Unmasking Hallucinations: A Causal Graph-Attention Perspective on Factual Reliability in Large Language Models
arXiv cs.CL / 4/7/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The paper tackles factual hallucinations in large language models by analyzing how internal transformer attention contributes to unsupported outputs.
- It proposes a causal graph attention network (GCAN) that builds token-level graphs using self-attention weights and gradient-based influence scores to measure factual dependencies.
- The method introduces a Causal Contribution Score (CCS) to quantify how much each token causally contributes to the model’s factual reliability.
- A fact-anchored graph reweighting layer is used during generation to dynamically downweight hallucination-prone nodes.
- Experiments on TruthfulQA and HotpotQA report a 27.8% reduction in hallucination rate and a 16.4% improvement in factual accuracy versus baseline retrieval-augmented generation (RAG) models.
Related Articles

Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Could it be that this take is not too far fetched?
Reddit r/LocalLLaMA

npm audit Is Broken — Here's the Claude Code Skill I Built to Fix It
Dev.to

Meta Launches Muse Spark: A New AI Model for Everyday Use
Dev.to
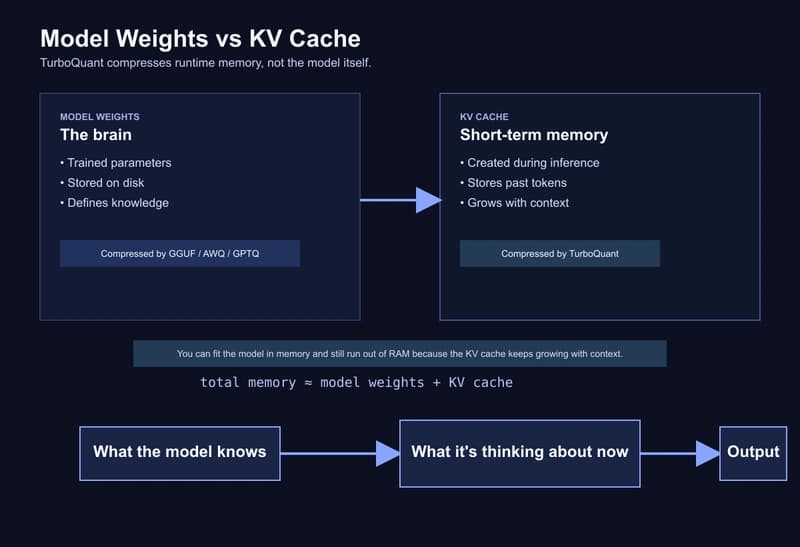
TurboQuant on a MacBook: building a one-command local stack with Ollama, MLX, and an automatic routing proxy
Dev.to