中国のDeepSeek社の生成AIモデル「DeepSeek-R1」は、高性能でありながら、開発費やAPI利用料が他社モデルに比べて大幅に安価なことで、大きな話題を呼びました。本特集では、DeepSeek-R1を実際に触って、動かして、その生成AIの能力を体感します。
他社モデルとの比較
ここからは、DeepSeek-R1を他社のモデルと比較してみます。引き続きOllamaのローカル環境を使います。
比較に使うDeepSeek-R1は、日本語ファインチューニング版ではない「deepseek-r1:8b」を再び用いることとします。比較対象の他モデルも、日本語ファインチューニング版が提供されていないものもあるので、すべて通常版を用いることとします。原則、パラメーター数が80億のモデルを使います。
なお、ここで行う他社モデルとの比較は、本特集執筆時点(2025年6月時点)の、筆者の環境でのものです。環境が異なれば、比較結果が異なる可能性があります。また、今後モデルの更新などがあれば、結果結果は大きく変わる可能性があります。ご了承ください。
まずは同じ推論(r)モデルとして、「Qwen3」と比較します。その中から、パラメーター数が80億の「qwen3:8b」を用います。「deepseek-r1:8b」のベースとなるモデルでもあります。
[Ctrl]+[D]キーで「DeepSeek-R1-Distill-Qwen-14B-Japanese」を終了させ、コマンドプロンプトに戻ったら、下記のコマンドを入力・実行してください。

「qwen3:8b」が起動したら、以下のプロンプトを送信します。「deepseek-r1:8b」のときと同じプロンプトです。

筆者の環境で得られた出力結果の例が、図10です。
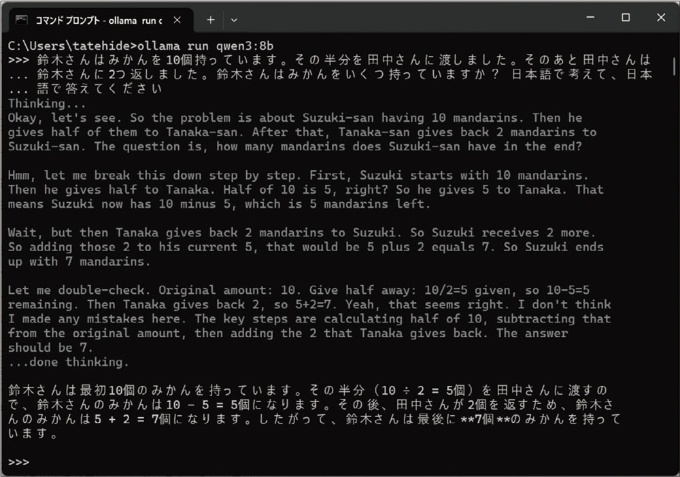
筆者の環境で試した限り、「deepseek-r1:8b」との大きな違いは、「qwen3:8b」の場合は思考過程が英語のみであることでした。上記のプロンプトを連続して送信しても、英語のみでした。「deepseek-r1:8b」の場合、1回目は中国語または英語でも、2回目からは「同じ質問が来たということは、日本語で~」と自ら判断したのか、思考過程を日本語に変えていました。一方、「qwen3:8b」は2回目以降も英語のままでした。
思考過程の中身を見てみると、大まかな流れは「deepseek-r1:8b」とほぼ同じです。「Wait」以降で、思考過程の見直しも行っています。ただし、「deepseek-r1:8b」ほど多面的な見直しを行ったわけではなさそうです。そのため、思考過程の分量は少なかったです。
この違いは、いわば、「qwen3:8b」は「結論まで最短で走る」というイメージで、「deepseek-r1:8b」は「いろいろ寄り道をする」というイメージでしょうか。かといって、推論(r)の能力として、「deepseek-r1:8b」の方が優れているとは言い切れません。「deepseek-r1:8b」は、他のプロンプトでは、思考を過剰に巡らせ、なかなか結論にたどり着けないケースがいくつかありました。ユーザーにとってどちらがよいのかは、ケース・バイ・ケースでしょう。
また、思考過程の歩みを一歩一歩進めていくスピードは、筆者環境で試した範囲では、ほぼ同じでした。
次のページ
コーディング能力で比較この記事は会員登録で続きをご覧いただけます




