【Python奮闘記】SVMとLightGBMで挑む内向型予測― モデルの誤判定データから学んだこと ―
Qiita / 3/18/2026
💬 OpinionTools & Practical UsageModels & Research
Key Points
- SVMとLightGBMを用いてKaggleのExtrovert vs. Introvert Behavior Dataを対象に内向型/外向型予測に挑戦し、モデルの誤判定データから貴重な学びを得た。
- 前回のアイリスデータセット分類で100%の正解率を達成した経験がある著者が、より現実的で人間味のあるデータへ挑戦している。
- データ前処理・特徴量設計・モデル選択の意味を検討し、誤判定ケースから得られた洞察を重視した実践的な学習を共有している。
- 記事にはPython、機械学習、scikit-learn、Kaggleといったタグがあり、実務的な使い方・実験の記録としての性格が強い。
はじめに
19歳の大学生です。
前回、アヤメの分類で正解率100%を出せて満足していた私ですが、今回はより実践的で、より「人間味」のあるデータに挑みたいと思い、kaggleの「Extrovert vs. Introvert Behavior Data」に挑戦してみました。...
Continue reading this article on the original site.
Read original →Related Articles
Two bots, one confused server: what Nimbus revealed about AI agent identity
Dev.to
How to Create a Month of Content in One Day Using AI (Step-by-Step System)
Dev.to

OpenTelemetry just standardized LLM tracing. Here's what it actually looks like in code.
Dev.to
🌱 How AI is Transforming Planting — and Why It Matters
Dev.to
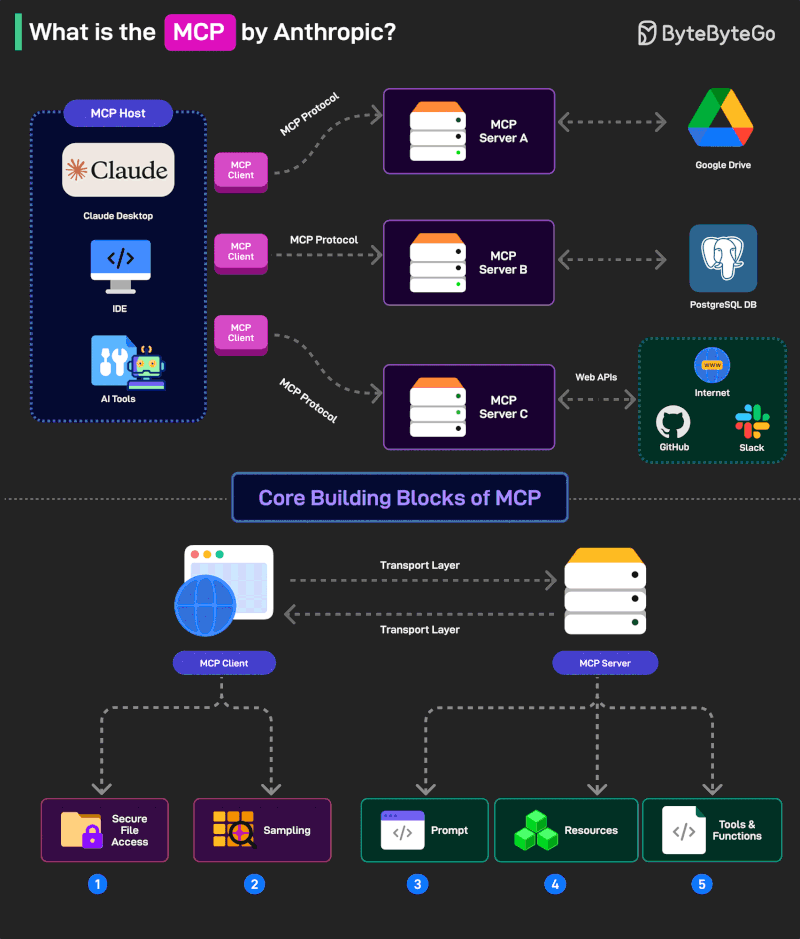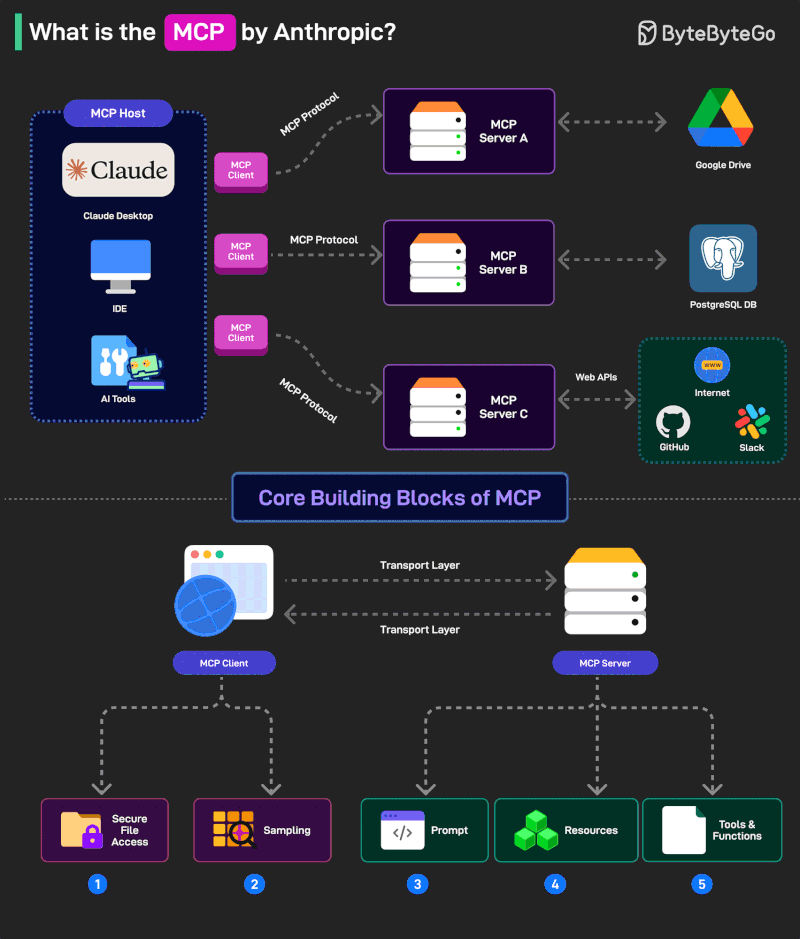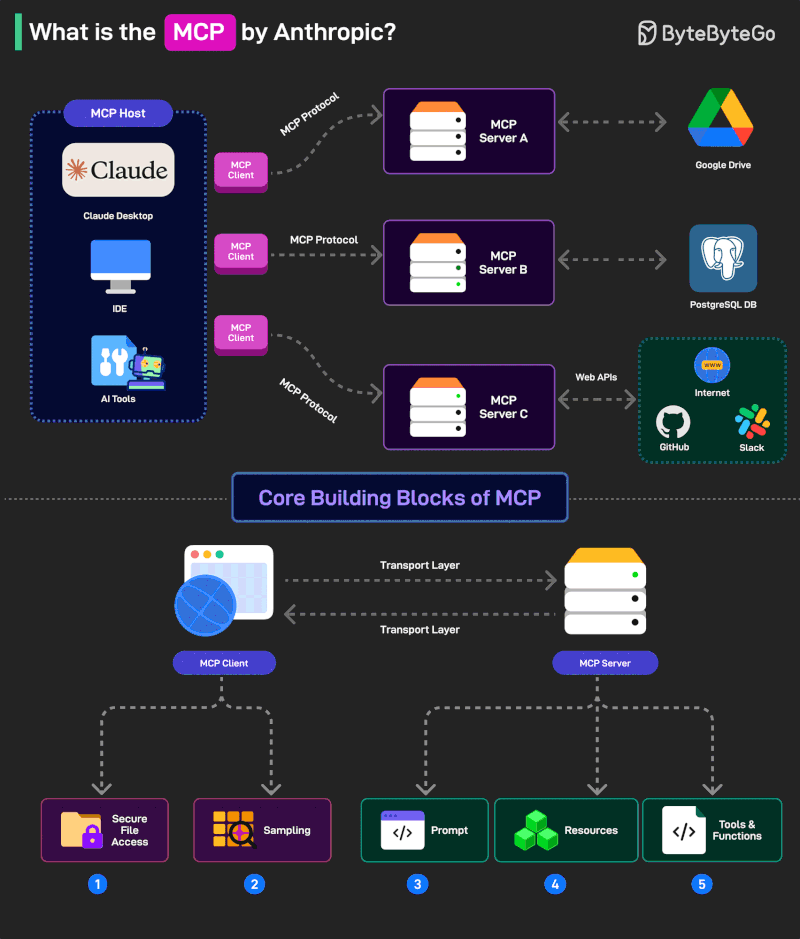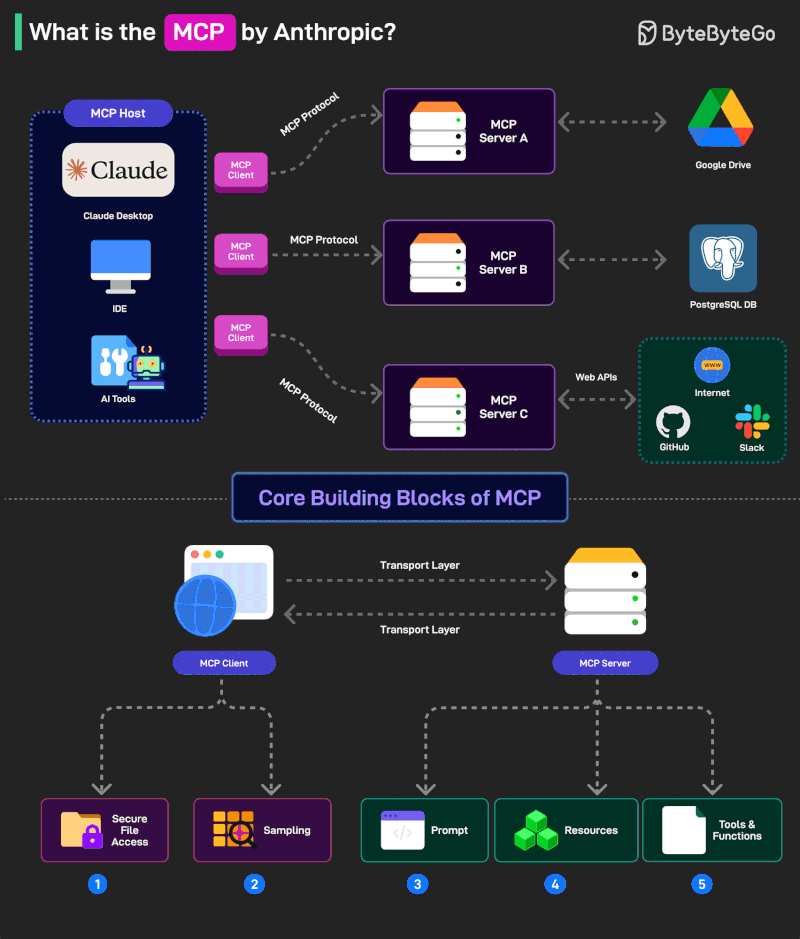
What is MCP?
Dev.to