
複数のAIエージェントが協力することで、より良い成果物が出来上がる?


Hong, S et al. (2026). COMIC: Agentic sketch comedy generation. arXiv.
今回の研究は、AIエージェントが1〜2分のコメディ動画を自動生成できるかを検証したものになります。
今回の論文を読むに当たっては、単に「笑える動画を作った」という成果に目が向きそうになりますが(それも大事ですが)、それよりも正解がひとつではない課題に対して、AIをどう改善していくかという考え方のほうが重要です。
研究の方法
1. COMIC
今回の研究で提案されているAIエージェントは、「COMIC」と呼ばれています。COMICでは、以下のような役割が与えられたAIエージェントが活躍します。
Writer:設定・脚本案を生成
Critique, Edit:脚本の評価(Critique)と修正(Edit)
Scene Director:脚本を、動画を構成する最小の演出・生成単位(ショット単位)に分解
Image, Video, Voice Rendering:映像・音声の生成
Rendering Critique, Edit:映像の評価(Critique)と改良(Edit)
COMICでは、何らかの映像が一度出力されたらそれで終わりというわけではなく、脚本の段階でも映像の段階でも、何度も比較・修正・選抜が行われます。
2. 面白さの改善
著者らは、YouTubeにあるコメディ動画をもとに、5つのチャンネルから合計4,940件のデータを集めています。対象となったのは、Studio C、Foil Arms & Hog、Viva La Dirt League、Key & Peele、SNLです。
ただし、単純な再生回数だけを見ると、公開から長い時間がたっている動画ほど有利になりやすいという問題があるため、チャンネルごとに動画の伸び方をモデル化し、公開時期の影響をなるべく減らしたうえで、動画の人気を表す指標を作っています。
そのうえで著者らは、どの動画がより面白いかを判定するAI評価役(LLM critic)を複数用意し、その中から人間の視聴傾向に近い評価ができるものを選んでいます。
3. 脚本作りの工夫
脚本作りでは、「island-based evolution」という仕組みが使われています。これは、複数のグループの作業を同時進行させ、それぞれに少し違う評価役の組み合わせを配置する方法です。各グループの中で脚本同士を比べ、評価が低かった脚本だけをフィードバックにもとづいて書き直します。
この方法により、ひとつのパターンに偏りすぎず、違ったタイプのユーモアが残りやすくなります。論文では、こうした仕組みがユーモアにいろいろな形があることに対応していると説明されています。
結果
1. 人間の評価は
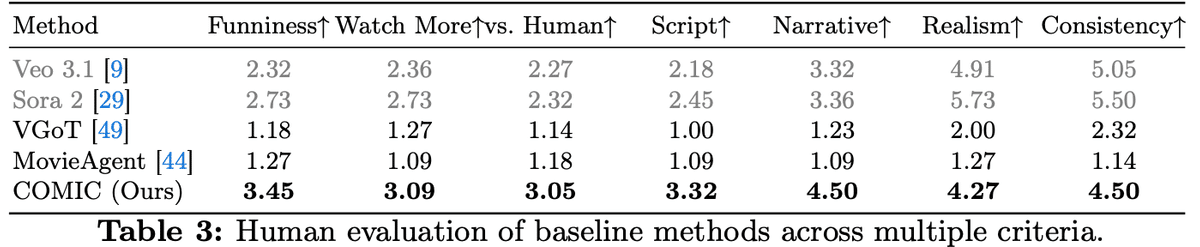
Hong, S et al. (2026). COMIC: Agentic sketch comedy generation. arXiv.
COMICはAgentic baseline(Veo 3.1、Sora 2)を大きく上回り、Sora 2や Veo 3.1よりもWatch More(もっと見たい)で高い評価を得ました。
また、vs. Human(人間の作品との比較)= 3.05 は、「人間作品より少し劣る」から「同程度」に近い水準と言えます。著者らは論文で「AIが作った短いコメディ動画が、プロの制作したスケッチ動画にある程度近づいている」と結論していますが、その主張をある程度支える結果と言えます。
2. AIの評価は
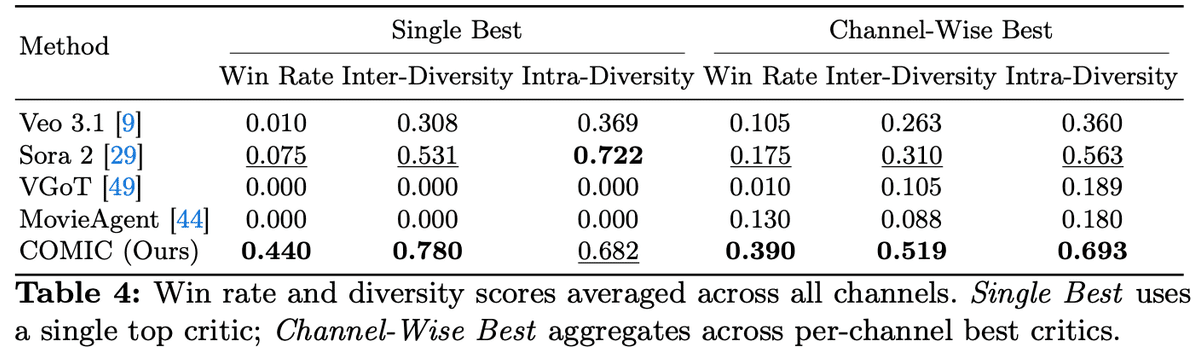
Hong, S et al. (2026). COMIC: Agentic sketch comedy generation. arXiv.
この結果を見ると、COMICはquality(質)だけでなくdiversity(多様性)でも良い成績を収めていることがわかります。言い換えると、複数のスタイルで実際に使えるネタを出せていることが示唆されたといえます。
3. 映像の改善には、何が重要だったのか
COMICは、何度も作り直して改良していくこと、いくつかのグループに分かれて別々にアイデアを育てること、候補をたくさん出して比較すること、そして批評役のAIが改善点を指摘すること、そのすべてが合わさって性能を高めています。
つまり、一度に良い映像を作り出そうとするのではなく、評価役のAIエージェントを介入させて競わせることで、映像がどんどん面白くなっていったと考えられます。
注意点
YouTubeの(正規化した)視聴数を面白さの代理指標として使っているため、クリックベイト(いわゆる「釣り」)や推薦アルゴリズムの影響は無視できません。
人手による評価は各手法ごとに22件の回答で行われており、文化の差や笑いの好みの違いまでが十分に反映されているとは限りません。
相手の反応に基づく評価をすることが重要
今回はたまたまコメディ動画の作成がテーマでしたが、コメディ動画に限らず、クリエイティブで評価基準が明確でないようなタスクを遂行するにあたっては、複数のAIエージェントに異なる役割を割り当てて、複数のアイデアを競わせて批評したのち改めて選出し直す、というアプローチが良い結果につながることが示唆されました。
特に、評価の基準を研究者や開発者の感覚だけで決めるのではなく、実際の視聴者の反応に近い評価へ寄せようとしたことがポイントで、実際に「作るAIエージェント」と同じくらい、「見分けるAIエージェント」や「選び直すAIエージェント」の役割が重要だったということです。
例えば、薬局オリジナルの患者さん向け資料を作成することを考えたとき、生成AIを使って「医薬品の専門知識を持たない患者さん向けに書き換えてください」と言えば、それらしい文章がすぐに完成します。
もちろんその文章は薬剤師が評価することになりますが、薬剤師が見て「言い換えが適切である」と判断したとしても、患者さんから見ると「難しい」「読む気にならない」「結局何に気をつければいいのかわからない」という評価になることは十分考えられます。これはAI側の能力不足というより、評価する側の視点が偏っていることによって生じる問題でもあります。
ゆえに、このような評価基準が明確でないようなタスクでは、「誰にとって良い文章なのか」を見極める評価者をいかに設計するかが重要になってくるでしょう。
例えば、ひとつの文章案に対して、
薬学的観点から見て正確かを確認する役割
一般の患者さんが読んで理解しやすいかを見る役割
不必要に不安を煽っていないかを見る役割
このような役割のAIを設定しておくと、「正確だが伝わらない文章」や「わかりやすいが重要な注意が脱落した文章」といった極端な例を減らしやすくなるでしょう。
COMICのような環境を調剤薬局に設計するのは現実的ではありませんが
ここまで書いておいてなんですが、今回のCOMICのようなAIエージェント達を設計するのは簡単ではありません。ただ、COMICの仕組みをそのまま再現することが難しくても、複数の視点で評価するという考え方を取り入れることはできます。
実際、生成AIに対して「薬学的に正確かどうか確認してください」「患者さんが理解しやすいか確認してください」「不必要な不安を与えていないか確認してください」といった質問を順番に投げかけるだけでも、簡易的にそれぞれの視点から文章を見直すことができます。完全に自動化されたエージェントでなくても、薬剤師がそのような問いを自ら立てていくことが、質の高いアウトプットにつながるはずです。
そして、これは生成AIを使わない場合でも応用できる考え方です。
薬学的に正確かどうかを確認するときは別の薬剤師に聞いてもよいですし、患者さん視点で理解しやすいかを検証するときは薬剤師以外のスタッフに聞いてみると良いでしょう。スタッフとのコミュニケーションのきっかけにもなりますし、異なる視点から自分の成果物を見てもらうことにより、新たな発見があるかもしれませんよ。
最後までお読みいただき、ありがとうございました。
Webサイト「薬剤師のためのAIノート」も、是非ご覧ください。
記事に関する内容以外のお問い合わせは、以下のフォームよりお願いいたします。
また、書籍「超知能時代の調剤薬局」発売中です。
Kindle Unlimited会員の方は無料で読むことができます。
