26th March 2026 - Link Blog
Quantization from the ground up. Sam Rose continues his streak of publishing spectacularly informative interactive essays, this time explaining how quantization of Large Language Models works (which he says might be "the best post I've ever made".)
Also included is the best visual explanation I've ever seen of how floating point numbers are represented using binary digits.
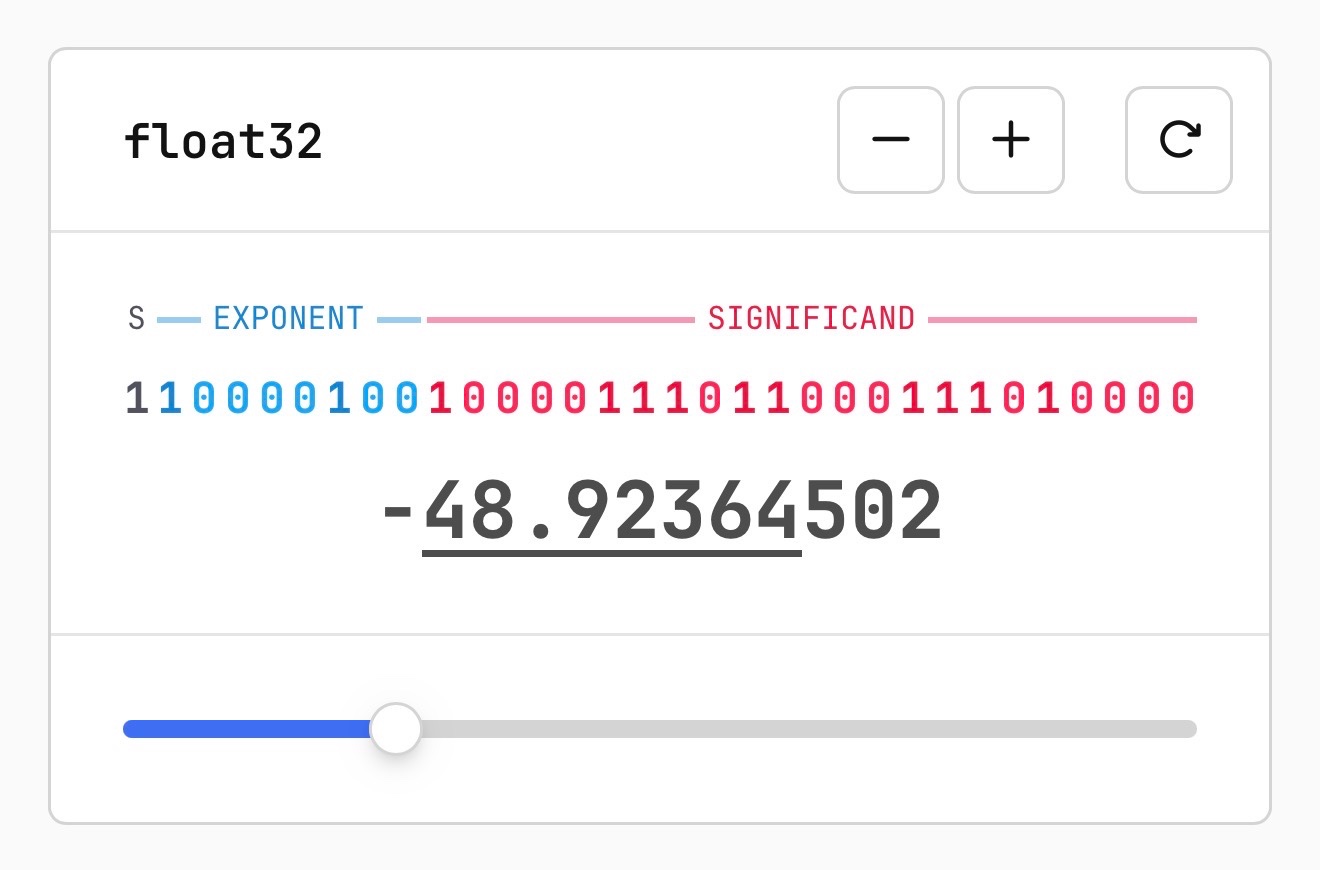
I hadn't heard about outlier values in quantization - rare float values that exist outside of the normal tiny-value distribution - but apparently they're very important:
Why do these outliers exist? [...] tl;dr: no one conclusively knows, but a small fraction of these outliers are very important to model quality. Removing even a single "super weight," as Apple calls them, can cause the model to output complete gibberish.
Given their importance, real-world quantization schemes sometimes do extra work to preserve these outliers. They might do this by not quantizing them at all, or by saving their location and value into a separate table, then removing them so that their block isn't destroyed.
Plus there's a section on How much does quantization affect model accuracy?. Sam explains the concepts of perplexity and ** KL divergence ** and then uses the llama.cpp perplexity tool and a run of the GPQA benchmark to show how different quantization levels affect Qwen 3.5 9B.
His conclusion:
It looks like 16-bit to 8-bit carries almost no quality penalty. 16-bit to 4-bit is more noticeable, but it's certainly not a quarter as good as the original. Closer to 90%, depending on how you want to measure it.
Recent articles
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026
- Thoughts on OpenAI acquiring Astral and uv/ruff/ty - 19th March 2026
This is a link post by Simon Willison, posted on 26th March 2026.
computer-science 15 ai 1932 explorables 30 generative-ai 1713 llms 1679 sam-rose 5 qwen 53Monthly briefing
Sponsor me for $10/month and get a curated email digest of the month's most important LLM developments.
Pay me to send you less!
Sponsor & subscribe