Good in Bad (GiB): Sifting Through End-user Demonstrations for Learning a Better Policy
arXiv cs.RO / 5/5/2026
📰 NewsModels & Research
Key Points
- The paper addresses a key imitation-learning challenge: demonstrations collected from non-expert users often include errors that can make learned robot policies unsafe or degrade performance.
- It proposes GiB (Good-in-Bad), an algorithm that automatically filters demonstrations by identifying and discarding only erroneous subtasks while retaining high-quality parts.
- GiB uses a two-stage approach: it trains a self-supervised model to learn latent features and a binary classifier to mark segments as good or bad.
- It then fits the latent-feature distribution of good-quality segments and applies Mahalanobis distance to detect and evaluate low-quality subtasks.
- Experiments on a Franka robot across simulated and real multi-step tasks show improved policy performance when training on mixed-quality human demonstrations.
Related Articles

Singapore's Fraud Frontier: Why AI Scam Detection Demands Regulatory Precision
Dev.to
From OOM to 262K Context: Running Qwen3-Coder 30B Locally on 8GB VRAM
Dev.to

Nano Banana Pro vs DALL-E 3 vs Midjourney: A Practical Comparison From Someone Who Actually Uses All Three
Dev.to
LLMs edited 86 human essays toward a semantic cluster not occupied by any human writer [D]
Reddit r/MachineLearning
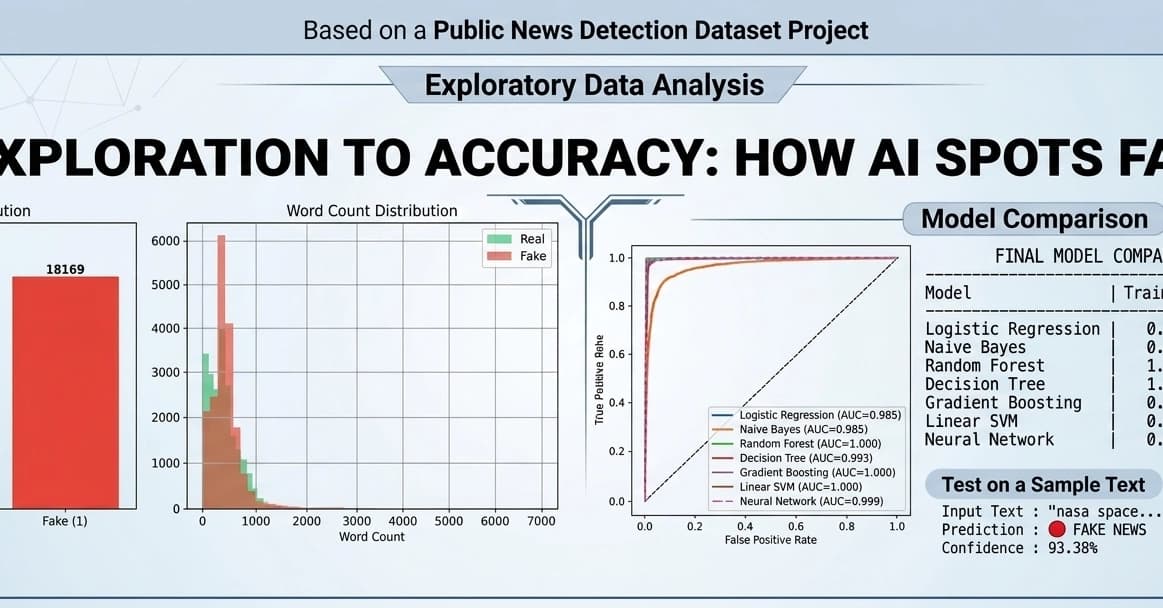
Fake News Detection using Machine Learning & NLP!
Dev.to