Architecture-Aware LLM Inference Optimization on AMD Instinct GPUs: A Comprehensive Benchmark and Deployment Study
arXiv cs.AI / 3/12/2026
💬 OpinionDeveloper Stack & InfrastructureIdeas & Deep AnalysisModels & Research
Key Points
- The study benchmarks production LLM inference on AMD Instinct MI325X GPUs across four models spanning 235B to 1T parameters on an 8-GPU cluster with 2TB aggregate HBM3e using vLLM v0.14.1, and demonstrates that architecture-aware optimization is essential.
- MLA models require block size 1 and cannot use KV cache offloading, whereas GQA models benefit from both block size and KV cache offloading.
- The AMD AITER runtime is required for competitive MLA inference throughput and must be selectively disabled for architectures with incompatible attention head configurations.
- A controlled AITER ablation on Llama-3.1-405B shows a modest 3-5% throughput benefit at high concurrency but 2-16x higher measurement variability, confirming that AITER's large speedups target MoE/MLA kernels specifically.
- In text-only workloads, Llama-405B and DeepSeek V3.2 reach peak throughput of 15,944 and 15,343 tok/s respectively, while in vision workloads Qwen3-VL-235B achieves 47,873 tok/s, and all models hit a memory-bandwidth bottleneck with saturation around 500 concurrent short sequences and 100-200 for longer sequences, while maintaining 100% HTTP-level success up to 1,000 concurrent users processing 18.9 million tokens across 17,406 requests without failures.
Related Articles
Day 10: 230 Sessions of Hustle and It Comes Down to One Person Reading a Document
Dev.to

5 Dangerous Lies Behind Viral AI Coding Demos That Break in Production
Dev.to
Two bots, one confused server: what Nimbus revealed about AI agent identity
Dev.to

OpenTelemetry just standardized LLM tracing. Here's what it actually looks like in code.
Dev.to
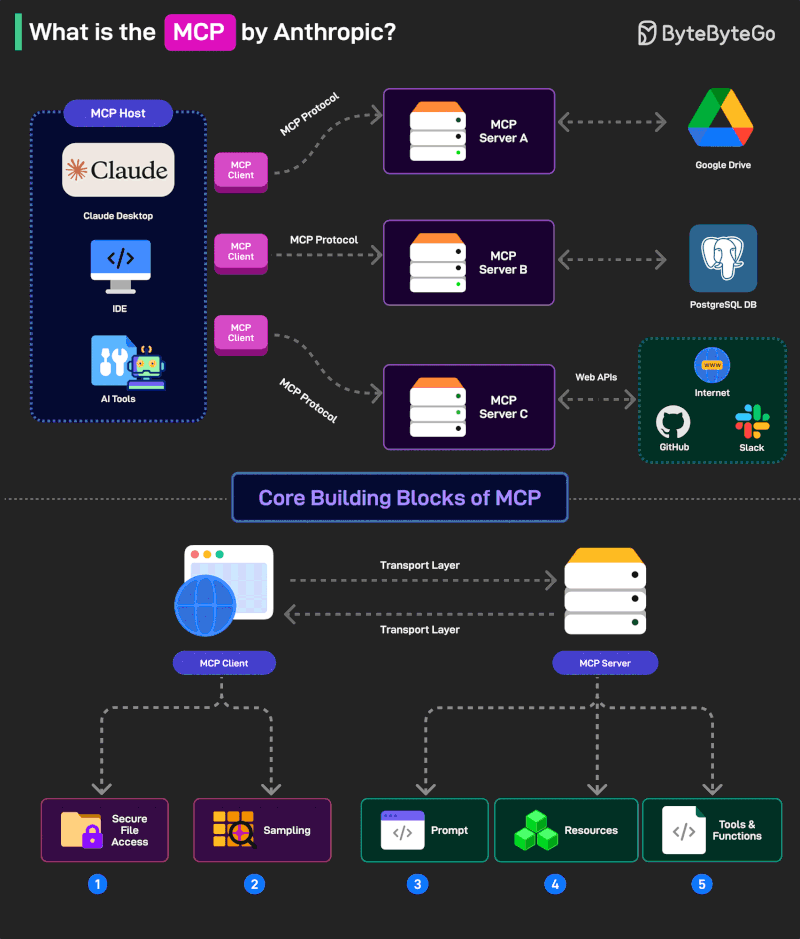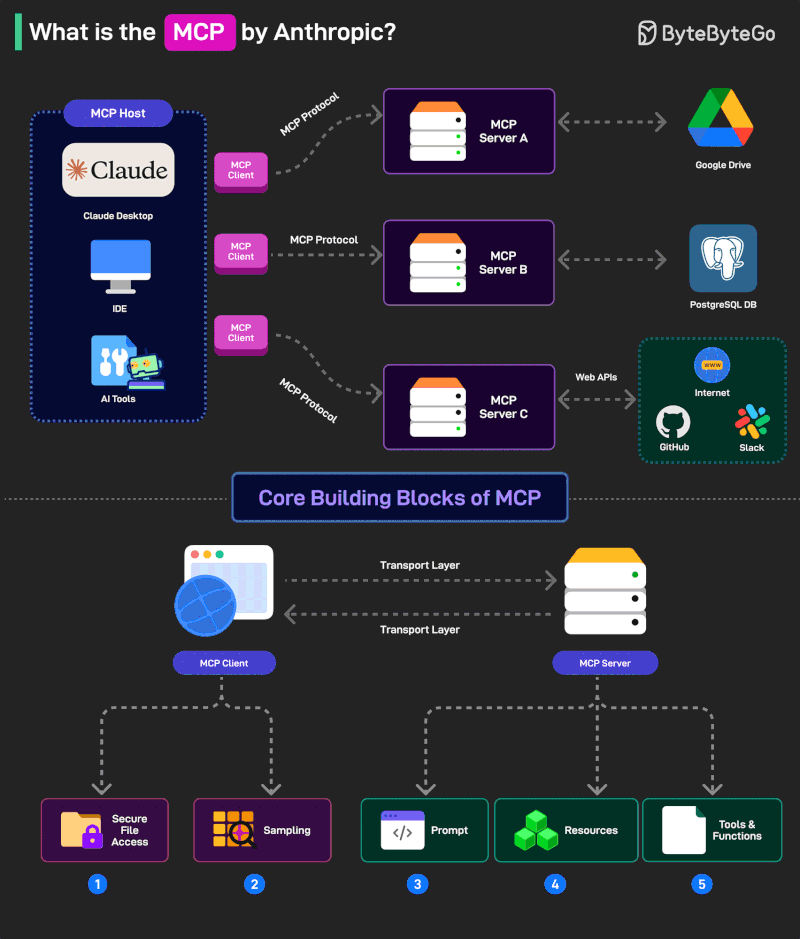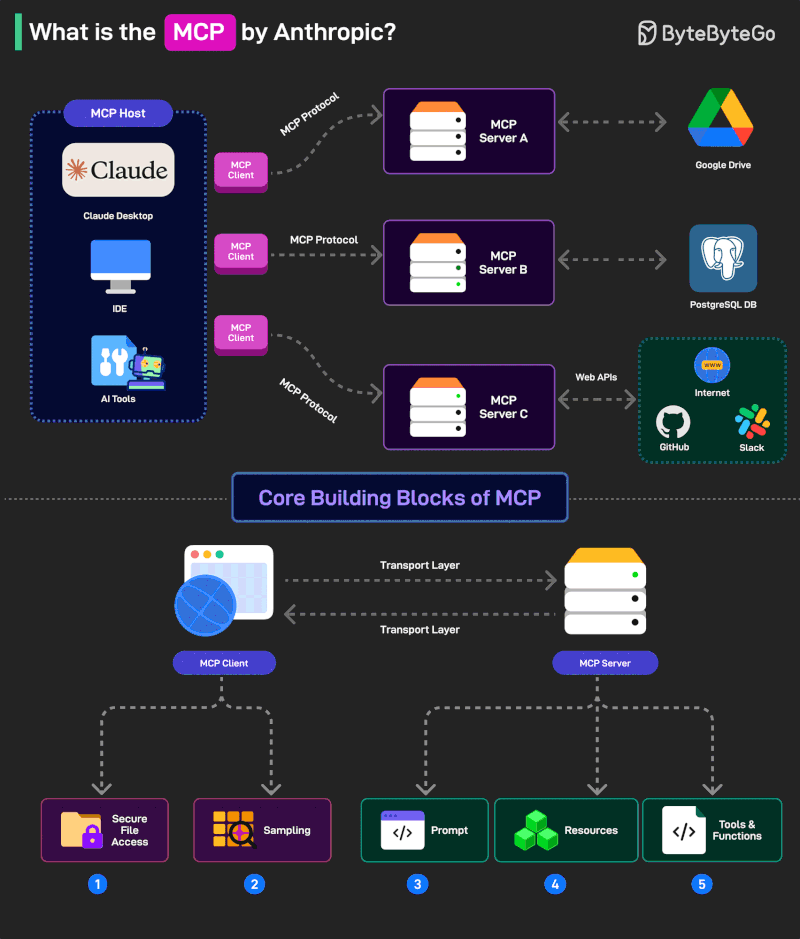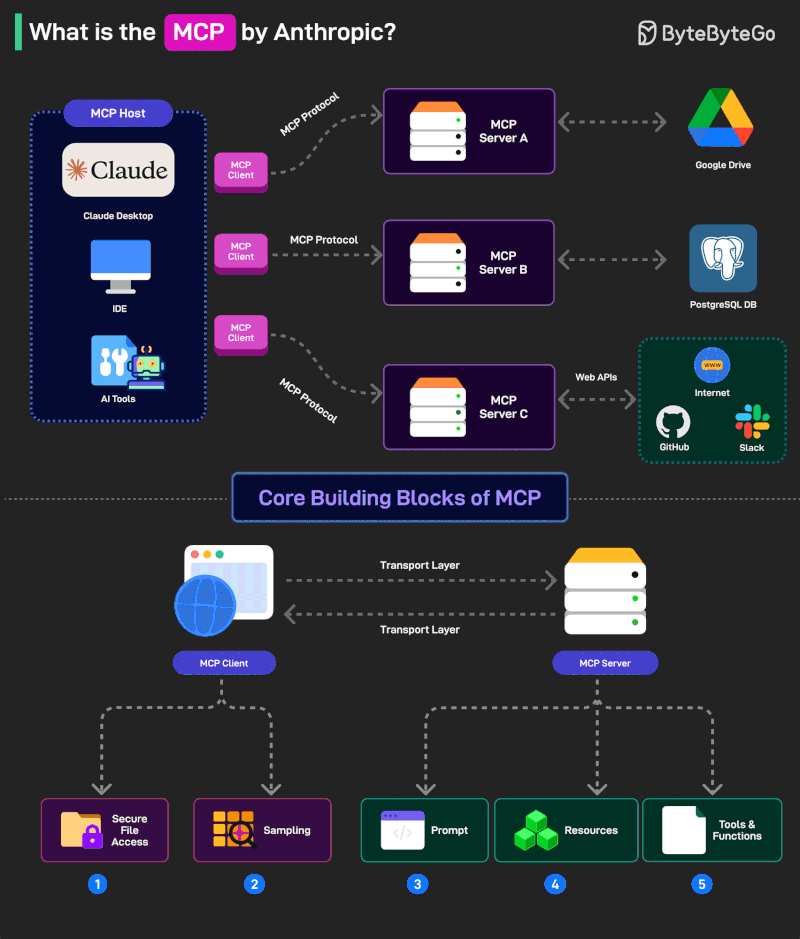
What is MCP?
Dev.to