Back to Blog
2 min read
Blog
Research
Mistral Moderation API
November 7, 2024
Mistral AI team
Safety plays a key role in making AI useful. At Mistral AI, we believe that system level guardrails are critical to protecting downstream deployments.That's why we are releasing a new content moderation API. It is the same API that powers the moderation service in Le Chat. We are launching it to empower our users to utilize and tailor this tool to their specific applications and safety standards.
Over the past few months, we've seen growing enthusiasm across the industry and research community for new LLM based moderation systems, which can help make moderation more scalable and robust across applications. Our model is an LLM classifier trained to classify text inputs into 9 categories defined below. We are releasing two end-points: one for raw text and one for conversational content. Undesirable content is very specific to a given context, therefore we've trained our model to classify the last message of conversation within a conversational context. Check out our technical documentation for more information. The model is natively multilingual and in particular trained on Arabic, Chinese, English, French, German, Italian, Japanese, Korean, Portuguese, Russian, Spanish.
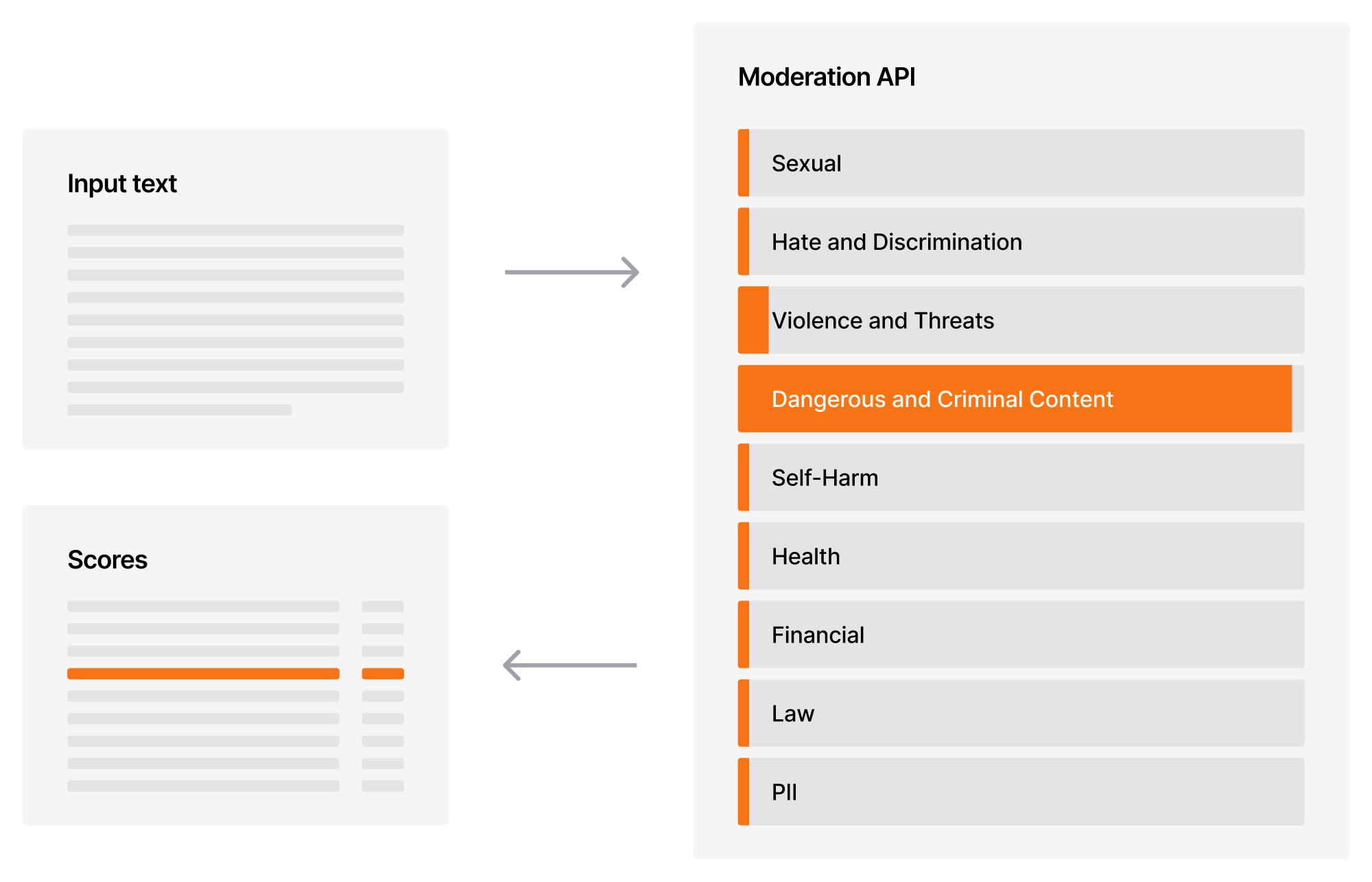
The Content Moderation classifier leverages the most relevant policy categories for effective guardrails and introduces a pragmatic approach to LLM safety by addressing model-generated harms such as unqualified advice and PII. The full set of policy definitions and details on how to get started are available in our technical documentation .
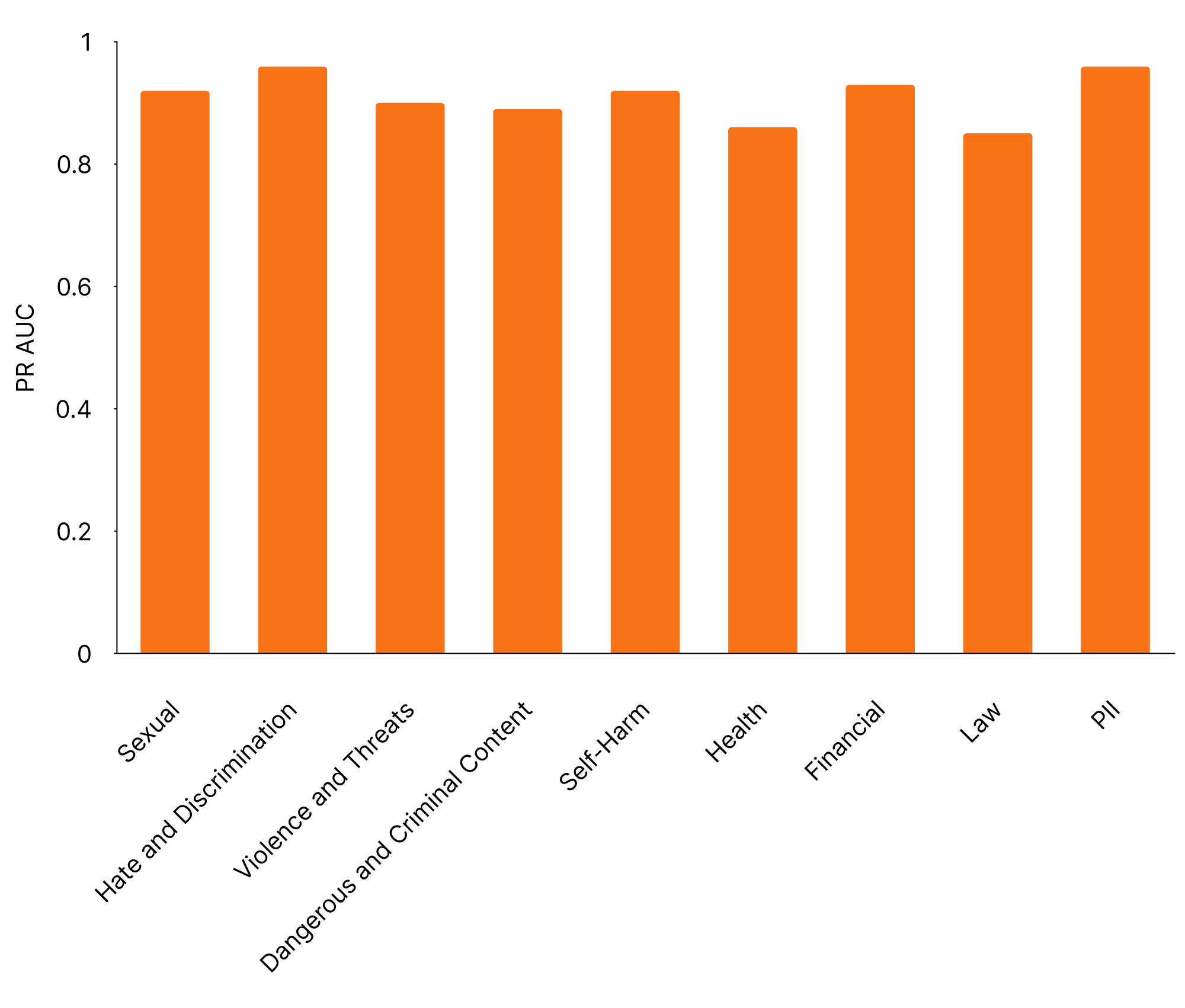
Performance
We are sharing AUC PR across policies on our internal testset below.
We're working with our customers to build and share scalable, lightweight and customizable moderation tooling, and will continue to engage with the research community to contribute safety advancements to the broader field.
0%


![Kept context-switching between arxiv, OpenReview, GitHub, and HuggingFace for every paper, so I built this. Chrome extension + website with everything inline, plus citation graph + SPECTER2 neighbors. 3M papers, free, feedback welcome [P]](/_next/image?url=https%3A%2F%2Fpreview.redd.it%2F4apvcyd00w3h1.png%3Fwidth%3D140%26height%3D71%26auto%3Dwebp%26s%3D8123adc49485c56f1d2077e98aec74f2e306b23f&w=3840&q=75)

