AIのペルソナ設定が薄っぺらい理由をスタンフォード大が解明した

ペルソナ設定の違和感
「30代女性、都内在住、IT企業勤務。趣味はカフェ巡り。落ち着いた口調で少し辛口」
AIにペルソナを与えるとき、だいたいこんな形になります。プロフィールカードとしてはよくできている。でもこれを元にAIに文章を書かせると、最初の数行はそれっぽいのに、話題が変わるとすぐに崩れる。
よく見かける破綻パターンがあります。「辛口レビュアー」のペルソナを設定して、いくつかの映画レビューを書かせる。序盤は確かに辛口で、それなりに読める。ところが感動系の作品を渡すと、辛口設定を律儀に守ってピント外れな批判を始めるか、急にキャラが溶けて素のAIに戻るか、どちらかになる。ペルソナが口調でしか定義されていないから、口調で対応できない場面が来ると処理できない。
この薄っぺらさの正体を、スタンフォード大学の研究チームが突き止めました。
2026年に発表された論文「HumanLM」。約2万6千人の実在ユーザー、約21万6千件の応答データを使った大規模な検証です。そこで示されたのは、表面的なペルソナ設定ではどれだけ精度を高めても限界がある、という事実でした。
大根役者と名役者
大根役者は台本のセリフを読みます。悲しい場面では悲しそうな声を出す。怒る場面では声を荒げる。対応としては間違っていない。でもアドリブを振られると固まる。その人物が何を考えているのか、内側を理解していないからです。
従来のAIペルソナ設定は、この大根役者と同じ構造でした。
過去の発言データから文体の癖を学ぶ。絵文字の頻度、ネガティブ表現の多さ、文末の口調。パターンの模倣は、似た場面ではうまく機能します。場面が変わると途端に怪しくなる。学習したのは内面ではなく口調だから。
名役者は違います。セリフを覚える前に人物の内面を構築する。何を信じていて、何を恐れていて、何を守りたいのか。それが入っているから、台本にない場面でもその人物として動ける。
研究チームがやったのは、この名役者のやり方を計算可能な形にすることでした。
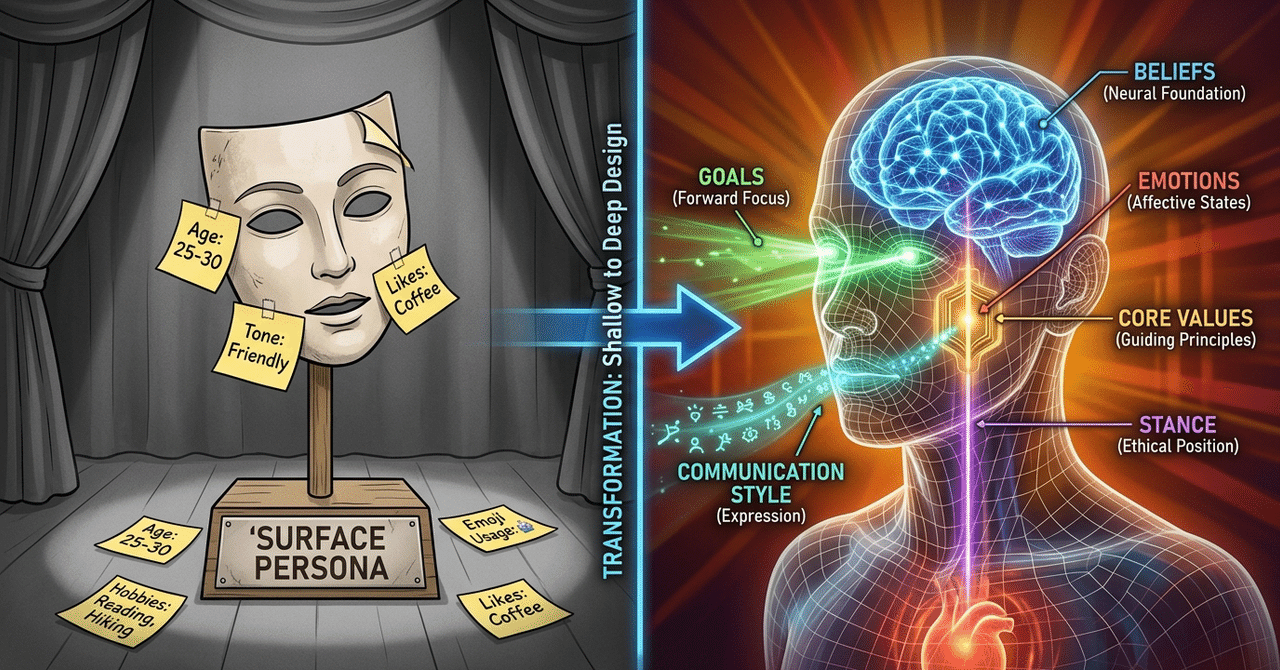
6つの内面軸
心理学の複数の理論を土台に、研究チームは人間の応答を駆動する内面状態を6つの軸に分解しています。
信念。 何を真だと思っているか。「再生可能エネルギーは現実的だ」と思っている人と「まだ技術的に足りない」と思っている人では、同じニュースへの反応がまるで違います。口調の問題ではなく、世界の認識の問題です。
目標。 何を達成したいか。同じ話題について書いていても、読者を説得したい人と自分の考えを整理したい人では文章の構造が変わります。
感情。 その瞬間、何を感じているか。同じ「反対」でも、怒りは断定的な短文を生み、心配は問いかけや仮定を生む。
価値観。 何を大切にしているか。正直さを最も重んじる人と、思いやりを最も重んじる人では、同じ状況で判断が分かれます。論文中の例が面白くて、正直さを大切にする人でも子どもにはサンタクロースの存在を肯定するかもしれない。価値観は次の「立場」と組み合わさって初めて行動になる。
立場。 その文脈でどのポジションをとるか。価値観が普遍的なものだとすれば、立場は文脈に依存します。職場では慎重な管理職、友人の前では率直に本音を言う。同じ人でも場面で変わる。
コミュニケーション方式。 どう伝えるか。口調ではありません。皮肉で伝えるのか直球か。根拠を並べるのか感情で訴えるのか。問いを投げるのか答えを断言するのか。伝え方の構造の話です。
6つは互いに独立しています。信念が同じでも感情が違えば反応は変わる。価値観が同じでも立場が違えば発言は変わる。組み合わせが、その人の応答を立体的に決める。
内面の鍛え方
研究チームがAIの内面をどう鍛えたか。
まず、いきなり文章を書かせません。6つの軸それぞれについて内面状態を推論させる。山火事のニュースに対するコメントなら、「このユーザーの信念は?」「感情は?」「コミュニケーション方式は?」と一つずつ言語化させます。
次に、その推論が本物のユーザーの応答と合っているかを、別のAIが審判として採点する。ここで工夫があって、一つの推論を単独で見るのではなく、複数の推論をまとめて比較採点します。「“政府への不信感"と"被害者への共感”、どちらがこのユーザーの実際の応答に近いか?」という相対評価。単独だと甘くなるスコアを、比較で精密にしている。
この採点を報酬として、強化学習で繰り返し鍛える。正解に近い内面推論には高い報酬、外れた推論には低い報酬。大量のフィードバックを経て、AIは的確な内面推論を身につけていく。
GRPOという仕組み
ここで使われている強化学習の手法がGRPO(Group Relative Policy Optimization)です。DeepSeekが開発し、数学的推論の精度を飛躍的に向上させたことで知られています。
従来の強化学習では、「この出力は良い/悪い」を判定する評価モデルを別途用意する必要がありました。GRPOはこれを省略します。同じ入力に対して複数の出力をまとめて生成し、そのグループ内での相対的な良し悪しを報酬にする。絶対的な正解を持たなくても、「この中ではこれが一番マシ」という比較で学習が進む。
HumanLMにとって、これは都合がよかった。「このユーザーの感情は怒りである」という推論が正解かどうか、絶対的な基準では判断しにくい。でも「怒り」「悲しみ」「無関心」という3つの推論を並べたとき、実際の応答に最も近いのはどれか、という比較なら評価できる。内面状態という曖昧なものを扱うのに、相対評価で鍛えるGRPOの設計が噛み合っています。
内面から言葉へ
文章を書くときの流れも変わります。まず6軸の内面状態を推論し、それをどう統合するかを考えてから文章を出力する。「冒頭は共感から入り、後半で皮肉を交えた批判に転じる」といった構成を、内面状態から導き出す。内面が先、言葉が後。名役者と同じ順序です。
結果
6つの領域で検証されています。ニュースコメント、書籍レビュー、日常の意見、政治ブログ、メール返信、AIアシスタントとの会話。すべてで従来の最良手法を上回り、平均16.3%の精度向上。
111名が参加したリアルタイム実験では、参加者が自分で書いた回答と、AIが生成した「自分のシミュレーション」を見比べて評価しています。HumanLMは「自分の回答に最も似ている」で最高勝率。55.9%の参加者が「ほぼ同じ」か「非常に似ている」と答えた。従来の最良手法は45.0%。
表面の模倣精度をいくら上げても届かなかった水準に、内面から設計するやり方は到達しています。
口調ではなく構造
noteやSNSで発信している人にとっても、これは遠い話ではないかもしれません。
口調を揃えた。アイコンを決めた。プロフィール文を整えた。それは衣装とメイクです。テーマが変わっても文体が多少揺れても「この人だな」とわかる人がいる。あれは口調から来ているのではなく、内面の構造から来ている。
何を信じているのか。何を達成したいのか。どんな場面で感情が動くのか。譲れない価値は何か。文脈でどう立場が変わるのか。どう伝える人間なのか。
スタンフォードの研究チームは、AIでそれを証明しました。表面をいくら磨いても超えられない壁がある。内面を設計すれば超えられる。
たぶん、人間も同じです。
読んでいただきありがとうございました。
コメント、記事購入、チップ等いつもありがとうございます。
大変感謝しております。
関連記事もありますので、下記サイトマップを参照していただければ幸いです。
いいなと思ったら応援しよう!
 よろしければ応援お願いします!チップはnote更新用のPC購入費用に当てる予定です。よろしく!
よろしければ応援お願いします!チップはnote更新用のPC購入費用に当てる予定です。よろしく!



