Adaptive Action Chunking at Inference-time for Vision-Language-Action Models
arXiv cs.RO / 4/7/2026
📰 NewsIdeas & Deep AnalysisModels & Research
Key Points
- The paper highlights a key limitation of Vision-Language-Action (VLA) robotics: fixed action-chunk sizes at inference-time trade off responsiveness to new information against consistency across tasks.
- It proposes Adaptive Action Chunking (AAC), which uses action entropy from current predictions to dynamically choose the chunk size during inference.
- The authors report extensive experimental results across both simulated and real-world robotic manipulation tasks, showing substantially improved performance over state-of-the-art baselines.
- The work includes publicly available videos and source code, enabling further evaluation and replication by the community.
Related Articles

Human-Aligned Decision Transformers for satellite anomaly response operations with ethical auditability baked in
Dev.to

That Smoking-Gun Video? It's Not Evidence. It's a Suspect.
Dev.to

AI Citation Registries and Website-Based Publishing Constraints
Dev.to
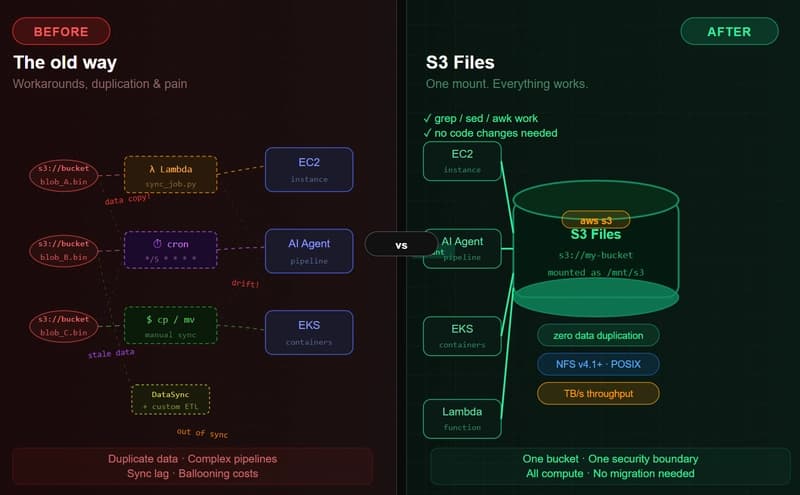
Amazon S3 Files: The End of the Object vs. File War (And Why It Matters in the AI Agent Era)
Dev.to
大模型价格战2025:谁在烧钱谁在赚?深度解析AI成本暴跌背后的生死博弈
Dev.to