書籍『作ってわかる大規模言語モデルの仕組み』(日経BP)は、大規模言語モデル(LLM)の基礎理論から実装まで、体系的に学べることを目指しています。本特集では書籍の序盤部を抜粋し、LLM発展の歴史を振り返りつつ、昨今のLLMの核となる「Transformer」「アテンション機構」について数式やコードも織り交ぜながら丁寧に解説します。第1回ではまず、LLMの歴史を振り返ります。
本特集で解説するLLMの隆盛は、一夜にして実現したものではありません。いくつかの重要なブレイクスルーの積み重ねによって、今日の姿があります。ここでは、2017年から現在に至るまでの主要な出来事を振り返ります。
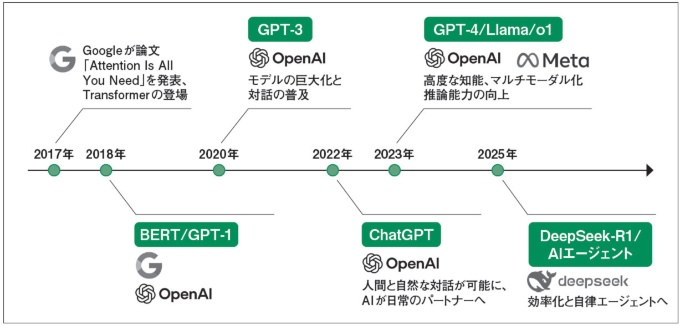
2017年
現代AIの歴史において、2017年は「紀元前」と「紀元後」を分かつ決定的な年となりました。Googleの研究チームが発表した「Attention Is All You Need」という論文が、それまでの常識を根底から覆したのです。

それまでのAIは、情報を端から順番に処理するしかありませんでした。そのため、長い文章になると最初の方の内容を「忘れてしまう」という弱点があったのです。これに対し、新しく登場したTransformerは、文章全体をパッと一度に見渡し、単語同士のつながりを同時に計算する仕組みを導入しました。これにより、膨大なデータを高速に、そして正確に学習する土台が完成したのです。
2018〜2019年
Transformerという強力なエンジンを手に入れたAIの世界は、ここで大きく2つの方向に進化します。
一つは、文章を深く読み解くのが得意なBERT(Google)です。検索エンジンなどの「文脈を理解する」能力を劇的に高め、私たちの日常の検索体験を裏側で支えるようになりました。もう一つは、文章の続きを予測して作るのが得意なGPT-1(OpenAI)です。特に2019年のGPT-2は、あまりに自然な文章を書くことができたため、「悪用されると危険だ」と公開が制限されるほどの騒ぎになりました。なお本書では、このGPT-2相当のLLMを実装した後、それ以降に登場した新しい技術にも取り組んでいきます。
次のページ
2020〜2022年この記事は会員登録で続きをご覧いただけます
