Kernel-Smith: A Unified Recipe for Evolutionary Kernel Optimization
arXiv cs.CL / 3/31/2026
💬 OpinionDeveloper Stack & InfrastructureIdeas & Deep AnalysisModels & Research
Key Points
- Kernel-Smithは、GPUカーネル/演算子を高性能に生成するためのフレームワークで、評価駆動の進化的エージェントと進化志向の後処理(post-trainingレシピ)を統合して探索の安定性と性能を高めることを狙っている。
- エージェント側では、実行可能な候補の集団を維持し、上位かつ多様なプログラムのアーカイブと、コンパイル可否・正しさ・スピードアップに関する構造化フィードバックを用いて反復的に改善する。
- 信頼性のために、NVIDIA GPU向けTritonと、MetaX GPU向けMacaそれぞれに対するバックエンド別の評価サービスを構築している。
- 学習(後処理)では長期の進化軌跡を「ステップ中心」の教師信号と強化学習信号に変換し、進化ループ内で強力なローカル改善器として機能するよう最適化する方針を採る。
- KernelBenchでのTritonバックエンドではKernel-Smith-235B-RLが平均スピードアップ比で最先端のプロプライエタリモデル(Gemini-3.0-pro、Claude-4.6-opus)を上回り、さらにMacaでもKernel-Smith-MACA-30Bが大規模先行モデル(DeepSeek-V3.2-think、Qwen3-235B-2507-think)より優位で、SGLangやLMDeployへのプロダクション向け貢献も報告している。
Related Articles

How to Verify Information Online and Avoid Fake Content
Dev.to
I built an AI code reviewer solo while working full-time — honest post-launch breakdown
Dev.to
Mobile App MVP: Build, Launch, and Validate in Under a Week
Dev.to
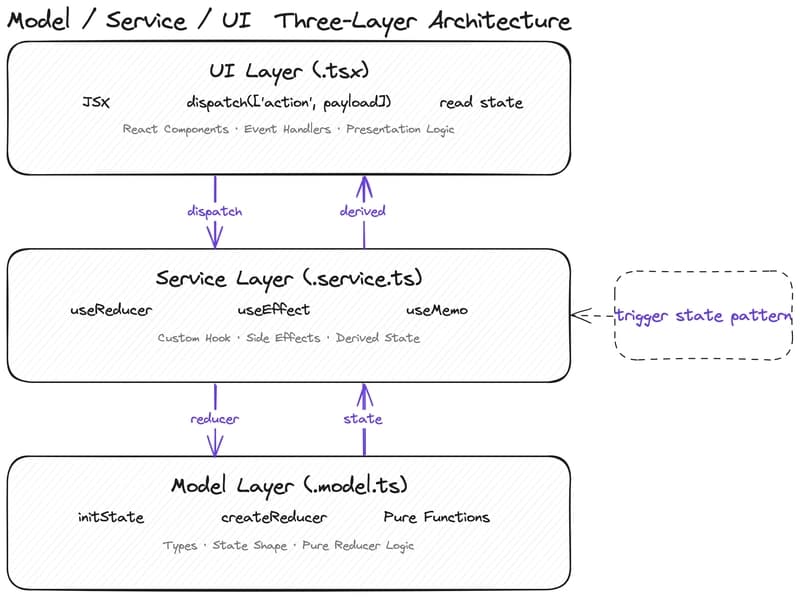
Why Your State Management Is Slowing Down AI-Assisted Development
Dev.to
How to Reduce OpenClaw and Agent Token Costs
Dev.to