An Information-Theoretic Analysis of OOD Generalization in Meta-Reinforcement Learning
arXiv stat.ML / 4/7/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The paper analyzes out-of-distribution (OOD) generalization in meta-reinforcement learning using an information-theoretic framework.
- It derives OOD generalization bounds for meta-supervised learning under two shift settings: standard distribution mismatch and broad-to-narrow training.
- The authors then formalize the OOD generalization problem specifically for meta-reinforcement learning and prove more detailed bounds by leveraging Markov Decision Process (MDP) structure.
- The study includes an examination of how a gradient-based meta-reinforcement learning algorithm performs under the proposed generalization analysis.
Related Articles
Research with ChatGPT
Dev.to
Silicon Valley is quietly running on Chinese open source models and almost nobody is talking about it
Reddit r/LocalLLaMA

Why AI Product Quality Is Now an Evaluation Pipeline Problem, Not a Model Problem
Dev.to
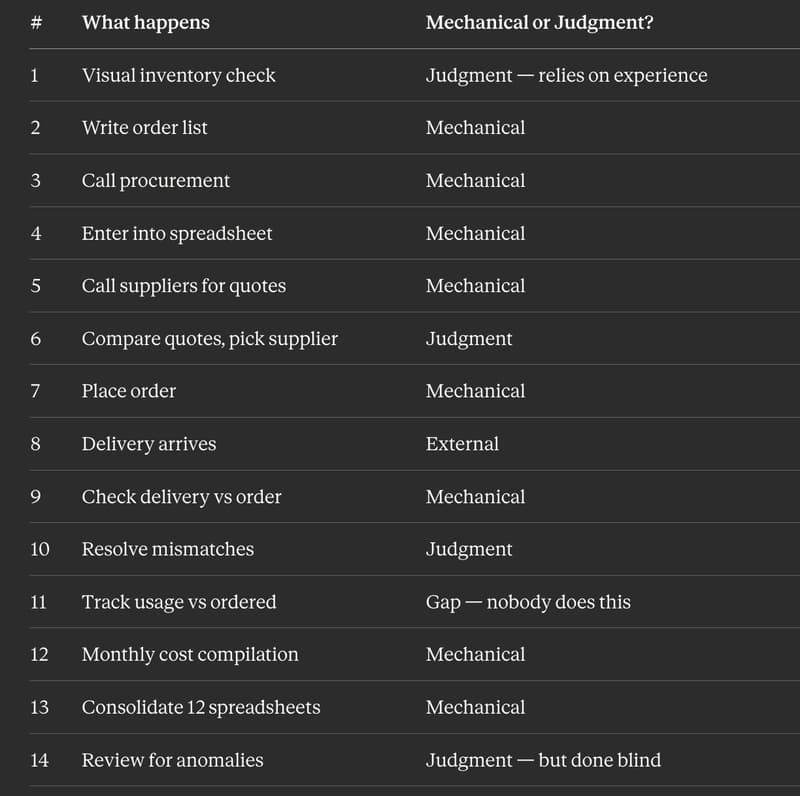
I Replaced 12 Kitchen Managers Guessing "How Much Chicken Do We Need" With 3 ML Models. Here's the Entire Architecture.
Dev.to

AI Model Router API - REST + MCP, Free Tier
Dev.to