LongFlow: Efficient KV Cache Compression for Reasoning M
arXiv cs.LG / 3/13/2026
📰 NewsDeveloper Stack & InfrastructureModels & Research
Key Points
- LongFlow introduces a KV cache compression method to reduce memory consumption and bandwidth pressure during attention in long-output reasoning models.
- It derives an efficient importance estimation metric from the current query, achieving negligible overhead and requiring no extra auxiliary storage.
- A custom kernel that fuses FlashAttention, importance estimation, and token eviction into a single optimized operator further boosts system-level efficiency.
- Experiments report up to 11.8x throughput improvement with about 80% KV cache compression and minimal impact on model accuracy.
- The work targets the limitations of prior KV cache optimizations, which were designed for long-input/short-output scenarios and are less effective for long-output reasoning.
Related Articles

5 Dangerous Lies Behind Viral AI Coding Demos That Break in Production
Dev.to
Two bots, one confused server: what Nimbus revealed about AI agent identity
Dev.to

OpenTelemetry just standardized LLM tracing. Here's what it actually looks like in code.
Dev.to
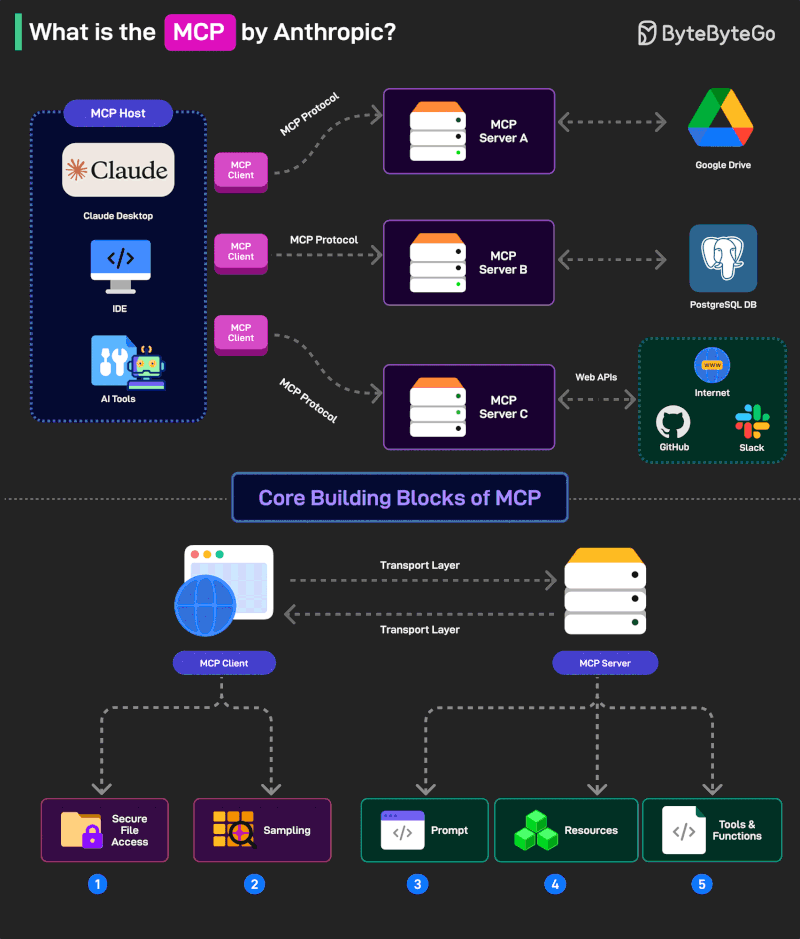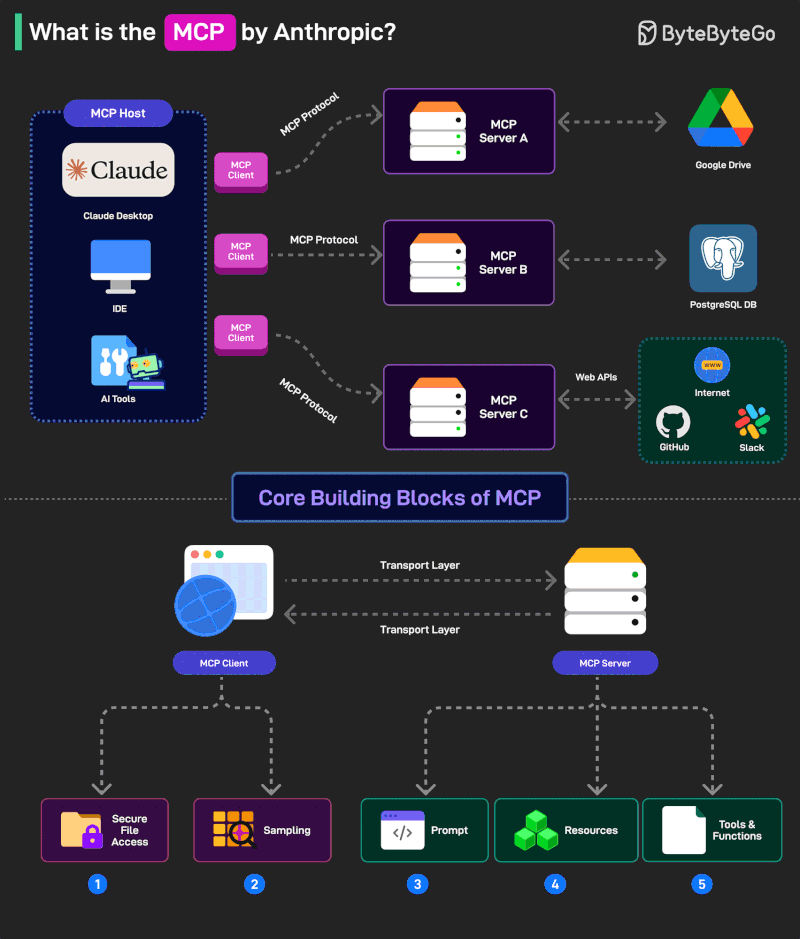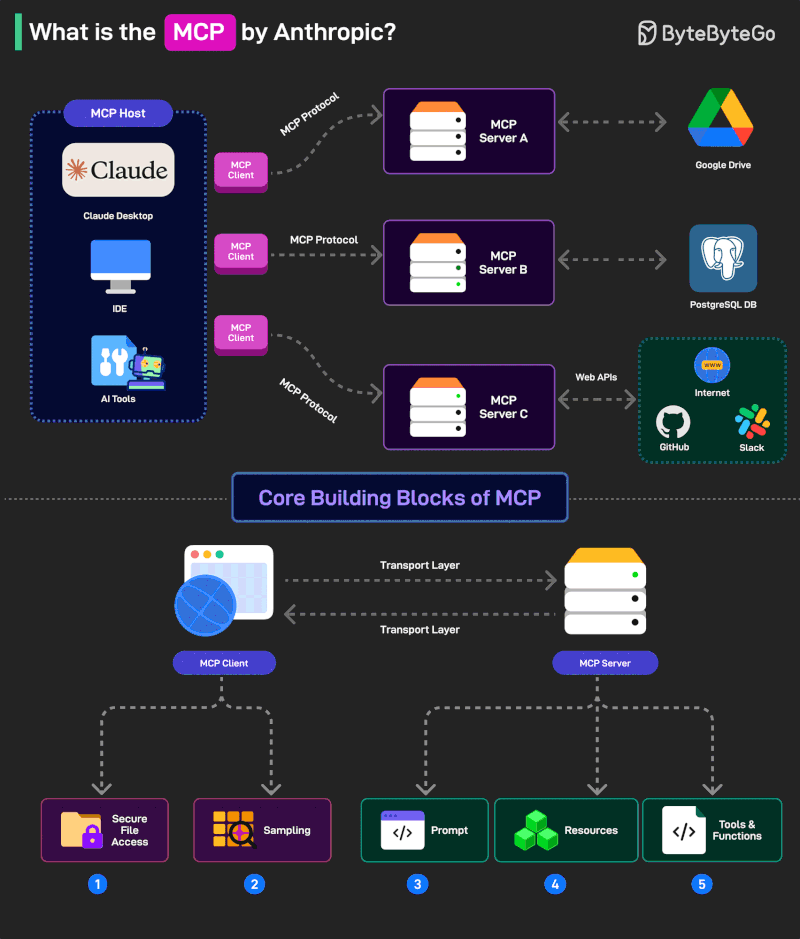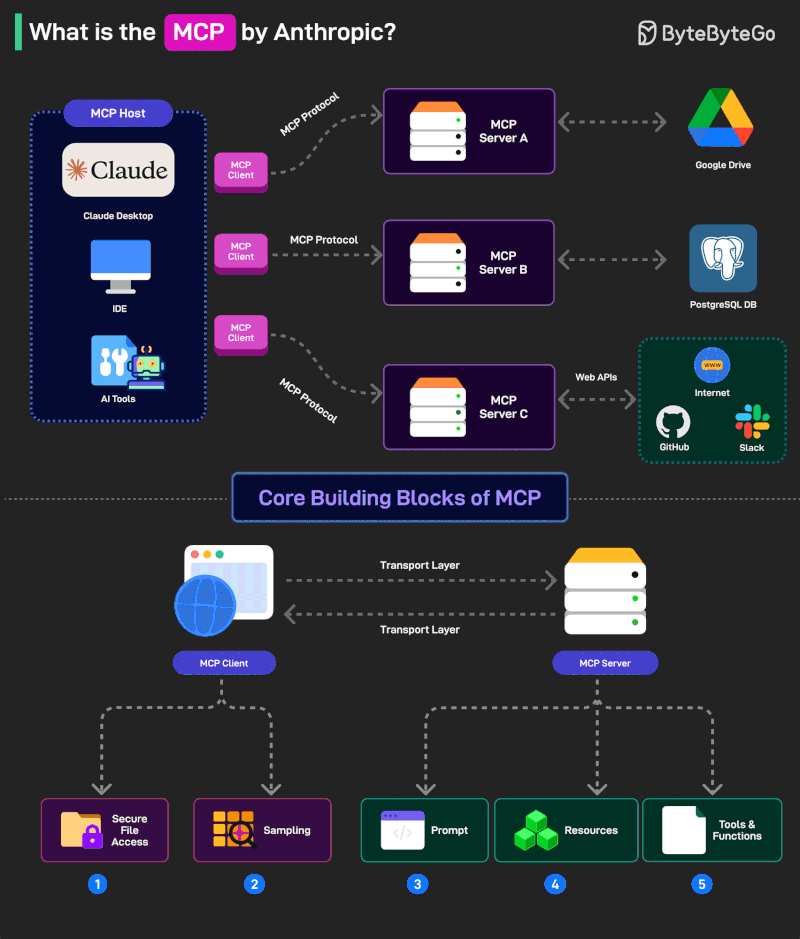
What is MCP?
Dev.to
PIXIU: A Large Language Model, Instruction Data and Evaluation Benchmark forFinance
Dev.to