EGAD: Entropy-Guided Adaptive Distillation for Token-Level Knowledge Transfer
arXiv cs.CL / 5/5/2026
📰 NewsModels & Research
Key Points
- The paper proposes EGAD, an entropy-guided adaptive knowledge distillation method to improve token-level knowledge transfer from a large LLM teacher to a smaller student model.
- EGAD addresses a key weakness in prior distillation approaches by treating tokens differently according to their contribution, using the teacher’s output entropy to drive training.
- It introduces a token-level curriculum that shifts attention from low-entropy tokens to high-entropy tokens during training, plus an entropy-based adjustment of the distillation temperature to reflect the teacher’s confidence.
- The method uses a dual-branch architecture that performs logits-only distillation for easier tokens while applying deeper feature-based distillation for harder tokens, improving efficiency and learning effectiveness.
- The authors report extensive experiments showing that EGAD is both sound and effective compared with existing distillation strategies.
Related Articles

Singapore's Fraud Frontier: Why AI Scam Detection Demands Regulatory Precision
Dev.to
From OOM to 262K Context: Running Qwen3-Coder 30B Locally on 8GB VRAM
Dev.to

Nano Banana Pro vs DALL-E 3 vs Midjourney: A Practical Comparison From Someone Who Actually Uses All Three
Dev.to
LLMs edited 86 human essays toward a semantic cluster not occupied by any human writer [D]
Reddit r/MachineLearning
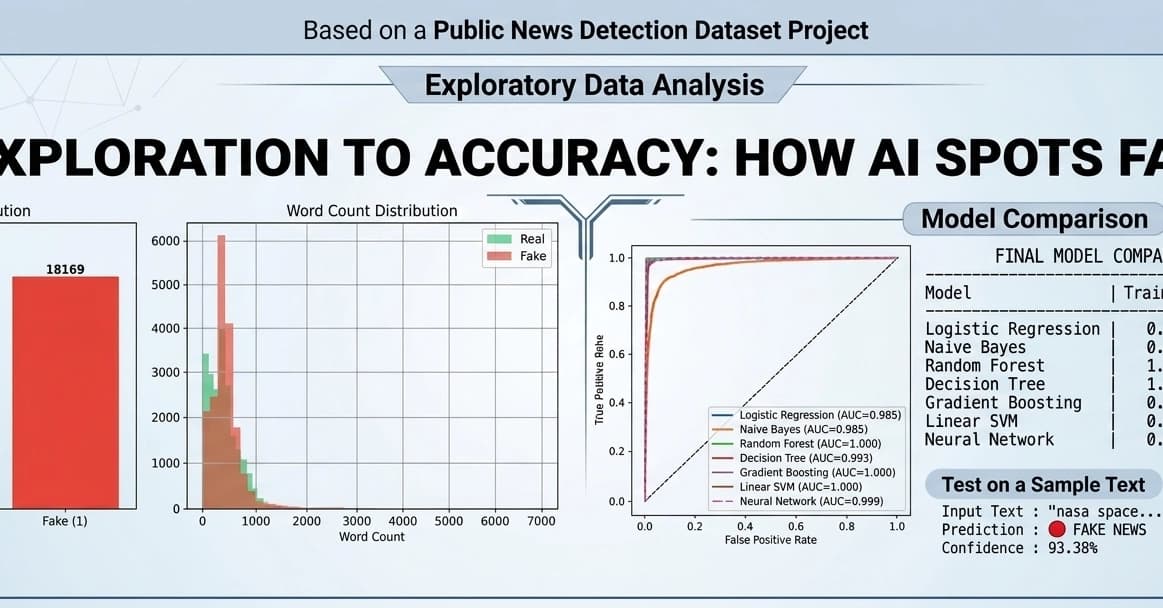
Fake News Detection using Machine Learning & NLP!
Dev.to