正確性評価がLLMのハルシネーションを招く:Nature掲載論文が暴くインセンティブ構造
Zenn / 5/5/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- Nature掲載の研究が、LLMの「正確性評価」の設計・運用によっては、ハルシネーション(もっともらしい誤り)をむしろ誘発するインセンティブ構造になり得る点を指摘している。
- 評価指標や採点方法が、モデルに対して「正しさよりも高スコアを取る」行動を促す形に歪む可能性があることが論点となっている。
- その結果、評価しているはずの仕組みが、生成内容の品質改善ではなく誤情報の定着・増加に寄与してしまうリスクがある。
- 今後は評価プロトコル(データ、指標、報告設計、報酬/フィードバックの与え方)を再点検し、ハルシネーションを抑える方向へ設計を見直す必要が示唆されている。
正確性評価がLLMのハルシネーションを招く:Nature掲載論文が暴くインセンティブ構造
"ハルシネーションはミステリアスな現象ではない。現在の訓練・評価手順の必然的な産物だ。"
— Kalai, Nachum, Vempala, Zhang (OpenAI × Georgia Tech)
2026年4月、Natureに掲載された論文 "Evaluating large language models for accuracy incentivizes hallucinations" は、LLM研究コミュニティに衝撃を与えた。OpenAIのAdam Tauman Kalai氏と、...
Continue reading this article on the original site.
Read original →Related Articles

Transform Your Blurry Photos into HD Masterpieces, Instantly!
Dev.to

6 New Moats for AI Agent Infrastructure — Trust Score, Deployment, SLA, Identity, Compliance-as-Code
Dev.to

There will still be art in software
Dev.to

Google Home’s Gemini AI can handle more complicated requests
The Verge
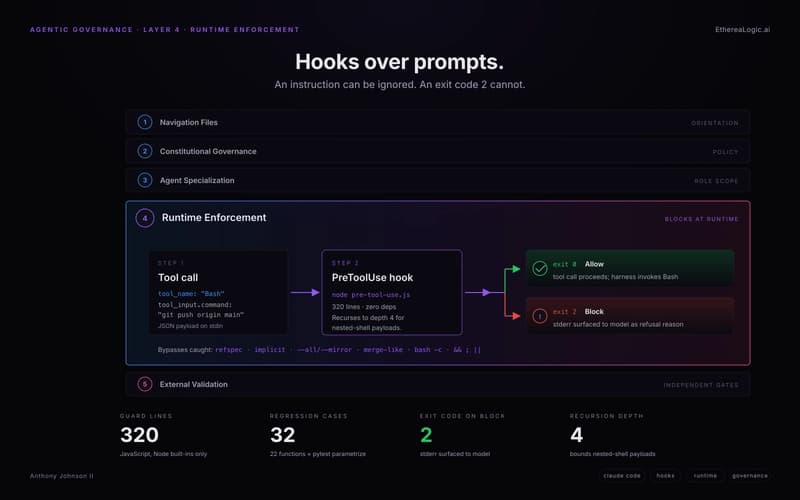
Exit Code 2: How Claude Hooks Turn Agentic Rules Into Runtime Barriers
Dev.to