Dear friends,
I’ve been hearing from people at all levels of seniority about a feeling of job insecurity. High-school students wonder if there will be a job for them, engineers worry about keeping up, C-level officers wonder if they’ll manage to help their businesses transform with AI, and many more. Amid the frenetic pace of AI advancements and multiple sources of geopolitical uncertainty, the future feels less certain at this moment than at any other I recall. In moments like this, I think about what we can build to take advantage of the exciting possibilities ahead. But I also think about what is stable that I can count on, such as community and skills. To those of you who are navigating an uncertain environment, I hope this will bring some comfort.
The frenetic pace of AI advancement makes the future of jobs and of many businesses uncertain. On the business front, the venture investor Chamath Palihapitiya wrote a thoughtful article on how share prices are affected as businesses face disruption from AI. tl;dr. The value of many companies is in the cash flows they are expected to generate in the long term, and if their cash flows might be impaired due to disruption by AI, they become much less valuable.
Further, even though representatives from frontier AI labs often make confident-sounding predictions about the future, when I’ve spoken privately with some of them, they share that they really don’t know what will really happen in a few years. In software, some trends are clear: Highly agentic coding systems will continue to get better; the Product Management bottleneck, which is already acute, will get worse; and many more people will be coding. But despite these trends, exactly what software engineering will look like and how software engineering teams will be organized in the future is only slowly coming into focus.
Separately from the pace of AI advancement, many flashpoints add risk to the future. The war in Iran, which is leading to tragic civilian deaths as well as the Strait of Hormuz blockade; uncertainty over the future of peace in Taiwan and the impact on semiconductor supplies; potential overinvestment in AI infrastructure; and China’s control over rare-earth metals. Because of our interconnected world, any of these can significantly impact people anywhere, thus enhancing risk for everyone.
Jeff Bezos famously said that knowing what’s not going to change in the next 10 years creates a stable foundation on which to build a business. Many many things in the world will still be the same in 10 years as now. But for individuals who are worried about job security, I would put forward two things that I think will be stable in that timeframe: Community and skills.

First, 10 years from now, I know that my friends and family will still be there for me. Just as I know that no matter what, I will still be there for them. Relationships can be incredibly durable. During Covid, many communities bonded and supported each other. This is why, in moments of uncertainty, having communities — networks of relationships — helps everyone. That’s why opportunities to build relationships are so valuable and help us both get more done and protect ourselves against downside risks. This is why I find in-person gatherings — where we can make new friends and refresh existing relationships — especially valuable. If you would like to attend an event, please come to AI Dev, which will be held on April 28-29 in San Francisco.
Additionally, whereas a particular business may or may not do well, many skills will continue to be valuable. Your skills are something that you can always take with you, and no one can ever make you lose a skill you’ve earned. Exactly what skills are valuable will change, so it’s worth investing in a range of them to give yourself more options, and perhaps even learn some skills that might not be immediately applicable. Further, skills stack on top of each other (e.g., understanding prompting is important for using coding agents, and understanding AI building blocks is important for understanding how to architect certain applications). So building skills makes it easier to gain additional knowledge, and investing now in building a range of skills means that come what may, you can still accomplish a wide variety of valuable things.
I’m optimistic that many of the risks we’re seeing will work out well, and our collective AI future will be far brighter than it is today. You can count on me to be here to support you, and to support the AI community. As we navigate this fast-moving and uncertain world, let’s help each other out, build community, and keep helping each other gain valuable skills.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

In our latest course, made in collaboration with Oracle, you’ll build a complete agent memory system that lets an LLM store, retrieve, and refine knowledge across sessions — turning a stateless agent into one that learns and improves over time. Sign up here
News
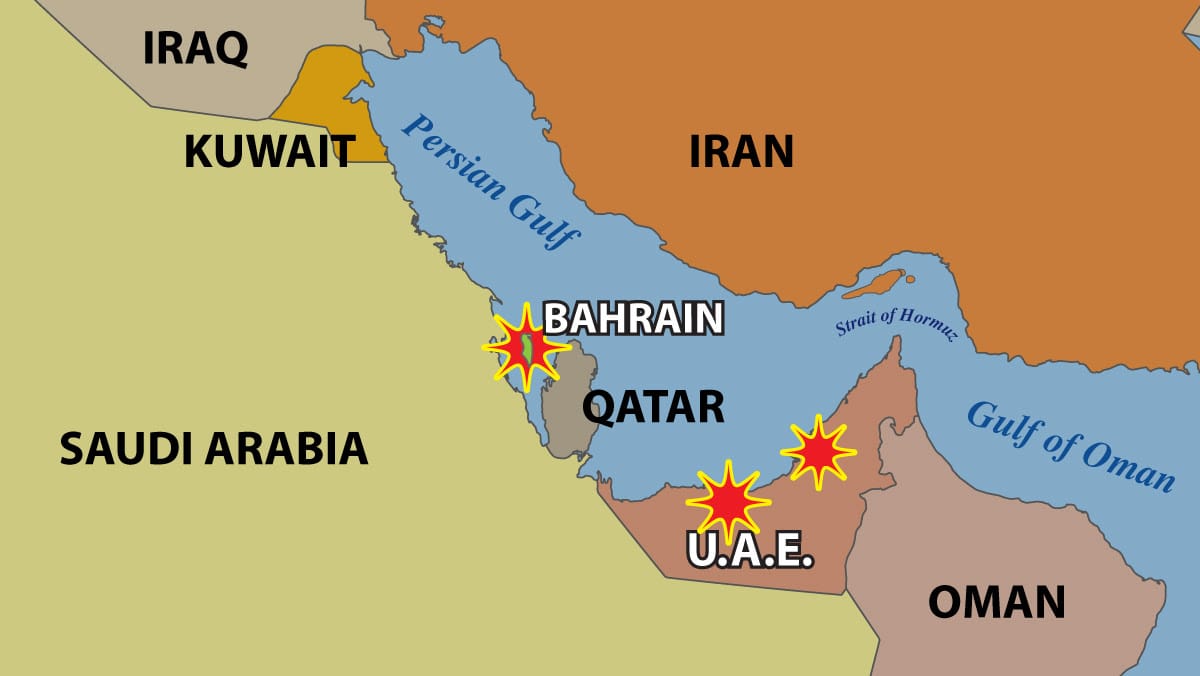
Drones Hit Persian Gulf Data Centers
Iran hit at least three Amazon data centers in the Middle East, an indicator of AI’s critical role in the United States’ war against Iran and possibly the first time such facilities have been targeted during warfare.
What happened: Iranian drones damaged an Amazon Web Services (AWS) facility in Bahrain and two in the United Arab Emirates (UAE), disrupting online services including banking, payments, ride sharing, food delivery, and business software. The U.S. military uses AWS to run the unclassified version of Anthropic Claude and possibly other computing systems, but it didn’t disclose whether the attacks affected its operations.
Drone attacks: Early on March 1, drones struck two AWS data centers in the UAE, and the Bahrain data center suffered damage shortly afterward. Amazon said the Bahrain attack was “a drone strike in close proximity to one of our facilities,” while Iran said it had targeted the facility “to identify the role of these centers in supporting the enemy’s military and intelligence activities,” according to Iran’s state-controlled Fars News Agency via the messaging service Telegram.
- The data centers suffered structural damage, power disruptions, and water damage caused by firefighters, which resulted in service outages and higher-than-normal error rates. As of March 3, Amazon recommended that its cloud-computing customers back up data and move workloads from AWS Middle East Region to the U.S., Europe, or Asia Pacific.
- The attacks put at risk trillions of dollars of investments to build AI hubs in the Persian Gulf region, The New York Times reported.
- Member nations of the Gulf Cooperation Council, an economic union and military alliance that includes Bahrain, Kuwait, Oman, Qatar, Saudi Arabia, and the United Arab Emirates, host 2.0 gigawatts of data center capacity, with an additional 0.4 gigawatts planned, Business Insider reported.
Behind the news: The risk to data centers mirrors a rise in AI’s role in warfare. Despite the U.S. military’s recent decision to ban defense uses of Anthropic’s Claude large language model, U.S. forces routinely use Claude and other systems for a variety of purposes in Iran and elsewhere. For its part, Iran uses weaponized drones that have some degree of autonomy.
- Claude was part of a system that helped select more than 1,000 targets during the initial 24 hours of the U.S. war on Iran, enabling U.S. forces to vastly accelerate the pace of strikes, The Washington Post reported. Claude is integrated with Maven Smart System (MSS), a system for targeting and logistics built by Palantir. To avoid errors, human analysts check the system’s output in life-and-death situations. In exercises, MSS reduced the targeting process from 12 hours to less than 1 minute and achieved results with a staff of 20 that previously required 2,000, Army Times reported. Claude/MSS played a role in the January operation that captured Venezuelan president Nicolás Maduro, but the actions in Iran are its first use in “major war operations.”
- The use of inexpensive drones has become a defining feature of the recent U.S.-Iran war. Iran responded to the initial U.S. bombing campaign with large waves of attack drones — many of them low-cost “kamikaze” designs that navigate autonomously and attack on command — aimed at regional infrastructure, military sites, and U.S. assets. The U.S., in turn, unleashed its own one-way attack drones, including the LUCAS system modeled on Iran’s Shahed-136. This style of warfare draws heavily on Ukraine’s innovations developed during the Russia-Ukraine war, where swarms of drones — often coordinated with software and AI — have destroyed tanks, artillery, and logistics targets.
Yes, but: As AI raises the pace of military decision-making, it also raises the risk of deadly mistakes. For example, during the initial wave of air strikes on Iran, a bomb destroyed a school, killing more than 170 people, mostly children. In a subsequent investigation, preliminary findings indicate that U.S. forces likely dropped the bomb. Out-of-date target data may have played a role in targeting the building, since the school was part of a nearby naval base roughly 15 years ago.
Why it matters: The sharp rise of AI-enabled warfare signals a shift in the pace of combat from human to machine speed. AI makes it practical to plan missions by running vast numbers of simulations to identify actions most likely to lead to success. It accelerates battlefield decisions and actions while potentially reducing the so-called fog of war that can obscure realities on the battlefield. Missions become viable that previously were constrained by lack of human attention to analyze the flood of battlefield communications, imagery, and other information. The acceleration could shorten some phases of conflict, yet it adds pressure to make snap decisions that could have catastrophic consequences.
We’re thinking: AI-generated recommendations don’t remove the need to verify intelligence, question assumptions, and weigh the moral and strategic consequences of using force.
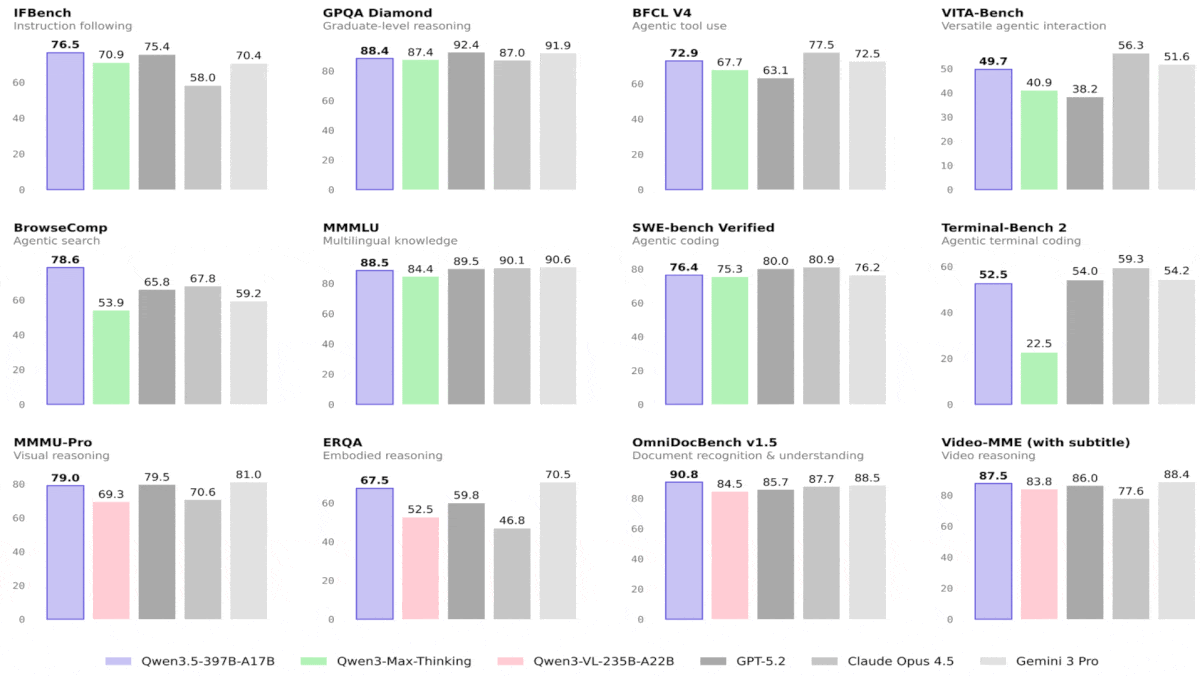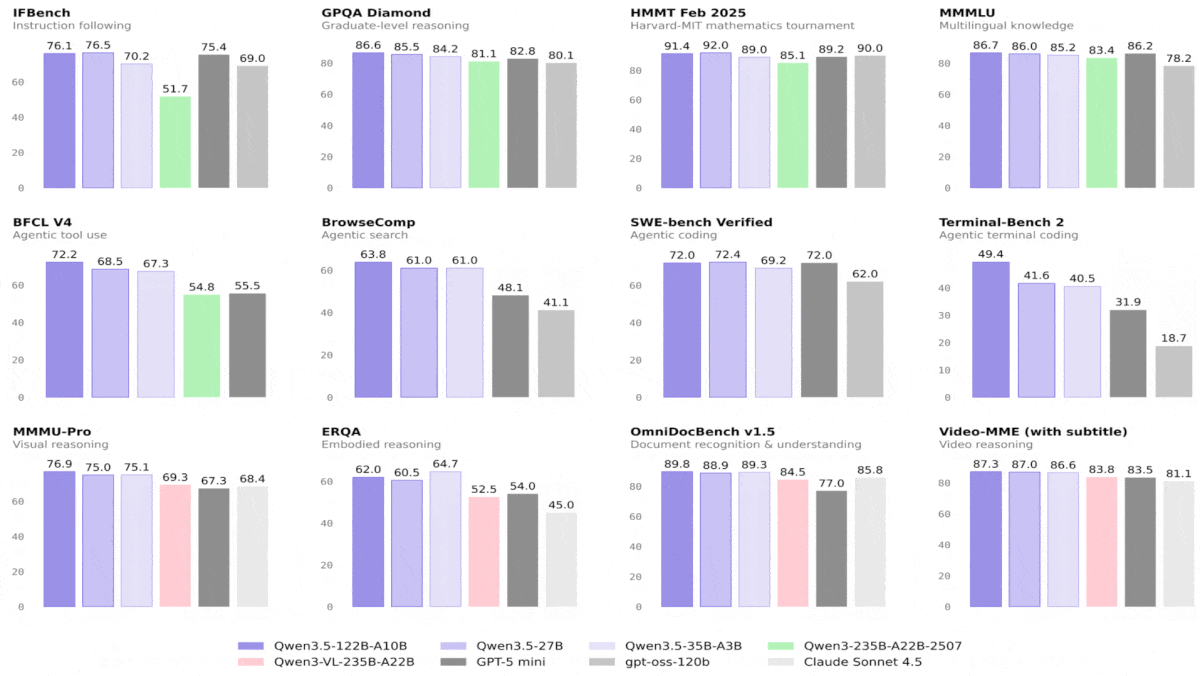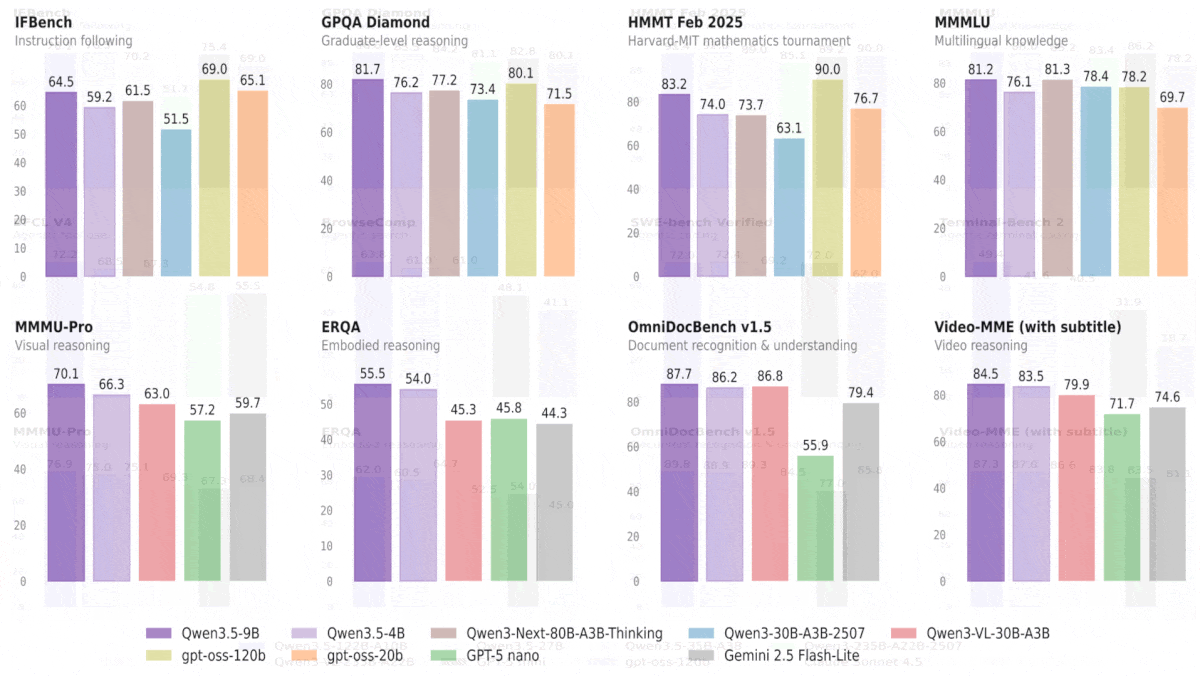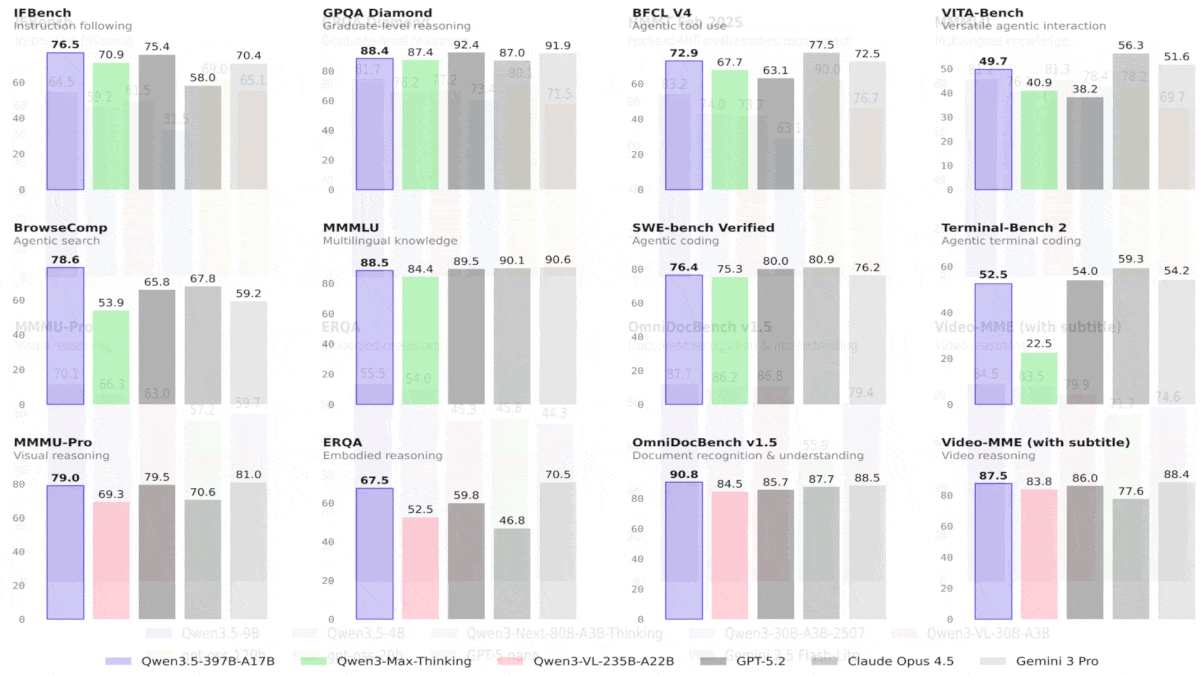
Qwen3.5 Outperforms Bigger Models, Leads Vision Benchmarks
The Qwen3.5 family of open-weights vision-language models includes impressive larger models as well as a smaller one that outperforms an OpenAI open-weights model 10 times its size.
What’s new: Alibaba released the Qwen3.5 family of eight open weights vision-language models. The largest are Qwen3.5-397B-A17B (397 billion parameters, 17 billion active per token), which offers open weights, and Qwen3.5-Plus, a hosted version of Qwen3.5-397B-A17B that supports agentic applications by providing a larger input context and built-in tools that it can select autonomously. Four medium-size models include the open-weights Qwen3.5-122B-A10B, Qwen3.5-35B-A3B, and Qwen3.5-27B, plus Qwen3.5-Flash, a hosted version of Qwen3.5-53B-A3B that’s outfitted for agentic applications. Among the smaller Qwen3.5 members of the family — Qwen3.5-9B, Qwen3.5-4B, Qwen3.5-2B, and Qwen3.5-0.8B — the 9-billion and 4-billion parameter variations rival the performance of much larger models.
- Input/output: Text, image, video in (open-weights models 254,000 tokens extensible to 1 million tokens, hosted models up to 1 million tokens by default), text out (up to 64,000 tokens)
- Architecture: Mixture-of-experts or dense transformer with mixed attention and Gated DeltaNet layers, unspecified vision encoder
- Performance: Excellent vision performance overall; Qwen3.5-9B (9 billion parameters) outperforms gpt-oss-120B (120 billion parameters) on many language tasks.
- Availability: Open weights are freely available under the Apache 2.0 license; API for hosted open-weights models via Alibaba Cloud Model Studio (prices vary according to the specific model, $0.20-$0.60/$2-$3.6 per 1 million input/output tokens); API for Qwen3.5-Plus $0.4/$0.04/$2.4; API for Qwen3.5-Flash $0.1/$0.01/$0.4 per 1 million input/cached/output tokens.
- Features: 201 languages, tool use, web search, chain-of-thought reasoning
- Undisclosed: Vision encoder, training data, and methods
How it works: Alibaba shared little information about how it built the Qwen3.5 family.
- Qwen3.5 is built on the Qwen3-Next architecture, a variation on the Qwen3-30B-A3B architecture and training method that’s modified to increase training efficiency and stability.
- Qwen3.5 was trained on a “significantly larger scale of visual-text tokens” than Qwen3.
Results: Tested by Alibaba, all Qwen3.5 models excelled at vision tasks, outperforming much larger models, and some turned in competitive results in language tasks as well. Qwen3.5-9B and Qwen3.5-4B showed the most impressive performance overall, shining in both vision and language tasks, even compared to much larger models. The two smallest variations lack comparative metrics.
- On 28 of 44 vision benchmarks, Qwen3.5-397B-A17B outperformed GPT-5.2, Claude 4.5 Opus, and Gemini-3 Pro, whose parameter counts are undisclosed but almost certainly much larger. In a variety of language tasks, Qwen3.5-397B-A17B outperformed either GPT-5.2, Claude 4.5 Opus, or Gemini-3 Pro, but generally it did not outperform all three.
- On most language and vision benchmarks tested, Qwen3.5-122B-A10B and Qwen3.5-27B exceeded GPT-5-mini (parameter count undisclosed). Generally, Qwen3.5-122B-A10B, a mixture-of-experts architecture that activates 10 billion parameters per token, outperformed Qwen3.5-27B, a dense architecture of 27 billion parameters. Qwen3.5-35B-A3B generally underperformed the smaller Qwen3.5-27B and Qwen3.5-122B-A10B, but nonetheless it outperformed GPT-5-mini in 58 of 74 benchmarks tested.
- Qwen3.5-9B outdistanced OpenAI’s language model gpt-oss-120b — more than 10 times bigger — on most of the language benchmarks tested except reasoning and coding tasks. Similarly, Qwen3.5-4B outperformed OpenAI’s language model gpt-oss-20b on most language benchmarks tested except reasoning and coding tasks. On most of the vision benchmarks tested, both Qwen3.5-9B and Qwen3.5-4B outperformed the vision-language models GPT-5-nano and Gemini-2.5-Flash-Lite.
Behind the news: Shortly after rolling out the Qwen3 family, Lin Junyang, the team’s technical lead and a key architect of the models, abruptly resigned with a post on the X social network that read, “Bye my beloved qwen.” The Chinese tech-news outlet 36kr.com subsequently reported that four other members of the team resigned in his wake. In a January public appearance, Lin had said, “We are stretched thin — just meeting delivery demands consumes most of our resources,” Bloomberg reported. Alibaba responded by putting the Qwen project under tighter supervision by senior leadership and promising to invest further in AI development.
Why it matters: All Qwen3.5 models deliver stellar vision performance for their sizes, but the smaller models — especially Qwen3.5-9B — are small enough to run on consumer laptops while delivering performance that previously required an 80GB GPU like a Nvidia H100.
We’re thinking: Vision-language models with reasoning capability that are small enough to run locally means reduced cost, better privacy, and new vistas for vision-language applications.

DeepSeek Snubs Nvidia for Huawei
DeepSeek, the Chinese developer of outstanding open-weights models, has withheld an upcoming update of its flagship model from U.S. chip makers, a move that intensifies the AI rivalry between the U.S. and China.
What’s new: DeepSeek has not yet given Nvidia or AMD an opportunity to make sure its upcoming DeepSeek-V4, which is in the final stages of development, will run smoothly on its chips — a departure from the typical practice prior to major model updates. However, it did share a prerelease version of the model with Huawei, giving the Chinese chip maker several weeks to optimize the software for its hardware, Reuters reported although it did not report DeepSeek’s reasoning for the decision.
How it works: According to Reuters, chip makers typically examine new models to make sure they run inference efficiently on their hardware. In the past, DeepSeek has worked closely with Nvidia to train its models.
- An unnamed senior Trump administration official said DeepSeek-V4 was trained in China using Nvidia’s most advanced chips despite U.S. export controls on such products, Reuters reported, although it was not able to learn how the official obtained this information.
- Nvidia supplied extensive technical assistance to DeepSeek when it trained DeepSeek-V3, achieving “major training efficiency gains,” the chairman of the U.S. House of Representatives Select Committee on China said in January.
Behind the news: For years, the U.S. has tried to slow China’s AI effort by restricting exports of advanced chips and the equipment needed to produce them. But that effort has largely backfired by spurring China to build its domestic chip industry, and China’s government has taken steps to encourage or require companies in that country to use domestic chips.
- Although chips produced in China do not yet rival those designed by Nvidia and manufactured by Taiwan Semiconductor Manufacturing Corporation, Chinese companies, notably Huawei, have made strides in recent years.
- After tightening restrictions progressively since 2022, in January, the U.S. government began permitting exports of top-of-the-line AI chips on a case-by-case basis, subject to a 25 percent charge on such sales. However, officials are considering new export limits.
- Last year, China’s government mandated a security review of Nvidia’s H20 chip, which was designed for the China market. Meanwhile, it asked Chinese AI companies to buy foreign chips only when necessary.
Why it matters: While DeepSeek’s decision to withhold prerelease access to DeepSeek-V4 from U.S. chip makers may be more symbolic than significant, it deepens the divide between the portions of the AI community that are based in the U.S. and in China. The decision aligns with China’s long-standing goals of technological self-sufficiency, so critical AI capabilities remain available regardless of adversaries’ efforts to block them.
We’re thinking: The possibility that DeepSeek trained its latest model using Nvidia chips is one among several indicators that export restrictions alone are not stopping international rivals from gaining access to U.S. chips. The world would benefit more from negotiated limits, mutual cooperation, and free exchange of ideas, technology, and trade.

A Single Tokenizer for Visual Media
Multimodal models typically use different tokenizers to embed different media types, and different encoders when training to generate media rather than classify it. A team at Apple created a multidimensional tokenizer that maps not just images and videos, but also 3D objects into a shared token space for any of these visual media — and a shared encoder that performs well at both identifying such objects and generating them.
What’s new: Jiasen Lu, Liangchen Song, and colleagues from Apple trained AToken, a transformer model with an all-purpose visual tokenizer. The new model can both generate and classify images, videos, and 3D, approaching the performance of specialized models for each of these input and output types.
Key insight: Image generation models use encoders (like VAEs or VQ-VAEs) that preserve visual details (is the cat’s/ball’s surface orange?) but discard semantics (is it a cat or a ball?), and therefore don’t recognize objects as well as classification models. Image classification models, on the other hand, use encoders (like CLIP or SigLIP) that capture types of objects (say, “cat” or “ball”) but miss visual details, so they are worse at generation. Moving from still images to video and 3D complicates matters further. Before they’re encoded, video and 3D typically require separate tokenizers to break down images into data an encoder can process, each with its own architecture and embedding space. If the three media types are analyzed using the same tokenizer in a single format, one transformer can learn to work with all of them. Further, training the model to reconstruct these media types and align them to matching text descriptions forces embeddings to retain both fine visual details and semantic references, eliminating the need for separate generation and classification models.
How it works: AToken consists of a pretrained SigLIP2 vision encoder (400 million parameters) — here extended from two dimensions to four — and an untrained decoder of the same size. The authors trained AToken to reconstruct inputs and align their embeddings to text using three image sets (two public and one private), three public sets of videos, and two public sets of 3D objects, all paired with matching text. They trained on this data in three stages: first images, then videos, and last 3D.
- The authors split every input into tokens with space-time coordinates (t, x, y, z). Images were mapped as a single two-dimensional (x,y) slice, setting t = z = 0. Videos included an extra coordinate for time (t, x, y, with z = 0), and 3D objects mapped onto an (x, y, z) grid, with t = 0. A single linear layer turned each token into an embedding.
- They also used 4D Rotary Position Embedding, to encode angular position along time, height, width, and depth (t, x, y, and z). The encoder took each linear embedding along with its relative position to produce embeddings that represented the input.
- The decoder reconstructed the inputs from the encoder’s embeddings: It generated RGB pixels for images and videos and Gaussian splats — small colored 3D blobs that, when rendered together, form a coherent 3D shape — for 3D objects. AToken learned to reconstruct inputs via four losses: (i) the first minimizes the difference between predicted and ground-truth pixels; (ii) LPIPS (landing page not found) which minimizes the distance between the AlexNet embeddings of the original and those of the reconstruction; (iii) CLIP perceptual loss, which minimizes the distance between the CLIP embeddings of the reconstruction and those of the original; and (iv) Gram matrix loss, which minimizes differences in style and individual features by maximizing the correlation between embeddings from an unnamed pretrained network of the reconstruction and the original image.
- To align embeddings of visual inputs with the embeddings of their corresponding captions, the authors combined all the encoder’s embeddings through attention, producing one global embedding that summarized the input, a process called attention pooling. They used contrastive loss to increase the similarity between the global visual embedding and the SigLIP2 text embedding of the matching caption, while decreasing the similarity to embeddings of mismatched captions.
Results: AToken matched or closely approached state-of-the-art models that process images, videos, or 3D.
- When classifying images, AToken reached 82.2 percent ImageNet classification accuracy, close to that of dedicated image encoders like the stand-alone SigLIP2 (83.4 percent). When generating images, it achieved 0.21 rFID (a measure of reconstruction quality, lower is better). This outperformed previous models with unified tokenizers such as UniTok, which uses a specialized encoder for each type of input, and approached specialized models like FLUX.1 [dev], which achieved 0.18 rFID.
- When reconstructing videos from the TokenBench dataset, AToken achieved 36.07 PSNR (frame-by-frame pixel similarity to the original videos, averaged over all frames — higher is better) and 3.01 rFVD (a measure of reconstruction quality — lower is better). This outperformed specialized video models such as Wan2.2 (36.39 PSNR, 3.19 rFVD) and HunyuanVideo (36.37 PSNR, 3.78 rFVD) at video quality but underperformed them at pixel similarity. When asked to identify videos from a text prompt, AToken found the correct video 40.2 percent of the time on the MSR-VTT dataset, still below strong video-focused encoders like VideoPrism-g, which reached 52.7 percent.
- When reconstructing 3D objects from Toys4K data, it reached 28.28 PSNR (a measure of how close reconstructed 3D renderings are to the originals – higher is better). This exceeded the specialized 3D tokenizer Trellis-SLAT, which achieved 26.97 PSNR.
Why it matters: A major innovation of large language models is their use of a single tokenizer for all language inputs, whether code, dialogue, tables, or books, etc. This generality eases a model’s ability to transfer knowledge from one data source to another during training. When models get better at understanding or generating text, they get better at code, too. AToken offers a similar generality for vision models, particularly when it comes to 2D and 3D objects. AToken’s strong performance at generating and reconstructing multiple visual media types suggests that here, too, a shared tokenizer and encoder could allow improvements from one modality to carry over to the others.
We’re thinking: A model like AToken may prove helpful for generating synthetic 3D and video data. Models that generalize from one media type to another generally reduce the amount of total data needed to train for each task. For example, high-quality, well-labeled, two-dimensional image data is abundant compared to video and 3D, which are both essential to robotics applications.




