Active Reasoning Vision-Language Models via Sequential Experimental Design
arXiv cs.CV / 5/5/2026
📰 NewsModels & Research
Key Points
- The paper argues that vision-language models face a “perceptual bandwidth bottleneck,” where wide field-of-view trade-offs reduce fine details needed for complex reasoning.
- It reformulates overcoming this limitation as a sequential decision-making problem using sequential Bayesian optimal experimental design (S-BOED), balancing spatial coverage with resolution.
- Because exact Bayesian inference is intractable for continuous gigapixel image spaces, the authors derive tractable approximations to make the approach practical.
- They propose a training-free inference strategy that instantiates the S-BOED objective for agents using multiple vision tools, supporting greedy sampling to look-ahead planning.
- Experiments on gigapixel-level benchmarks show improved performance over state-of-the-art baselines and a reduced gap toward human-annotated oracle performance.
Related Articles

Singapore's Fraud Frontier: Why AI Scam Detection Demands Regulatory Precision
Dev.to
From OOM to 262K Context: Running Qwen3-Coder 30B Locally on 8GB VRAM
Dev.to

Nano Banana Pro vs DALL-E 3 vs Midjourney: A Practical Comparison From Someone Who Actually Uses All Three
Dev.to
LLMs edited 86 human essays toward a semantic cluster not occupied by any human writer [D]
Reddit r/MachineLearning
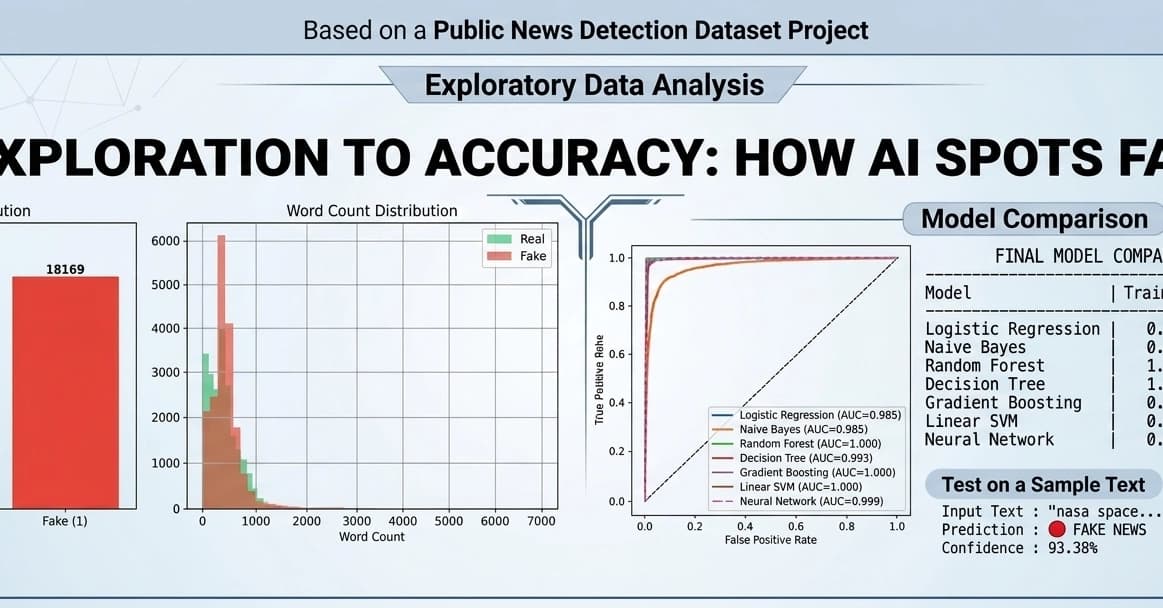
Fake News Detection using Machine Learning & NLP!
Dev.to