MApLe: Multi-instance Alignment of Diagnostic Reports and Large Medical Images
arXiv cs.CV / 4/16/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The paper introduces MApLe, a vision-language alignment method designed for diagnostic reports that reference both anatomy and subtle image findings.
- It tackles a key limitation of standard vision-language models by using multi-task, multi-instance patch-wise alignment to link small image regions to relevant sentences in free-text reports.
- MApLe separates anatomical region concepts from diagnostic finding concepts, using a text embedding and an image encoder conditioned on anatomical structures.
- Experiments on multiple downstream tasks show improved alignment performance over state-of-the-art baseline models.
- The authors provide implementation code via the linked GitHub repository.
Related Articles

The AI Hype Cycle Is Lying to You About What to Learn
Dev.to

Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Inside NVIDIA’s $2B Marvell Deal: What NVLink Fusion Means for AI Ethernet Fabrics
Dev.to

Automating Your Literature Review: From PDFs to Data with AI
Dev.to
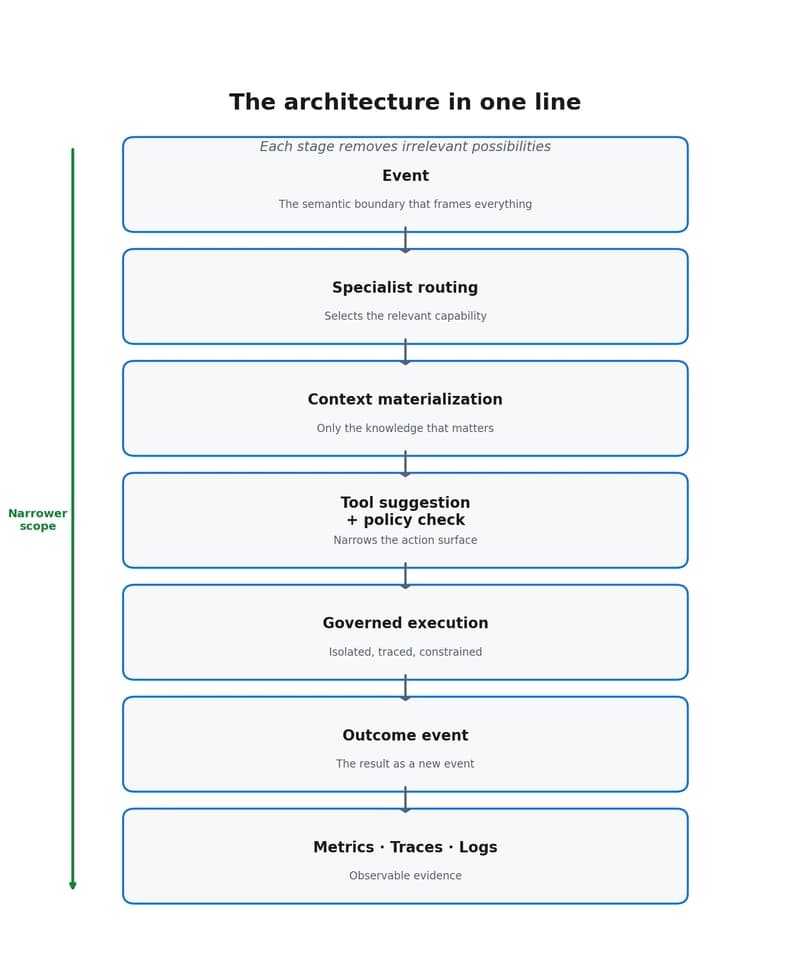
Why event-driven agents reduce scope, cost, and decision dispersion
Dev.to