From Where Words Come: Efficient Regularization of Code Tokenizers Through Source Attribution
arXiv cs.CL / 4/16/2026
📰 NewsIdeas & Deep AnalysisModels & Research
Key Points
- The paper argues that code-tokenizer quality strongly affects LLM efficiency and safety, including defenses against jailbreaks and reductions in hallucination risk.
- It identifies a key problem in tokenizer training: imbalanced repository/language diversity can cause many unused or under-trained tokens, while repetitive source-specific tokens may be unusable during future inference.
- The proposed solution, Source-Attributed BPE (SA-BPE), modifies the BPE training objective and introduces merge skipping to regularize training and reduce overfitting to specific sources.
- The authors claim SA-BPE substantially lowers the number of under-trained tokens while keeping the same inference procedure as standard BPE, making it suitable for production deployment.
Related Articles

The AI Hype Cycle Is Lying to You About What to Learn
Dev.to

Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Inside NVIDIA’s $2B Marvell Deal: What NVLink Fusion Means for AI Ethernet Fabrics
Dev.to

Automating Your Literature Review: From PDFs to Data with AI
Dev.to
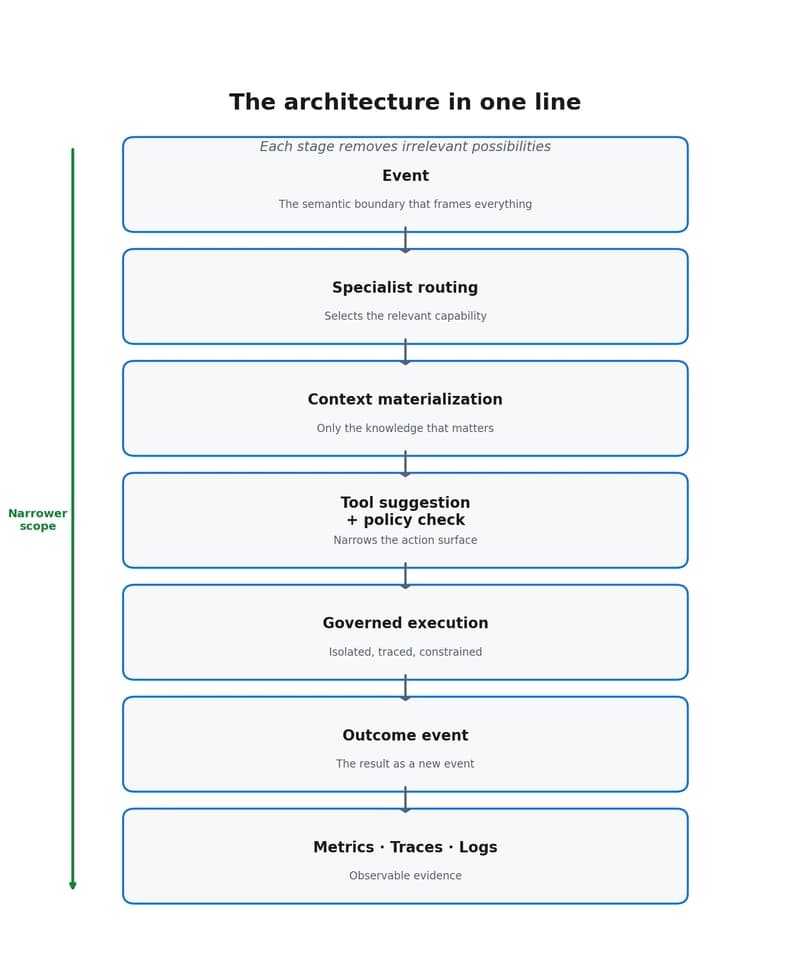
Why event-driven agents reduce scope, cost, and decision dispersion
Dev.to