ChatGPTやClaudeといった最先端のLLM(大規模言語モデル)は、単一の質問(プロンプト)に対しては高い精度で回答できる一方、日常会話でよくある複数回のやり取りからなる質問には精度がガクッと落ちてしまう――。そんなLLMの思わぬ弱点を示す論文が、2026年2月の世界SNS言及で1位になった。Microsoft ResearchとSalesforce Researchの研究チームによる「LLMs Get Lost In Multi-Turn Conversation(大規模言語モデルは複数ターンにわたる会話で混乱する)」である。
関連論文: LLMs Get Lost In Multi-Turn Conversation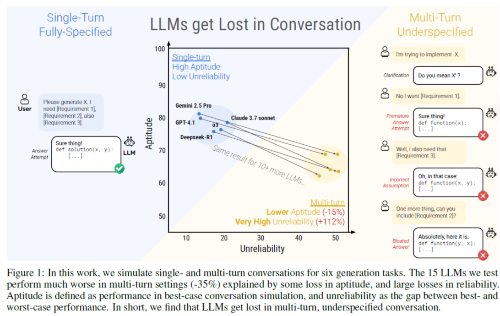
この論文が投稿されたのは2025年5月だが、2026年4月開催のAIトップカンファレンス「ICLR 2026」の口頭発表に採択された他、2026年2月に著者の1人がX上で「現時点での最新モデルでも同様の精度劣化がみられる」と明らかにしたことで、AI研究者の間で改めて注目された。研究者コミュニティーの間で、AIエージェントの社会実装にあたって解決すべき長期的課題の1つと認識されつつある。
これまでLLMの性能を測るベンチマークの多くは、単一の質問テキストに対する回答の精度を測定するものだった。一方、日常会話の多くは複数のやり取り(ターン)の中で少しずつ情報が明らかになるのが一般的で、一問一答型のベンチマークとは乖離(かいり)がある。そこで論文の著者は「1つの質問を複数の断片に分割し、それを段階的に開示する」AIを構築し、最新のLLMと対話させた。
例えば、「アンドリューは600kcalのシナモンロール200個と450kcalのマフィン300個を作りました。アンドリューが作ったお菓子の総カロリーを計算してください」といった単一の質問を、
「アンドリューが作ったお菓子の総カロリーを計算してください」
「まず、アンドリューはシナモンロールを200個作りました」
「さらにアンドリューはマフィン300個も作りました」
「ちなみに、シナモンロール1個のカロリーは600kcalです」
「マフィン1個のカロリーは450kcalです」
といった複数ターンの会話に分割し、LLMに逐次入力した。この手法で、当時の最先端のLLMに対して20万件以上の会話シミュレーションデータを取得した。
この結果、LLMの回答精度は、1回の質問で全ての情報を示す単一ターンのケースで約90%だったのに対し、情報を小出しにする複数ターンのケースでは約65%に低下した。LLMは最初の質問に対し、足りない情報を勝手に追加して誤った回答を出力する傾向がみられた。その後のやり取りで情報を全て与えても、LLMは当初の誤答を引きずる形で「迷走」し、誤った回答を返すことがあった。こうした精度の劣化は、評価した15モデルすべてで例外なく観測されたという。
なお、著者の1人であるPhilippe Laban氏が2026年2月にX上で示した最新の調査結果によると、GPT-5.2やClaude Opus 4.6のような最新モデルでも同様の傾向がみられたという。
関連投稿: https://x.com/PhilippeLaban/status/2026329136864645390論理推論(Reasoning)思考の長さ・深さを問わず劣化がみられたことから、この問題は「一問一答を前提としたベンチマーク」に最適化された現在のLLMが共通して抱える課題といえそうだ。AIと人間が日常的に対話する未来に向け、本質的な解決が求められている。
次のページ
AIエージェントをめぐるトラブルの責任はどこにこの記事は有料会員限定です




