Google battles Chinese open-weights models with Gemma 4
Now with a more permissive license, multi-modality, and support for more than 140 languages
Google on Thursday unleashed a wave of new open-weights Gemma models optimized for agentic AI and coding, under a more permissive Apache 2.0 license aimed at winning over enterprises.
The launch comes amidst an onslaught of open-weights Chinese large language models (LLMs) from Moonshot AI, Alibaba, and Z.AI, many of which now rival OpenAI's GPT-5 or Anthropic's Claude.
With its latest release, Google is offering enterprise customers a domestic alternative, but one that won't just hoover up sensitive corporate data to train future models.
Developed by Google's DeepMind team, the fourth generation of Gemma models brings several improvements, including "advanced reasoning" to improve performance in math and instruction-following, support for more than 140 languages, native function calling, and video and audio inputs.
As with prior Gemma models, Google is making them available in multiple sizes to address applications ranging from single board computers and smartphones to laptops and enterprise datacenters.
At the top of the stack is a 31 billion-parameter LLM that, Google says, has been tuned to maximize output quality.
Given its size, the model isn't at risk of cannibalizing Google's larger proprietary models, but is small enough that enterprises won't need to run out and spend hundreds of thousands of dollars on GPU servers to run or fine tune it.
According to Google, the model can run unquantized at 16-bit on a single 80 GB H100. Meanwhile at 4-bit precision, the model is small enough to fit on a 24 GB GPU like an Nvidia RTX 4090 or AMD RX 7900 XTX using frameworks such as Llama.cpp or Ollama.
For applications requiring lower latency, aka faster responses, the Gemma 4 lineup also includes a 26 billion-parameter model that uses a mixture of experts (MoE) architecture.
During inference, a subset of the model's 128 experts, totaling 3.8 billion active parameters, is used to process and generate each token. So long as you can fit the model into your VRAM, it can generate tokens far faster than a dense model of equivalent size.
This higher speed does come at the expense of lower quality outputs, since only a fraction of the parameters are used to process the output. However, this may be worthwhile if running on devices with slower memory, like a notebook or consumer graphics card.
Both of these models feature a 256,000-token context window, making them appropriate for local code assistants, a use case Google was keen to highlight in its launch announcement.
Alongside these models are a pair of LLMs optimized for low-end edge hardware like smartphones and single board computers, like the Raspberry Pi. These models are available in two sizes, one with two billion effective parameters and another with four billion.
The keyword here is "effective." The models actually have 5.1 and 8 billion parameters, respectively, but by using per-layer embeddings (PLE), Google is able to reduce the effective size of the model in terms of compute to between 2.3 billion and 4.5 billion parameters, making them more efficient to run on devices with limited compute or batteries.
Despite their size, the two models still offer a context window of 128,000 tokens and are multimodal, which means that, in addition to text, they can accept visual and audio data (E2B/E4B only) as inputs.
As with all vendor-supplied benchmarks, take these claims with a grain of salt, but compared to Gemma 3, Google boasts significant performance improvements in a variety of AI benchmarks:
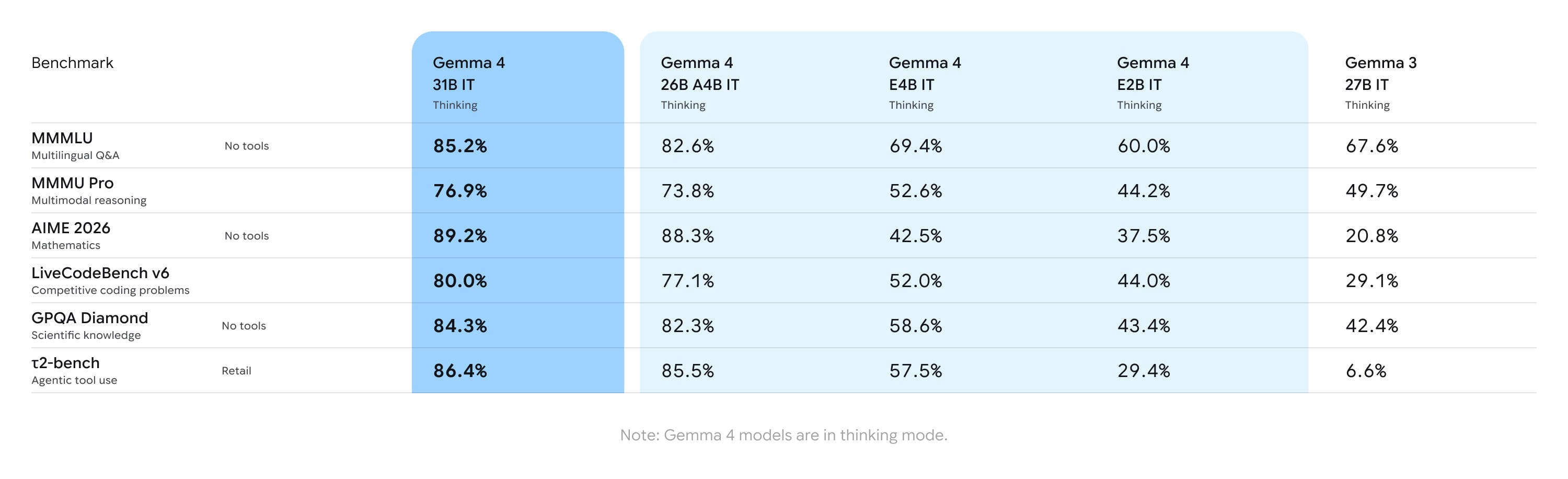
Here's a quick rundown of how Google says Gemma 4 compares to its last-gen open-weights models - Click to enlarge
But Gemma 4's most significant change is perhaps the switch to a more permissive Apache 2.0 license, which gives enterprises much more flexibility as to how and where they can use or deploy the models.
Previously, Google's Gemma license had prohibited use of the models in certain scenarios and reserved the right to terminate a user's access if they didn't play by the rules.
The move to Apache 2.0 now means enterprises can deploy the models without fear of Google pulling the rug out from under them.
Gemma 4 is available in Google's AI Studio and AI Edge Gallery services, as well as popular model repos like Hugging Face, Kaggle, and Ollama.
At launch, Google claims day-one support for more than a dozen inference frameworks including vLLM, SGLang, Llama.cpp, and MLX, to name a handful. ®
More about
More about
Narrower topics
- AIOps
- Amazon Bedrock
- Anthropic
- ChatGPT
- China Mobile
- China telecom
- China Unicom
- Cyberspace Administration of China
- DeepSeek
- Disaster recovery
- Gemini
- Google Brain
- GPT-3
- GPT-4
- Great Firewall
- Hong Kong
- Information Technology and the People's Republic of China
- JD.com
- Machine Learning
- MCubed
- Neural Networks
- NLP
- Open Compute Project
- PUE
- Retrieval Augmented Generation
- Semiconductor Manufacturing International Corporation
- Shenzhen
- Software defined data center
- Star Wars
- Tensor Processing Unit
- TOPS
- Uyghur Muslims
Broader topics
More about
More about
More about
Narrower topics
- AIOps
- Amazon Bedrock
- Anthropic
- ChatGPT
- China Mobile
- China telecom
- China Unicom
- Cyberspace Administration of China
- DeepSeek
- Disaster recovery
- Gemini
- Google Brain
- GPT-3
- GPT-4
- Great Firewall
- Hong Kong
- Information Technology and the People's Republic of China
- JD.com
- Machine Learning
- MCubed
- Neural Networks
- NLP
- Open Compute Project
- PUE
- Retrieval Augmented Generation
- Semiconductor Manufacturing International Corporation
- Shenzhen
- Software defined data center
- Star Wars
- Tensor Processing Unit
- TOPS
- Uyghur Muslims




