
生成AIは、日本文化をよく学習している?

今回の研究は、国や地域によって異なる「家族生活を形作る価値観はなにか」「日常的に食べられている料理は何か」「どのような映画産業が存在するか」といった質問を大規模言語モデル(以下、LLM)に対して行い、LLMがどの国や地域の文化を選択するのかを検証したものになります。
研究の方法
1. 新しいデータセット「CROQ」
CROQは、「Culture-Related Open Questions」の略です。
さまざまな文化に関する開いた質問を集めたデータセットで、11の大分類、66のサブトピック(各サブトピックごとに20問)の合計1,320問が24種類の言語に翻訳され、最終的に31,680問となっています。
11の大分類には、信念、価値観、日常生活、教育、芸術、食文化、地理、政治、健康、メディア、歴史、経済などの要素が含まれており、幅広くカバーされていることがわかります。
2. 質問の仕方
著者らは、質問の本文に特定の国名や地域名が含まれないように注意しています。
具体的には、「ある地域・場所において、家族生活を形づくる価値観は何ですか。短く答えてください。場所は自分で選んでください」といった質問の仕方をして、どこの文化について答えるかはLLMが決める設計になっています。
この仕組みにより、LLM内部の文化的な優先順位や地域的なバイアスが見えやすくなります。
3. 評価
著者らは、8種類のLLMに対して24種類の言語で質問を入力し、出力された回答に含まれる国や地域を分析しています。
加えて、自由回答の中から国名や地域名を抽出するために別のLLMを判定器として使い、回答に含まれる国や地域を最大5つまで抽出しています。
ただし、LLMの抽出した内容に明らかな誤りが存在する可能性もあるため、著者らは抽出された回答のうち264個を人間の目で確認しています。
その結果、簡単なチェックでは平均98.48%、より厳しいチェックでも平均95.08%の正確さだったと報告されています。
結果
1. LLMの出力は、入力言語の「公用国」の文化に寄りやすいが…
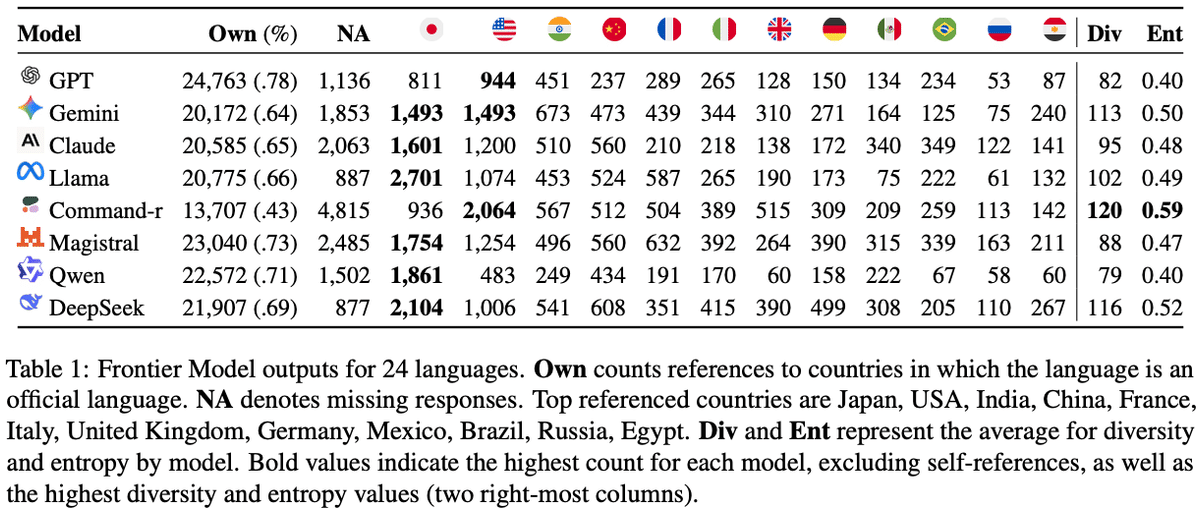
Fernandez de Landa, J., Perez-Almendros, C., & Camacho-Collados, J. (2026). Why are all LLMs obsessed with Japanese culture? On the hidden cultural and regional biases of LLMs.
検証の結果、LLMは入力された言語が公用語として使われている国に関する回答を非常に多く出すことが示唆されました。
例えば、日本語で質問すると日本の、フランス語で質問するとフランスやカナダに関連する方向にモデルが回答する傾向があったということです。
一方で、入力言語が公用語として使われている国への参照(以下、自己参照)を除いた場合、多く登場したのは日本、アメリカ、インド、中国、フランスでしたが、特に日本は、8モデル中6モデルで自己参照を除いた最頻出国となっていることが示されました。
つまり、英語で聞けばアメリカに関連する文化の回答が、中国語で聞けば中国に関連する文化の回答が非常に多く出力されますが、このような「入力言語が公用語として使われている国」を除いた場合に出現する外国の文化の代表として、日本がほぼ全ての言語において最も多く登場した、ということです。
著者らはこの結果を、従来の欧米・英語圏中心のバイアスとは異なる地域的バイアスとして位置づけています。
2. トピック別の傾向を見ても、日本とアメリカは目立っていた

Fernandez de Landa, J., Perez-Almendros, C., & Camacho-Collados, J. (2026). Why are all LLMs obsessed with Japanese culture? On the hidden cultural and regional biases of LLMs.
全体として、日本とアメリカは多くのトピックで目立っていますが、トピックによって以下のような違いがあることが論文中で指摘されています。
地理や経済では、アメリカが日本を上回る傾向
政治と歴史では、日本は3位または4位に下がる
信念ではギリシャが2位に
政治では中国が2位に
歴史ではフランスが2位に
メディアとエンターテインメントでは韓国が3位に
これは、モデルが文化のカテゴリごとに異なる「代表的な国のイメージ」を持っている可能性を示唆しています。
3. 高リソース言語による入力ほど、多様な国が現れる
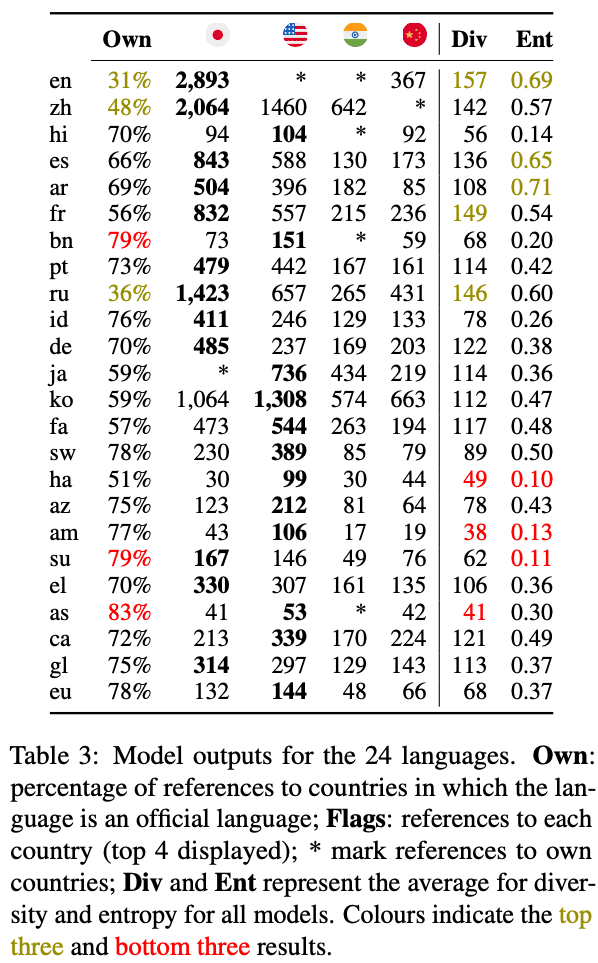
Fernandez de Landa, J., Perez-Almendros, C., & Camacho-Collados, J. (2026). Why are all LLMs obsessed with Japanese culture? On the hidden cultural and regional biases of LLMs.
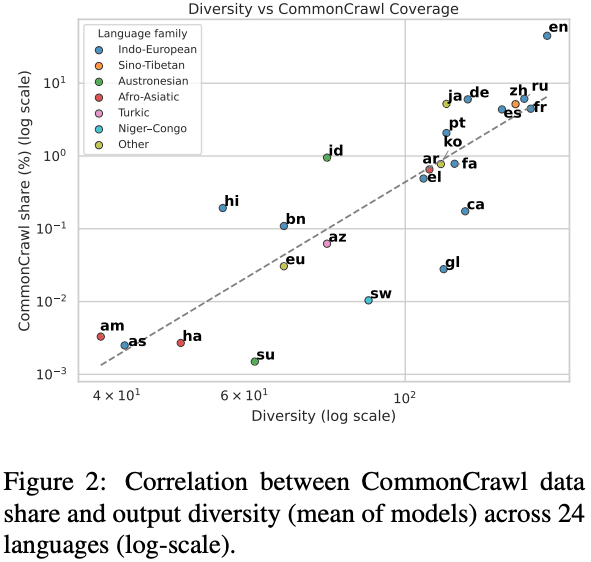
Fernandez de Landa, J., Perez-Almendros, C., & Camacho-Collados, J. (2026). Why are all LLMs obsessed with Japanese culture? On the hidden cultural and regional biases of LLMs.
高リソース言語(インターネット上や学習データに情報が多い言語)、例えば英語、中国語、スペイン語、フランス語、ロシア語などでは、出力される国や地域の多様性が高い傾向がありましたが、逆に低リソース言語では、自国や自地域への参照が強くなる傾向がありました。
実際、言語別のデータ量と回答の多様性の間には強い正の相関(Spearmanの順位相関 rs = 0.843、p < 0.001)が確認されており、学習データに多く含まれる言語ほどLLMは多様な文化的回答をしやすく、学習データに含まれる割合が少ない言語ほど回答が自国の文化に固定されやすいということになります。
4. 文化的バイアスは、事後学習で強まる可能性がある
著者らは、英語のBaseモデルと英語のInstruction-tunedモデルを比較して、文化的バイアスの差を検証しました。
Baseモデルは、主に次の単語を予測するように学習された基盤モデルで、Instruction-tunedモデルは、人間の指示にうまく答えられるように追加で調整(事後学習)されたモデルです。
その結果、Baseモデルではアメリカ、日本、インド、中国、ヨーロッパ諸国など、比較的広い範囲が参照されていましたが、Instruction-tunedモデルでは、日本やアメリカなどの少数の国への集中が強くなりました。
さらに、OLMoというモデルに関して、学習過程を、Base→SFT→Instructionの3段階に分けて調べたところ、大きな変化が起きたのはSFT(人間が用意した「よい回答例」を使って、LLMをさらに訓練する工程)でした。このSFTのあと、LLMの回答はアメリカや日本などの情報を参照しやすくなったと報告されています。
その後の調整によって、このバイアスは少し弱まる場合もありましたが、最初のBaseモデルのような多様な状態には戻りませんでした。
ゆえに、人間の指示にうまく答えられるようにLLMを訓練する過程で、特定の文化や国のイメージが強まりすぎる可能性があることが示唆されました。
注意点
BaseモデルとInstruction-tunedモデルの比較は英語のみです。そのため、事後学習によるバイアスの増加が他言語でも同様に起きるとは限りません。
Temperatureやtop-pなどのパラメータを変えた場合、結果が変わる可能性があります。
なぜ日本文化が登場する?
今回の論文では、なぜ「日本が、8モデル中6モデルで自己参照を除いた最頻出国になったのか」に関しては具体的に考察されていませんが、16の国・地域、13言語にまたがる日常文化の知識を評価するためのデータセット「BLEnD」を提案している論文では、「インターネット上に情報がたくさんある文化については答えやすい一方で、情報が少ない言語や、あまりネット上で紹介されていない文化については、うまく答えられない」ことが示唆されています [1] 。
これまで日本文化は、アニメ、漫画、ゲーム、日本食、観光、伝統文化などを通じて、海外向けに広く発信されてきました。Cool Japan政策では、食、アニメ、ポップカルチャー、伝統工芸、観光地などが「海外から見て魅力的な日本」として位置づけられています [2] 。
また、観光に関する研究でも、アニメが日本旅行への関心や動機に関わることが示唆されており、外国人が日本に関心を持つ入口の一つとして扱われていると述べられています [3] 。
こういった背景もあり、もしかしたらLLMの学習のプロセスにおいても、日本は「文化的な例」として目立ちやすかったのかもしれません。
今でこそ「日本の調剤薬局」を反映してくれますが
まだChatGPTにGPT-3.5が乗っかっていた時代の話ですが、「薬局」に関して質問すると、大体アメリカの事情を反映した回答になっていたことを思い出しました。
当時ChatGPTをあまり使っていなかった私は、「ChatGPTは、薬局でどのように役に立ちますか?」といった質問をした事があるのですが、その時返ってきた回答は、
PBM・保険請求拒否への対応文案作成
PBM監査・書類対応の整理
一般的なワクチン・検査サービスの案内文作成
このようなものでした。
日本の調剤薬局の事情とは大きく異なっていることがわかりますね。
今ではそのようなことはほぼなくなったと思いますが、この例のように、生成AIの回答は「自分の普段生活している文化圏とは異なる文化圏の事情を反映している」可能性があることは、頭にとどめておいたほうが良いでしょう。
一般論は、万人にとって適切であるとは限らない
今回の研究の示唆によると、日本語で生成AIを使う日本人ユーザーは、生成AIの出力する「一般論」に対して違和感を覚えることが少ない可能性があります。
なぜなら、LLMは入力言語の公用国に関連する回答を出力しやすく、日本語入力では日本文化に寄った回答になりやすいためです。
ただし、その一般論は日本人全体に適合するわけではありません。
地域や世代が変われば、「一般的」の基準が変わりますし、同じ地域や世代の人々であっても、個人が育ってきた環境や見てきたことによって更に差が生まれます。
ゆえに、生成AIが「一般的に〜」と断って何かを出力したとしても、その内容が一般的かどうかを見るのではなく、内容が客観的に見て正確か、そして指示した内容に対して適切な回答になっているかを、自分の責任のもと確認するようにしましょう。
一般的であることは、適切な内容であることを保証するものではありません。
参考資料
[1] Myung, J et al. (2024). BLEnD: A benchmark for LLMs on everyday knowledge in diverse cultures and languages. Advances in Neural Information Processing Systems, 37.
[2] Cabinet Office, Government of Japan. (2019). Cool Japan Strategy.
[3] Agyeiwaah, E., Suntikul, W., & Li, Y. (2019). “Cool Japan”: Anime, soft power and Hong Kong Generation Y travel to Japan. Journal of China Tourism Research.
最後までお読みいただき、ありがとうございました。
Webサイト「薬剤師のためのAIノート」も、是非ご覧ください。
記事に関する内容以外のお問い合わせは、以下のフォームよりお願いいたします。
また、書籍「超知能時代の調剤薬局」発売中です。
Kindle Unlimited会員の方は無料で読むことができます。