SRA: Span Representation Alignment for Large Language Model Distillation
arXiv cs.CL / 5/5/2026
📰 NewsIdeas & Deep AnalysisModels & Research
Key Points
- The paper introduces SRA, a new framework for Cross-Tokenizer Knowledge Distillation (CTKD) that avoids brittle token-level alignment by aligning at the span level.
- SRA treats each span as a cluster of particles and represents it using an attention-weighted “center of mass” to capture semantic information in a tokenizer-agnostic way.
- It prioritizes salient spans via attention-derived weighting and adds a geometric regularizer to maintain the structure of the representation space.
- The method also includes aligned span logit distillation to improve how knowledge transfers between teacher and student models.
- In cross-architecture distillation experiments, SRA reportedly delivers consistent and significant improvements over existing CTKD baselines, supporting the authors’ physically grounded modeling approach.
Related Articles
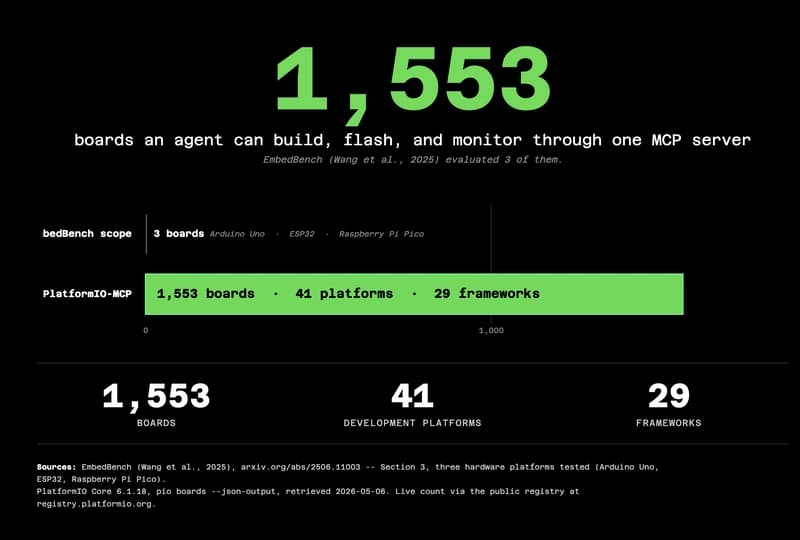
The 55.6% problem: why frontier LLMs fail at embedded code
Dev.to

Four CVEs in a week, all the same shape: when agents execute LLM-generated code
Dev.to
Healthcare AI Is Absorbing Institutional Knowledge It Can't Actually Hold
Reddit r/artificial
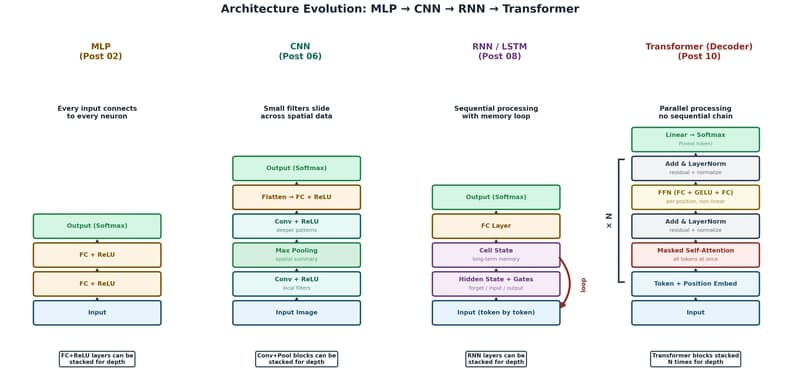
The Transformer: The Architecture Behind Modern AI
Dev.to

Foundational Models Defining a New Era in Vision: A Survey and Outlook
Dev.to