Document-Level Numerical Reasoning across Single and Multiple Tables in Financial Reports
arXiv cs.CL / 4/7/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The paper argues that while LLMs are strong at language understanding, they still struggle with reliable numerical QA over long, structured financial documents, especially when evidence must be combined across multiple tables and text.
- It introduces FinLongDocQA, a new dataset covering both single-table and cross-table document-level numerical reasoning in long-context financial annual reports.
- The evaluation finds two key bottlenecks for current LLMs: many annual reports exceed 129k tokens (making relevant table retrieval harder due to context rot) and multi-step arithmetic remains error-prone even after evidence is found.
- To improve reliability, the authors propose FinLongDocAgent, a Multi-Agent, Multi-Round RAG system that iteratively retrieves evidence, executes intermediate calculations, and verifies results across multiple rounds.
- Experiments emphasize that iterative retrieval combined with verification can substantially improve accuracy for numerical QA in long financial documents.
Related Articles

Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Could it be that this take is not too far fetched?
Reddit r/LocalLLaMA

npm audit Is Broken — Here's the Claude Code Skill I Built to Fix It
Dev.to

Meta Launches Muse Spark: A New AI Model for Everyday Use
Dev.to
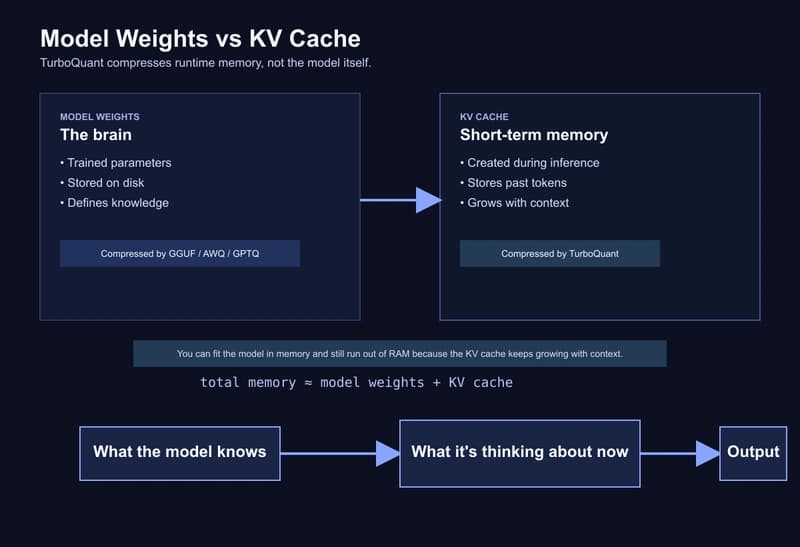
TurboQuant on a MacBook: building a one-command local stack with Ollama, MLX, and an automatic routing proxy
Dev.to