Target-Bench: Can Video World Models Achieve Mapless Path Planning with Semantic Targets?
arXiv cs.RO / 4/16/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The paper introduces Target-Bench, a benchmark designed to evaluate whether video world models can perform semantic reasoning, spatial estimation, and planning using semantic target goals.
- Target-Bench includes 450 robot-collected scenarios across 47 semantic categories and uses SLAM-based trajectories as reference motion tendencies, along with metric scale recovery to reconstruct motion from generated videos.
- The benchmark provides five complementary metrics that measure target-approaching ability and directional consistency, enabling more comprehensive planning evaluation than prior qualitative assessments.
- Experimental results show a substantial performance gap: the best off-the-shelf video world model reaches only a 0.341 overall score, suggesting realistic video generation does not yet imply robust semantic planning.
- The authors report that fine-tuning on a relatively small real-world robot dataset can substantially improve planning performance at the task level, indicating a practical path toward better planning-capable models.
Related Articles

The AI Hype Cycle Is Lying to You About What to Learn
Dev.to

Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Inside NVIDIA’s $2B Marvell Deal: What NVLink Fusion Means for AI Ethernet Fabrics
Dev.to

Automating Your Literature Review: From PDFs to Data with AI
Dev.to
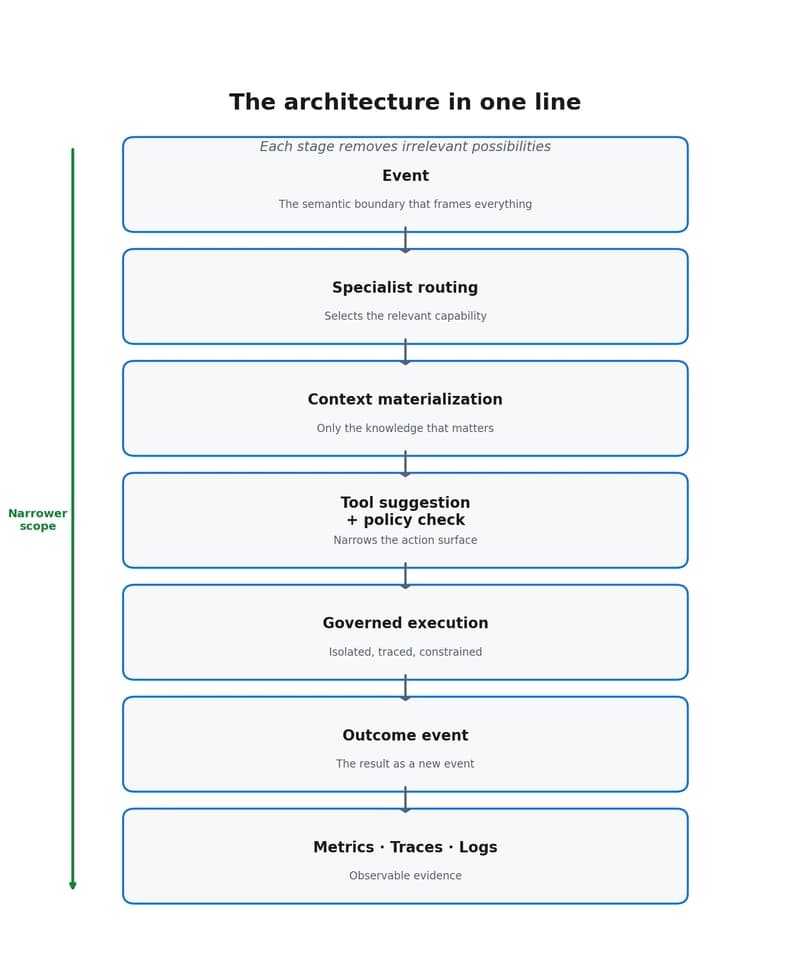
Why event-driven agents reduce scope, cost, and decision dispersion
Dev.to