RoLegalGEC: Legal Domain Grammatical Error Detection and Correction Dataset for Romanian
arXiv cs.CL / 4/22/2026
📰 NewsDeveloper Stack & InfrastructureSignals & Early TrendsModels & Research
Key Points
- The paper introduces RoLegalGEC, a Romanian-language parallel dataset specifically designed for grammatical error detection and correction in legal-domain text.
- RoLegalGEC aggregates 350,000 error examples with annotations sourced from realistic legal passages, addressing the shortage of manually labeled data for Romanian.
- The authors evaluate multiple neural approaches that use the dataset for both detecting and correcting grammar errors, including knowledge-distillation Transformers and sequence-tagging-based detection.
- For correction, they test several pre-trained text-to-text Transformer models to translate the annotated data into practical correction performance.
- The work aims to expand the research resource base for Romanian and to enable further studies on legal-domain language error correction.
Related Articles
No Free Lunch Theorem — Deep Dive + Problem: Reverse Bits
Dev.to

Salesforce Headless 360: Run Your CRM Without a Browser
Dev.to
RAG Systems in Production: Building Enterprise Knowledge Search
Dev.to
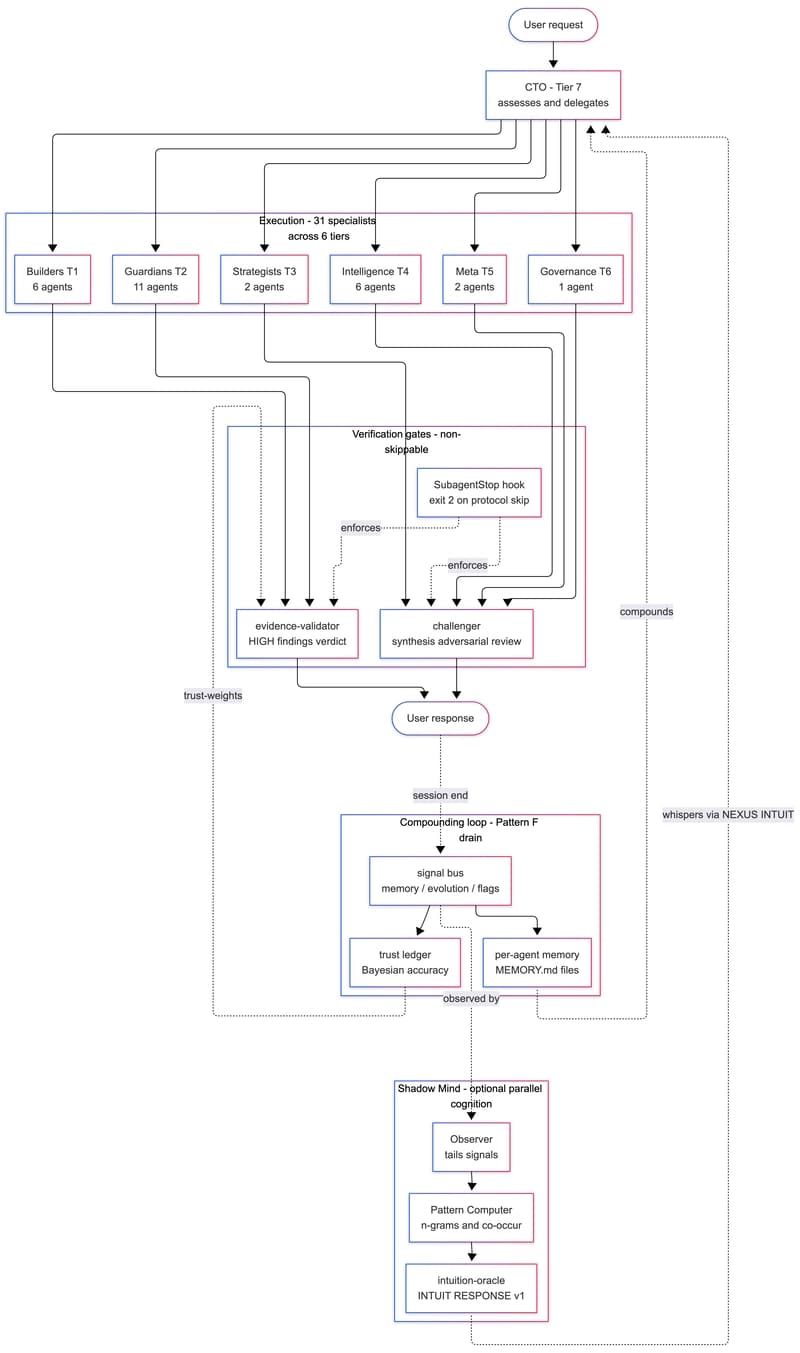
We Built a 31-Agent AI Team That Hires Itself, Critiques Itself, and Dreams
Dev.to
Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to