HORNet: Task-Guided Frame Selection for Video Question Answering with Vision-Language Models
arXiv cs.CV / 3/20/2026
📰 NewsTools & Practical UsageModels & Research
Key Points
- HORNet is a lightweight frame-selection policy trained with Group Relative Policy Optimization (GRPO) to choose the frames a frozen vision-language model needs for reliable VQA performance.
- It achieves dramatic efficiency gains by reducing input frames by up to 99% and VLM processing time by up to 93%, while boosting answer quality on short-form benchmarks (+1.7% F1 on MSVD-QA) and temporal reasoning tasks (+7.3 points on NExT-QA).
- The method formalizes Select Any Frames (SAF) and generalizes better out-of-distribution than supervised or PPO baselines, with cross-model transfer yielding an additional 8.5% relative gain when paired with a stronger VLM.
- Evaluated on six benchmarks (341,877 QA pairs, 114.2 hours of video) and with publicly available code, HORNet demonstrates that choosing what the model sees is a practical complement to improving what it generates.
Related Articles
Two bots, one confused server: what Nimbus revealed about AI agent identity
Dev.to
How to Create a Month of Content in One Day Using AI (Step-by-Step System)
Dev.to

OpenTelemetry just standardized LLM tracing. Here's what it actually looks like in code.
Dev.to
🌱 How AI is Transforming Planting — and Why It Matters
Dev.to
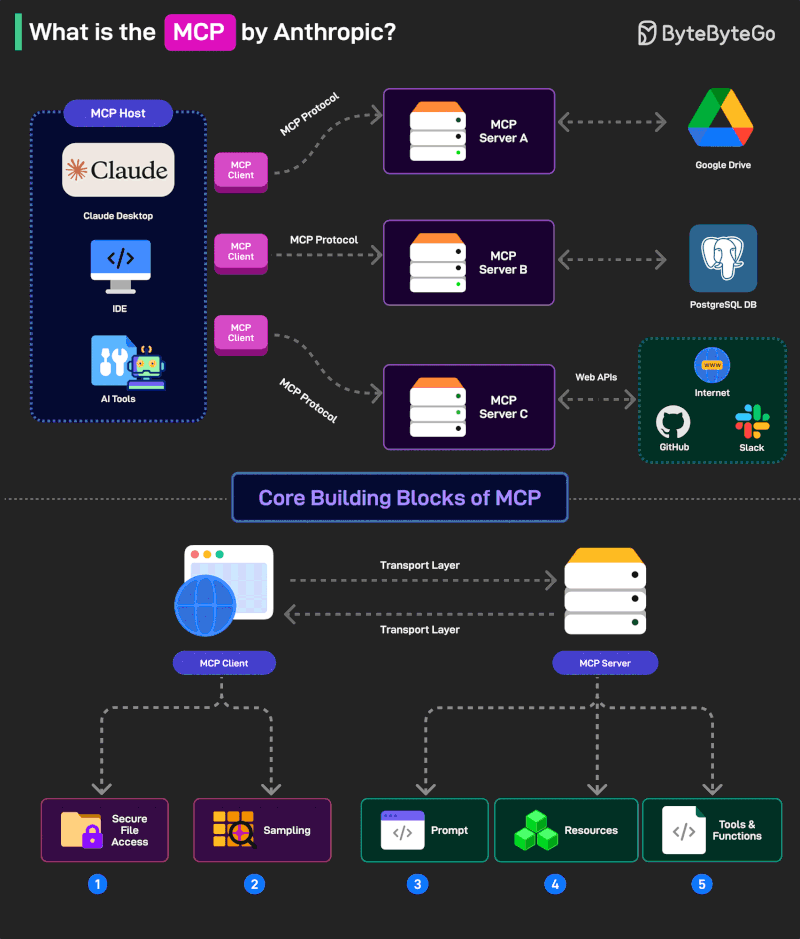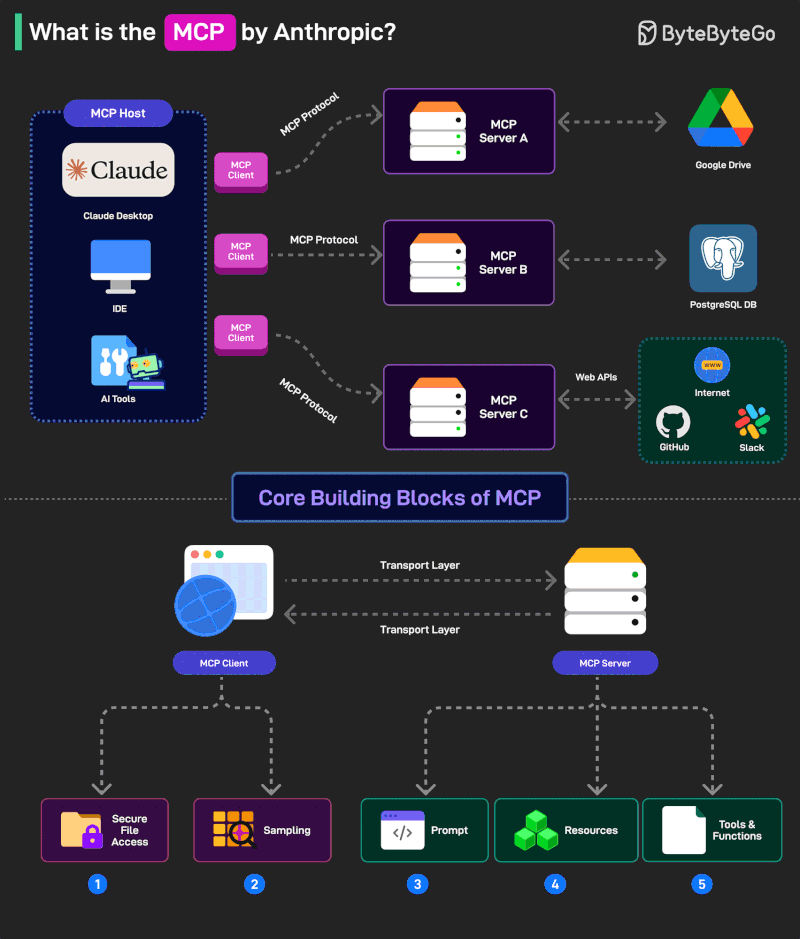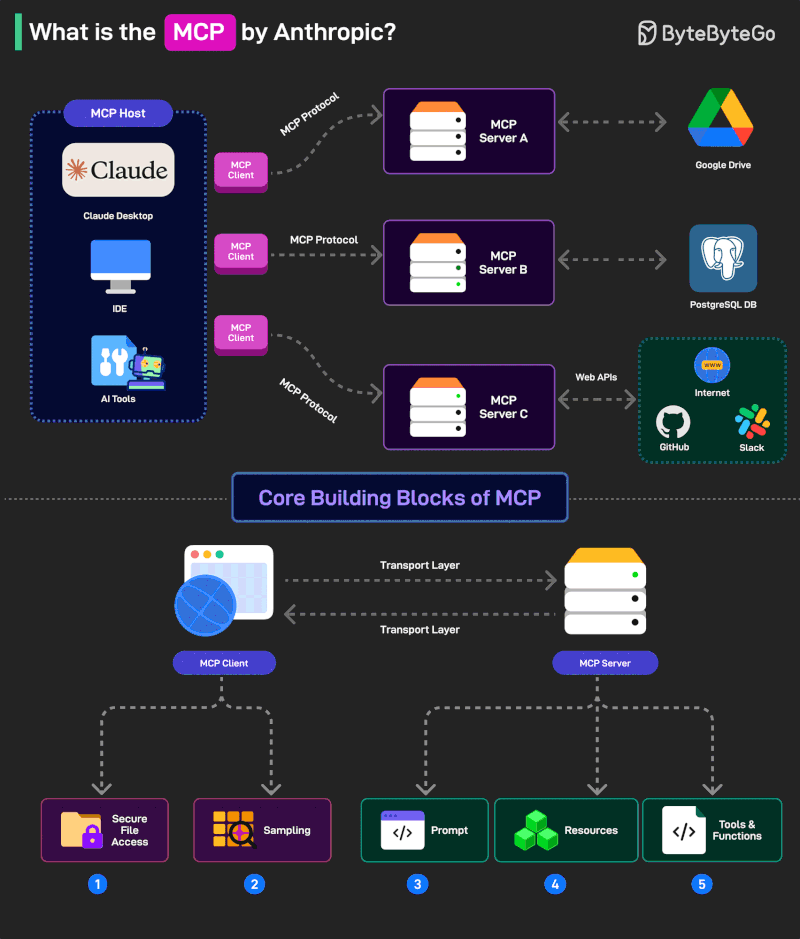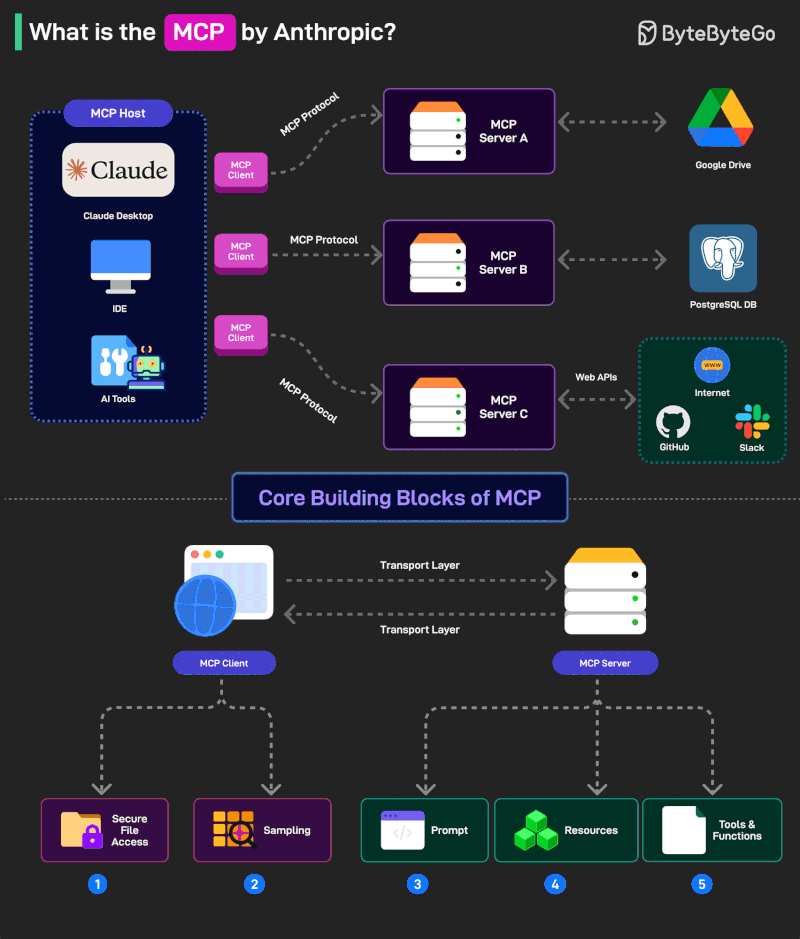
What is MCP?
Dev.to