"OK Aura, Be Fair With Me": Demographics-Agnostic Training for Bias Mitigation in Wake-up Word Detection
arXiv cs.CL / 4/8/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The paper addresses demographic bias in wake-up word detection and tests whether demographics-agnostic training can improve fairness across sex, age, and accent groups.
- Experiments use the OK Aura database, with demographic labels excluded during training and reserved only for evaluation to avoid directly optimizing for fairness labels.
- The study evaluates two approaches: speech data augmentation to improve generalization and knowledge distillation from pre-trained foundational speech models to transfer robust representations.
- Results show large reductions in performance disparities, including a technique that cuts predictive disparity by 39.94% (sex), 83.65% (age), and 40.48% (accent) versus a baseline.
- Overall, the findings suggest label-agnostic methodologies can measurably reduce demographic bias and produce a more equitable wake-up word detection profile.
Related Articles
Research with ChatGPT
Dev.to
Silicon Valley is quietly running on Chinese open source models and almost nobody is talking about it
Reddit r/LocalLLaMA

Why AI Product Quality Is Now an Evaluation Pipeline Problem, Not a Model Problem
Dev.to
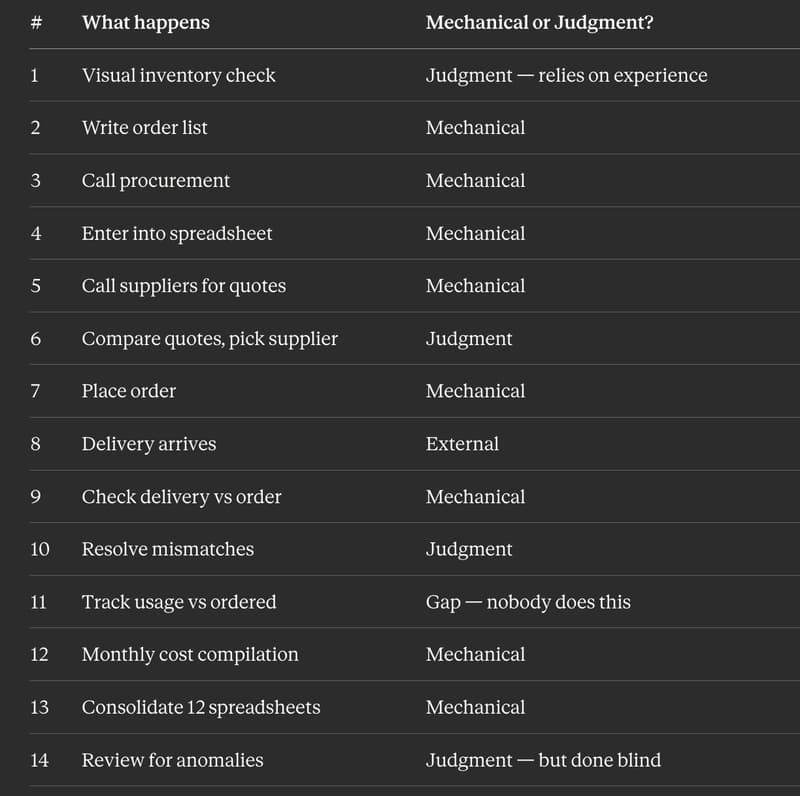
I Replaced 12 Kitchen Managers Guessing "How Much Chicken Do We Need" With 3 ML Models. Here's the Entire Architecture.
Dev.to

AI Model Router API - REST + MCP, Free Tier
Dev.to