなら次はこういう語が来そう」だけでなく、「それはどんなものか」「どんな経験と結びつくか」まで含めて、脳が準備している可能性がある
と解釈することができます。
表面上はどちらも「予測している」と言えますが、そのメカニズムが同じであるとは限らない、ということです。
だからこそ、服薬指導は人間の薬剤師が
実は私は、学生実習のときにクラリスロマイシンDSをオレンジジュースに混ぜて一気飲みしたという(色々な意味で)苦い経験があります。
「クラリスロマイシンDSを酸性飲料に混ぜるとコーティング(便宜上そう呼ばせてください)が剥がれ、クラリスロマイシンの苦みが出てくる」という知識が当時の私にもあったので、どれほどのものか試してみたくなったのです。
ただ、まさか一気飲みするとは思っていなかったのか、指導薬剤師の先生から「それは愚かだ」と言われ、口の中は何を飲み食いしても残り続ける強烈かつ化学的な苦みに包まれ、自ら志願したとはいえ…それはそれは辛い思いをしました。
その瞬間、私は「クラリスロマイシンDSを酸性飲料に混ぜてはならない」ということを、頭ではなく、心で理解しましたね。
…さて、薬剤師の皆さんであれば、クラリスロマイシンDSが処方された患者さんに対して「酸性飲料やヨーグルトには混合しないようにしてください」といった指導をされていると思います。
ただ、この情報はおそらく生成AIでも伝えられます。「クラリスロマイシンDSをジュースで飲んではいけない理由は?」と尋ねれば、酸性条件下でのコーティング崩壊のメカニズムを丁寧に説明してくれるでしょう。
しかし、生成AIが伝えられるのは知識だけです。
口の中に広がるあの苦味の感覚、こうして記事を書いている今も眉間にシワが寄るレベルの不快感。そしてそれが子どもだったら、どれほどのトラウマになりうるか…という身体的経験に基づく理解は、AIではできないのです。
なので、クラリスロマイシンDSの苦みを心で理解している私がクラリスロマイシンDSの服薬指導をするときは、毎回苦い経験を思い出しながら、しかし不安を与えすぎないように気をつけつつ、「幼い子どもが私と同じ気持ちにならないように…」という気持ちで、実体験に基づいたお話をしています。
確かに言葉だけ見れば「酸性飲料やヨーグルトには混合しないようにしてください」という内容になりますが、実際は私の体験に基づく絶望的な表情や辛い思い出を語るときの声のトーン、加えて具体的にどのような苦味なのかという情報もセットになっています。
…きっと、患者さんにも伝わっているはずです。
ここまで色々書いてきましたが
私が本当に伝えたいのは、患者さんとのコミュニケーションにおいては指導の内容だけでなく、今まで五感を活用して培ってきた様々な経験も重要になるということです。
生成AIが服薬指導の補助として活躍できる場面はありますが、その中心に立つのは、患者さんの体験を共有できる人間の薬剤師であるべきだと思います。
参考文献
[1] Bar, M. (2009). Predictions: a universal principle in the operation of the human brain.
[2] Schilling, A., & Krauss, P. (2024). The Bayesian brain: world models and conscious dimensions of auditory phantom perception.
[3] Schilling, A., et al. (2023). Predictive coding and stochastic resonance as fundamental principles of auditory phantom perception. Brain, 146(12), 4809–4825.
最後までお読みいただき、ありがとうございました。
Webサイト「薬剤師のためのAIノート」も、是非ご覧ください。
記事に関する内容以外のお問い合わせは、以下のフォームよりお願いいたします。
また、書籍「超知能時代の調剤薬局」発売中です。
Kindle Unlimited会員の方は無料で読むことができます。




