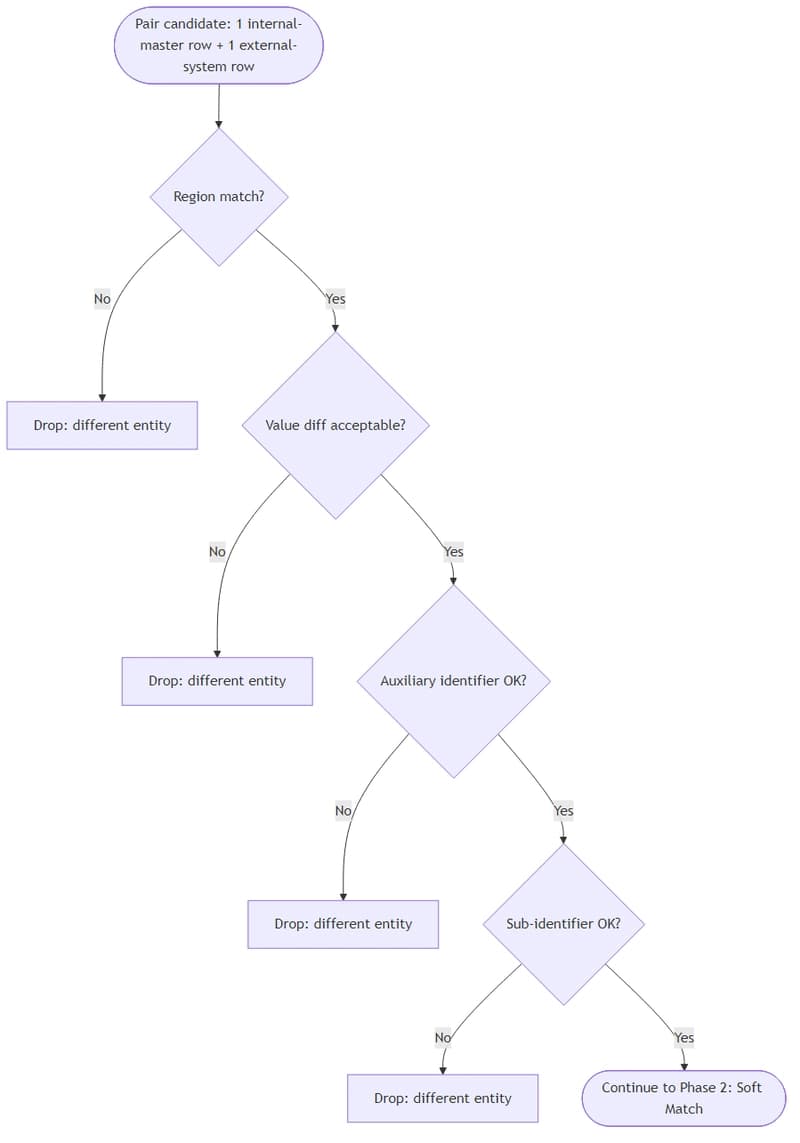
Retrieval is where most RAG systems quietly break. Traditional pipelines rely on vector similarity—embedding queries and document chunks into the same space and fetching the “closest” matches. But similarity is a weak proxy for what we actually need: relevance grounded in reasoning. In long, professional documents—like financial reports, research papers, or legal texts—the right answer […]
The post RAG Without Vectors: How PageIndex Retrieves by Reasoning appeared first on MarkTechPost.