SODA: Semi On-Policy Black-Box Distillation for Large Language Models
arXiv cs.LG / 4/7/2026
📰 NewsIdeas & Deep AnalysisModels & Research
Key Points
- The paper introduces SODA, a semi on-policy black-box distillation method that aims to resolve the trade-off between error-correcting on-policy approaches and unstable/expensive adversarial distillation.
Related Articles

Human-Aligned Decision Transformers for satellite anomaly response operations with ethical auditability baked in
Dev.to

That Smoking-Gun Video? It's Not Evidence. It's a Suspect.
Dev.to

AI Citation Registries and Website-Based Publishing Constraints
Dev.to
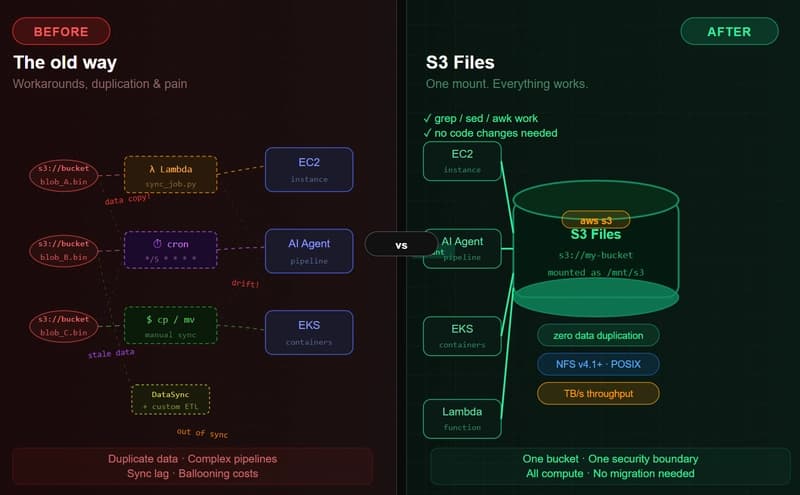
Amazon S3 Files: The End of the Object vs. File War (And Why It Matters in the AI Agent Era)
Dev.to
大模型价格战2025:谁在烧钱谁在赚?深度解析AI成本暴跌背后的生死博弈
Dev.to