 | Built this beautiful monstrosity to satisfy my mental illness. Running gptoss 120b at 90t/s, qwen 3.5 35b a3b at 80 t/s. This node is running host for my RPC mesh with the two 64gb orin dev kits [link] [comments] |
Newest GPU server in the lab! 72gb ampere vram!
Reddit r/LocalLLaMA / 3/19/2026
📰 NewsDeveloper Stack & InfrastructureModels & Research
Key Points
- A new GPU server with 72 GB Ampere VRAM was built in the lab to support large AI models.
- It is reportedly running gptoss 120b at 90t/s and qwen 3.5 35b a3b at 80 t/s.
- The node serves as the host for an RPC mesh with two 64 GB Orin development kits.
- The post was submitted by /u/braydon125 on Reddit's LocalLLaMA and links to a video.
Related Articles

5 Dangerous Lies Behind Viral AI Coding Demos That Break in Production
Dev.to
Two bots, one confused server: what Nimbus revealed about AI agent identity
Dev.to

OpenTelemetry just standardized LLM tracing. Here's what it actually looks like in code.
Dev.to
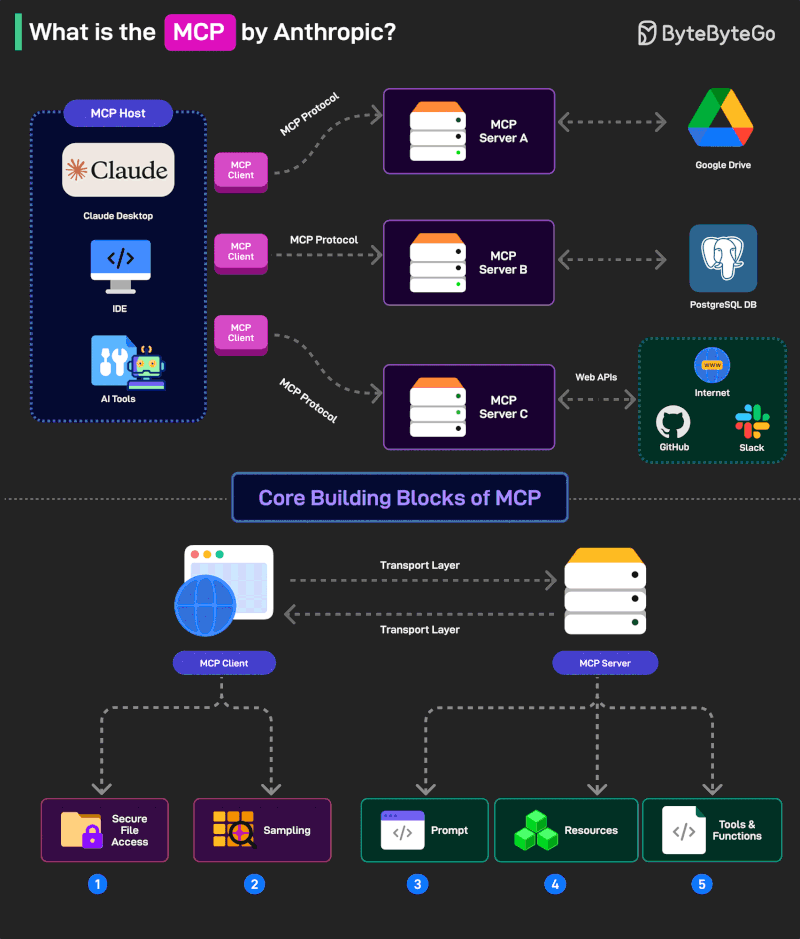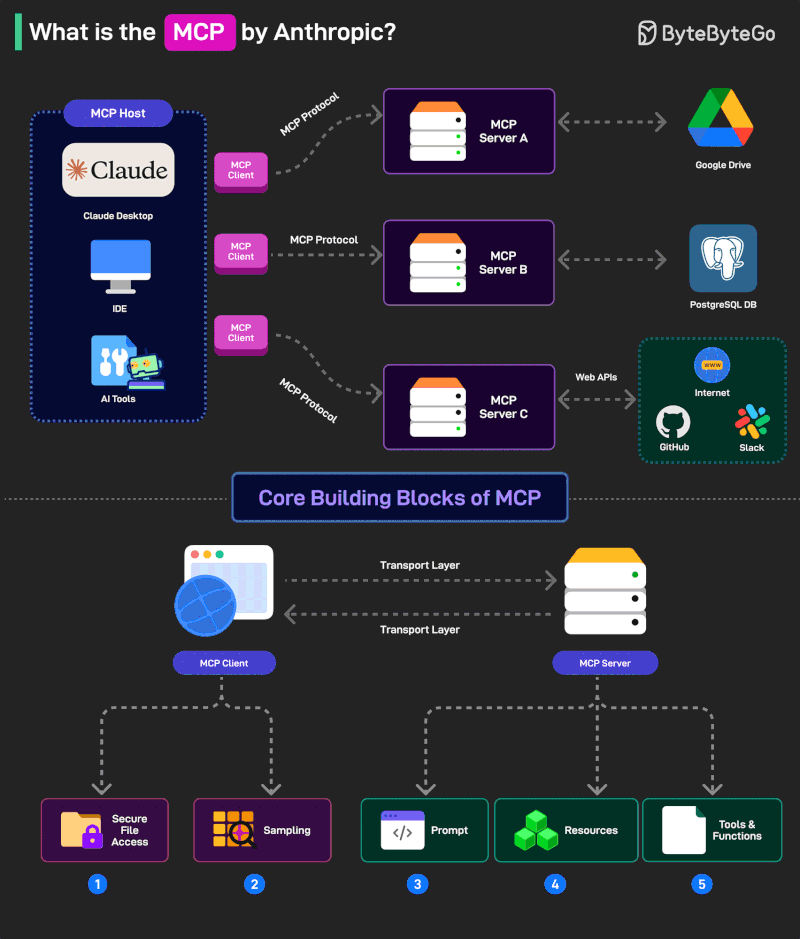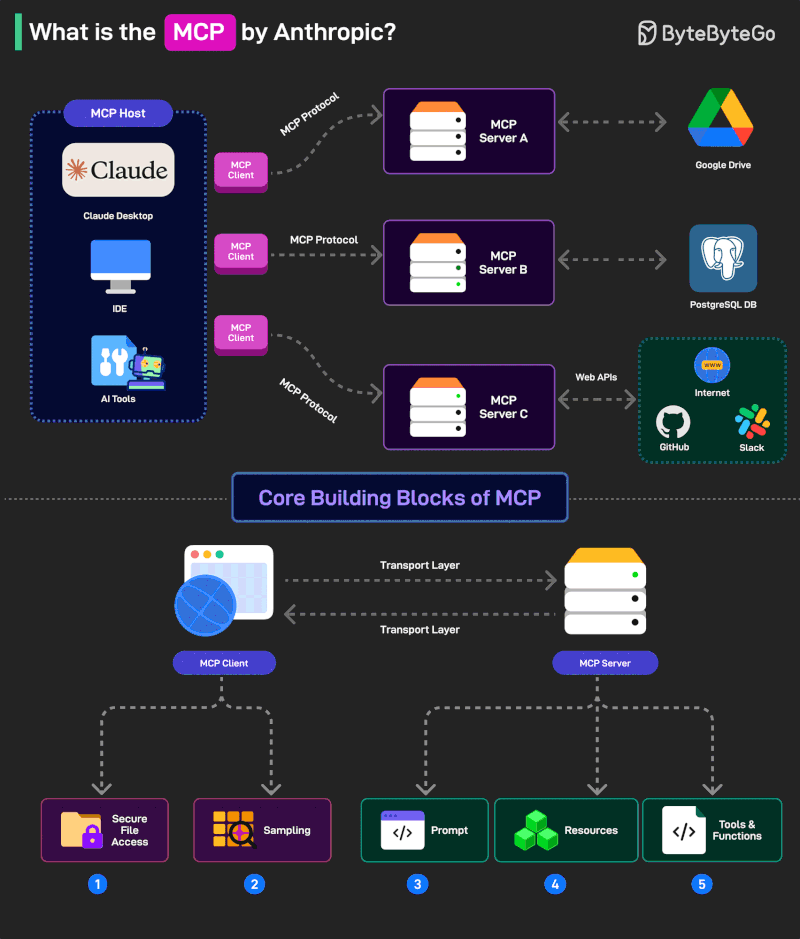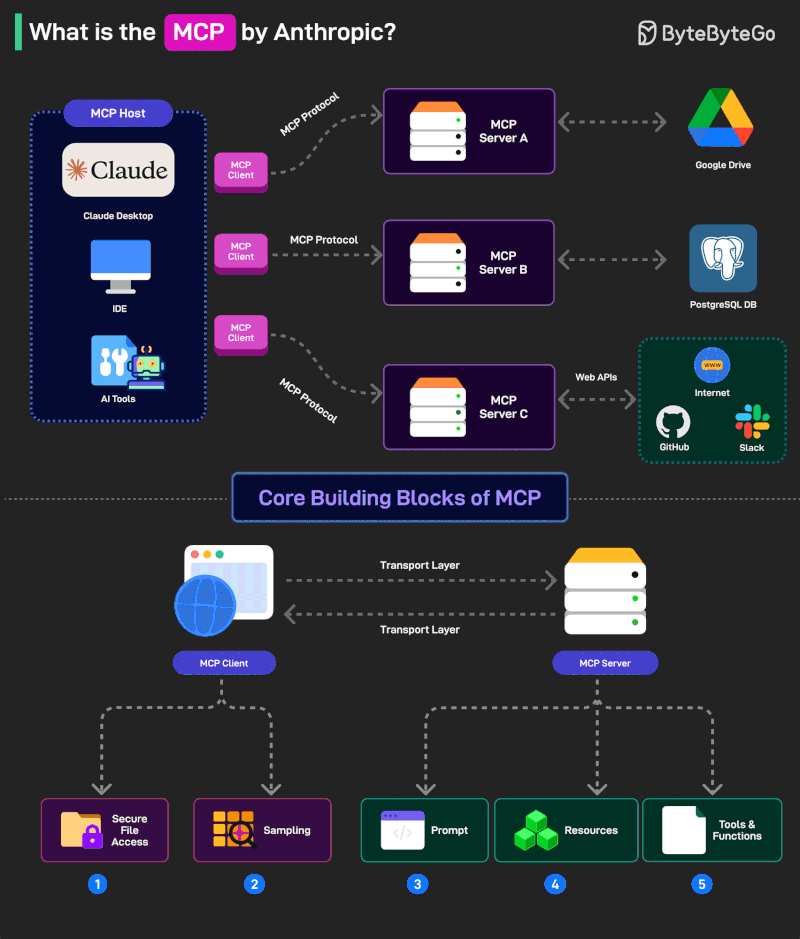
What is MCP?
Dev.to
PIXIU: A Large Language Model, Instruction Data and Evaluation Benchmark forFinance
Dev.to