HWE-Bench: Benchmarking LLM Agents on Real-World Hardware Bug Repair Tasks
arXiv cs.AI / 4/17/2026
📰 NewsModels & Research
Key Points
- The paper introduces HWE-Bench, a large-scale, repository-level benchmark for evaluating LLM agents on real-world hardware bug repair tasks, addressing a gap in prior component-only hardware benchmarks.
- HWE-Bench contains 417 task instances drawn from historical bug-fix pull requests across six major open-source projects (Verilog/SystemVerilog and Chisel), including RISC-V cores, SoCs, and security roots-of-trust.
- Each task runs in a fully containerized environment and requires agents to resolve an actual bug report, with correctness verified via the project’s native simulation and regression workflows.
- In evaluations of seven LLMs using four agent frameworks, the top agent solves 70.7% of tasks overall, but performance declines to below 65% on complex SoC-level projects despite exceeding 90% on smaller cores.
- Failure analysis attributes most agent shortcomings to three debugging stages—fault localization, hardware-semantic reasoning, and coordination across multiple artifacts spanning RTL, configuration, and verification—and suggests concrete directions for improving hardware-aware agents.
Related Articles

No Free Lunch Theorem — Deep Dive + Problem: Reverse Bits
Dev.to

Salesforce Headless 360: Run Your CRM Without a Browser
Dev.to

RAG Systems in Production: Building Enterprise Knowledge Search
Dev.to
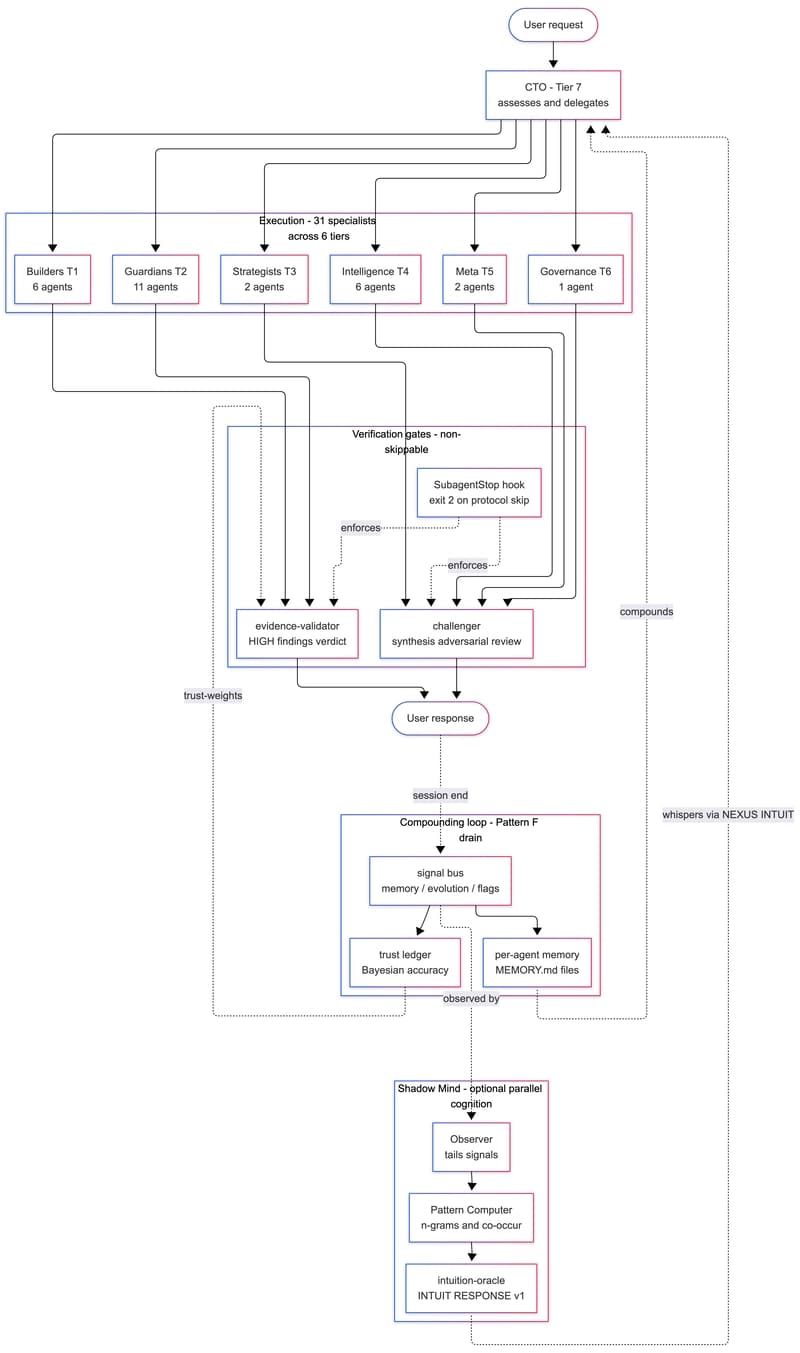
We Built a 31-Agent AI Team That Hires Itself, Critiques Itself, and Dreams
Dev.to
gpt-image-2 API: ship 2K AI images in Next.js for $0.21 (2026)
Dev.to