FlowRL: A Taxonomy and Modular Framework for Reinforcement Learning with Diffusion Policies
arXiv cs.LG / 3/31/2026
📰 NewsDeveloper Stack & InfrastructureIdeas & Deep AnalysisTools & Practical UsageModels & Research
Key Points
- The paper proposes “FlowRL,” a taxonomy that unifies reinforcement learning (RL) methods that use diffusion and flow-based policy representations, addressing the lack of an overarching framework in the field.
- It introduces a modular, JAX-based open-source codebase designed for reproducibility and rapid prototyping, using JIT compilation to enable high-throughput training.
- The authors provide standardized, systematic benchmarks across Gym-Locomotion, the DeepMind Control Suite, and IsaacLab to enable rigorous side-by-side comparisons of diffusion-based approaches.
- The work offers practical guidance for selecting appropriate diffusion/flow RL algorithms based on the target robotics application and establishes a foundation for future algorithm design in generative-model-driven robotics.
Related Articles

Black Hat Asia
AI Business

How to Verify Information Online and Avoid Fake Content
Dev.to
I built an AI code reviewer solo while working full-time — honest post-launch breakdown
Dev.to
Mobile App MVP: Build, Launch, and Validate in Under a Week
Dev.to
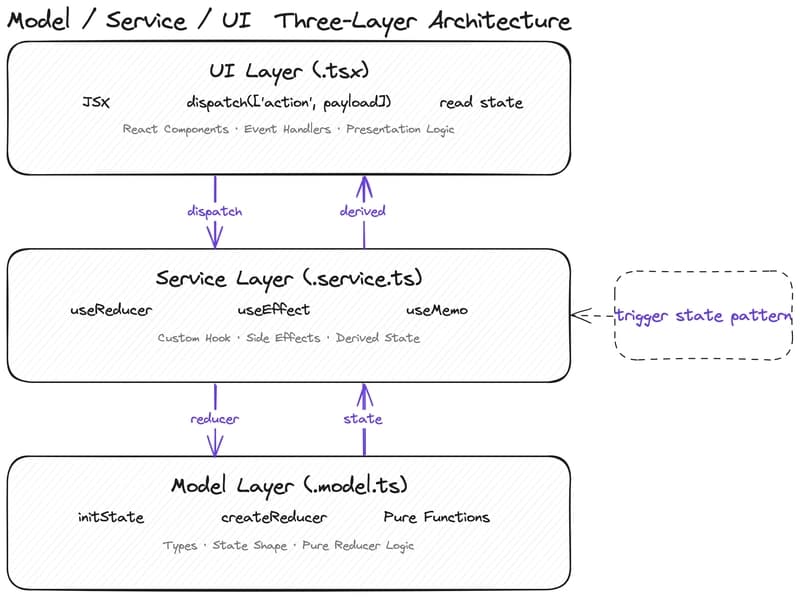
Why Your State Management Is Slowing Down AI-Assisted Development
Dev.to