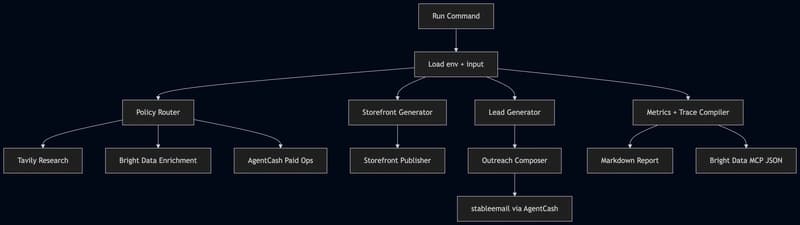
In this tutorial, we walk through MolmoAct step by step and build a practical understanding of how action-reasoning models can reason in space from visual observations. We set up the environment, load the model, prepare multi-view image inputs, and explore how MolmoAct produces depth-aware reasoning, visual traces, and actionable robot outputs from natural language instructions. […]
The post A Coding Implementation of MolmoAct for Depth-Aware Spatial Reasoning, Visual Trajectory Tracing, and Robotic Action Prediction appeared first on MarkTechPost.