Knows: Agent-Native Structured Research Representations
arXiv cs.AI / 4/21/2026
📰 NewsDeveloper Stack & InfrastructureSignals & Early TrendsModels & Research
Key Points
- The paper introduces “Knows,” a lightweight companion format that attaches structured, verifiable research data (claims, evidence, provenance, and relations) to existing papers for easier consumption by LLM agents.
- Knows uses a thin YAML sidecar (KnowsRecord) alongside the original PDF, requiring no changes to the publication and enforcing correctness via a deterministic schema linter.
- In evaluations on 140 comprehension questions across 20 papers and 14 disciplines, using the sidecar substantially improves accuracy for smaller “weak” LLM agents (0.8B–2B parameters), while also reducing input token usage.
- Re-scoring by an LLM-as-a-judge suggests that weak-model performance with the sidecar can closely approach strong-model PDF-only accuracy.
- The project reports early adoption signals through a community sidecar hub that has indexed over ten thousand publications, supporting claims of scalability and readiness for real-world use.
Related Articles

¿Hasta qué punto podría la IA reemplazarnos en nuestros trabajos? A veces creo que la gente exagera un poco.
Reddit r/artificial

Why I Built byCode: A 100% Local, Privacy-First AI IDE
Dev.to

Magnificent irony as Meta staff unhappy about running surveillance software on work PCs
The Register
v0.21.1
Ollama Releases
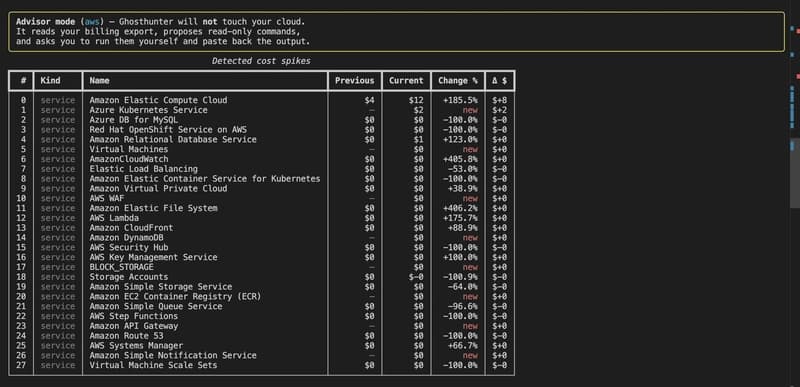
How I Built an AI Agent That Investigates Cloud Bill Spikes (Architecture Inside)
Dev.to