Debate as Reward: A Multi-Agent Reward System for Scientific Ideation via RL Post-Training
arXiv cs.AI / 4/21/2026
📰 NewsDeveloper Stack & InfrastructureIdeas & Deep AnalysisModels & Research
Key Points
- The paper proposes an RL post-training framework for LLM-based multi-agent scientific ideation that aims to reduce hallucinations and computational inefficiency from earlier prompting or complex multi-agent approaches.
- It introduces a multi-agent reward function that acts as a “judge,” separating methodological validation from implementation details and using strict binary rewards to resist reward hacking.
- Because the reward signal is sparse, the authors optimize using an unbiased variant of Group Relative Policy Optimization to avoid artificial length bias.
- Training is grounded in ICLR-320, a dataset of problem-solution pairs curated from ICLR 2024 proceedings, and experiments show strong gains over prior baselines on expert-evaluated novelty, feasibility, and effectiveness metrics.
Related Articles

¿Hasta qué punto podría la IA reemplazarnos en nuestros trabajos? A veces creo que la gente exagera un poco.
Reddit r/artificial

Why I Built byCode: A 100% Local, Privacy-First AI IDE
Dev.to

Magnificent irony as Meta staff unhappy about running surveillance software on work PCs
The Register
v0.21.1
Ollama Releases
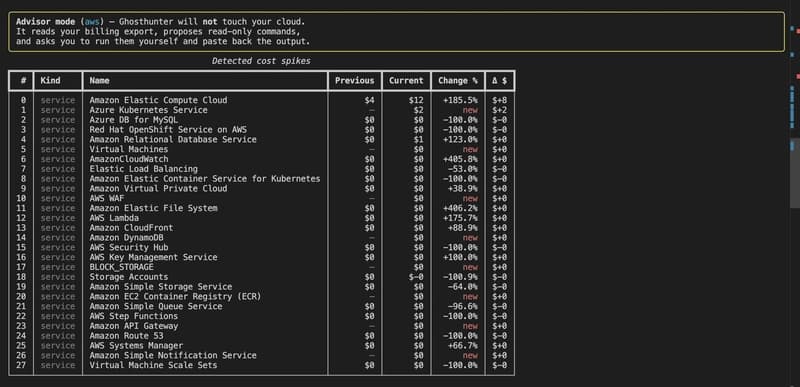
How I Built an AI Agent That Investigates Cloud Bill Spikes (Architecture Inside)
Dev.to