 | For my startup, I needed to extract structured data (item name, price, quantity, unit cost) from photos of receipts and from product images on the shelf; faded thermal paper, crumpled, bad lighting, the works. Key findings after thousands of test receipts:
Happy to share more specifics on prompt design if anyone's working on similar problems. [link] [comments] |
I used Gemini 2.5 Flash to parse receipts at scale. Here's what I learned about multimodal OCR in production
Reddit r/artificial / 5/6/2026
💬 OpinionDeveloper Stack & InfrastructureTools & Practical UsageModels & Research
Key Points
- The author built a production workflow to extract structured receipt data (item name, price, quantity, unit cost) from messy real-world inputs, including thermal paper photos and shelf product images.
- They found that single-pass multimodal extraction (OCR + structuring in one call) outperformed common two-step pipelines that use a vision OCR stage followed by a separate language structuring stage.
- Their results emphasize that prompt design—especially requesting strict JSON with well-defined fields—improved extraction quality more than simply using a larger model.
- Thermal paper fading was identified as the hardest edge case, causing the most hallucinations, with ongoing work to mitigate it.
- They report a practical cost/quality tradeoff: Gemini 2.5 Flash correctly handles about 95% of receipts, while Gemini Pro is better for complex layouts and handwriting, making model routing worthwhile.
Related Articles

Black Hat USA
AI Business

Transform Your Blurry Photos into HD Masterpieces, Instantly!
Dev.to

6 New Moats for AI Agent Infrastructure — Trust Score, Deployment, SLA, Identity, Compliance-as-Code
Dev.to

Google Home’s Gemini AI can handle more complicated requests
The Verge
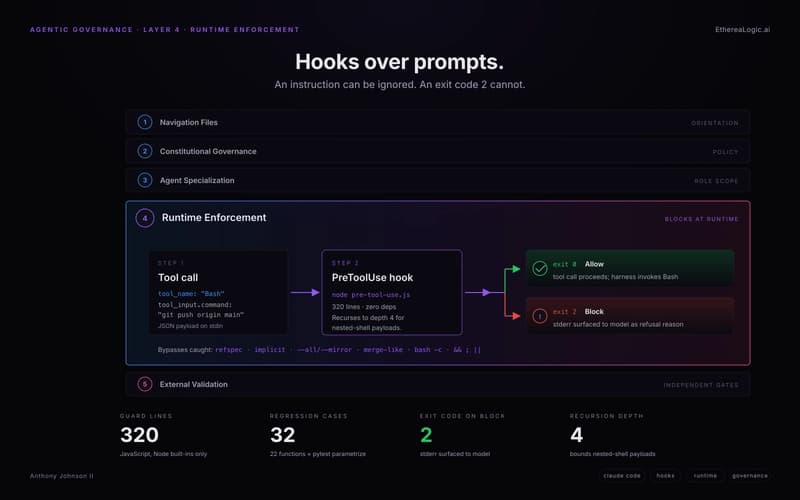
Exit Code 2: How Claude Hooks Turn Agentic Rules Into Runtime Barriers
Dev.to