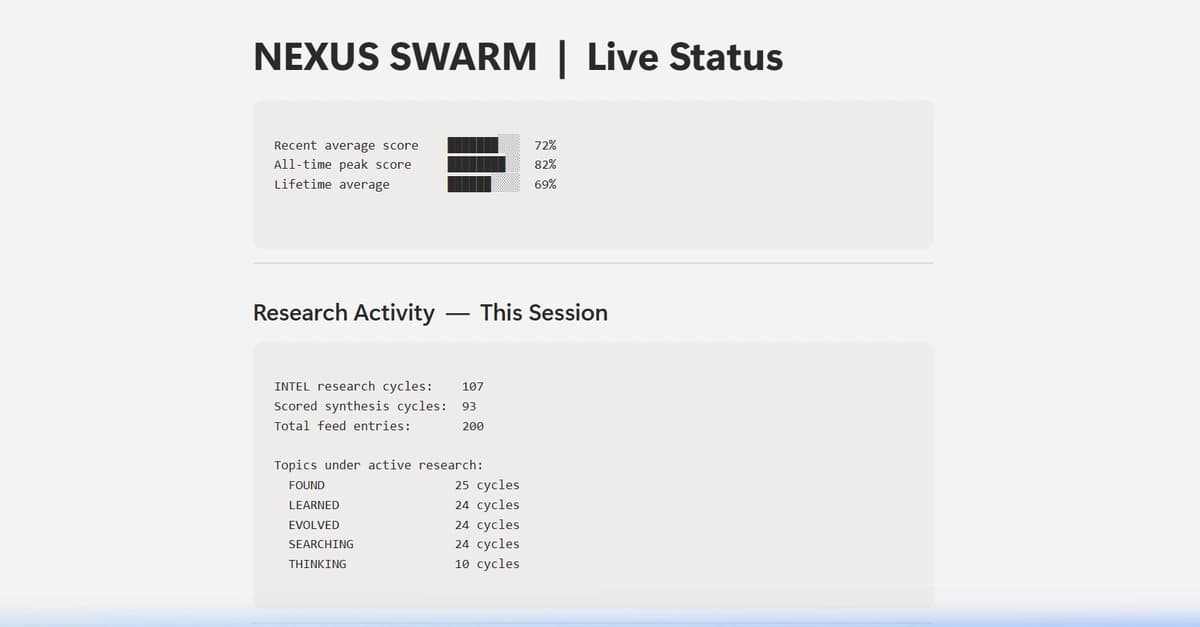
I’ve got myself a solid setup running (128gb Strix Halo unified memory) and an LLM model I like for general purposes (GPT-OSS 120B Q4 via llama.cpp + Open Web UI). I’m building out some data for it to reference and experimenting with Open Web UI features. It’s fun to min-max with different models and configurations.
I’m good with stepping out of the rat race for capabilities for a little while. I have big plans for how to use what I have and I’m interested to hear what others are doing. Personally hoping to build out what amounts to an AI-enabled self-hosting server with data ownership being at the forefront of my efforts. Streaming, personal document repository, legal assistant (mostly to interpret unreasonably long terms & conditions), and a mess of other half-baked ideas.
How are you folks getting the most enjoyment out of your setup?
[link] [comments]