Is Cross-Lingual Transfer in Bilingual Models Human-Like? A Study with Overlapping Word Forms in Dutch and English
arXiv cs.CL / 4/9/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The study investigates whether bilingual Dutch-English causal Transformer language models show cross-lingual activation patterns similar to human bilingual readers, focusing on cognates (friends) and interlingual homographs (false friends).
- By training models under four vocabulary-sharing regimes that control whether shared (or false) friends receive shared vs language-specific embeddings, the researchers test cross-lingual effects using surprisal and embedding-similarity measures.
- The models mostly preserve language separation, and cross-lingual effects emerge primarily when embeddings for overlapping forms are shared across languages.
- When embeddings are shared, the models exhibit facilitation for both friends and false friends (relative to controls), but regression analyses suggest these behaviors are driven more by word frequency than by consistent form-to-meaning mapping.
- The human-like qualitative pattern is reproduced only in the condition where embeddings are shared for friends but not for false friends, implying that the way lexical overlap is encoded limits the models’ adequacy as explanations for bilingual reading.
Related Articles

Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Could it be that this take is not too far fetched?
Reddit r/LocalLLaMA

npm audit Is Broken — Here's the Claude Code Skill I Built to Fix It
Dev.to

Meta Launches Muse Spark: A New AI Model for Everyday Use
Dev.to
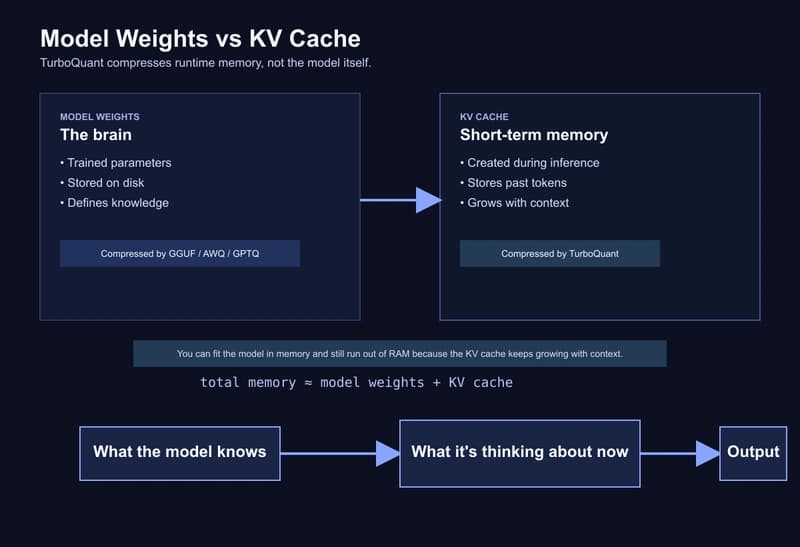
TurboQuant on a MacBook: building a one-command local stack with Ollama, MLX, and an automatic routing proxy
Dev.to