LLM 0.32a0 is a major backwards-compatible refactor
29th April 2026
I just released LLM 0.32a0, an alpha release of my LLM Python library and CLI tool for accessing LLMs, with some consequential changes that I’ve been working towards for quite a while.
Previous versions of LLM modeled the world in terms of prompts and responses. Send the model a text prompt, get back a text response.
import llm model = llm.get_model("gpt-5.5") response = model.prompt("Capital of France?") print(response.text())
This made sense when I started working on the library back in April 2023. A lot has changed since then!
LLM provides an abstraction over thousands of different models via its plugin system. The original abstraction—of text input that returns text output—was no longer able to represent everything I needed it to.
Over time LLM itself has grown attachments to handle image, audio, and video input, then schemas for outputting structured JSON, then tools for executing tool calls. Meanwhile LLMs kept evolving, adding reasoning support and the ability to return images and all kinds of other interesting capabilities.
LLM needs to evolve to better handle the diversity of input and output types that can be processed by today’s frontier models.
The 0.32a0 alpha has two key changes: model inputs can be represented as a sequence of messages, and model responses can be composed of a stream of differently typed parts.
Prompts as a sequence of messages
LLMs accept input as text, but ever since ChatGPT demonstrated the value of a two-way conversational interface, the most common way to prompt them has been to treat that input as a sequence of conversational turns.
The first turn might look like this:
user: Capital of France?
assistant:
(The model then gets to fill out the reply from the assistant.)
But each subsequent turn needs to replay the entire conversation up to that point, as a sort of screenplay:
user: Capital of France?
assistant: Paris
user: Germany?
assistant:
Most of the JSON APIs from the major vendors follow this pattern. Here’s what the above looks like using the OpenAI chat completions API, which has been widely imitated by other providers:
curl https://api.openai.com/v1/chat/completions \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-5.5", "messages": [ { "role": "user", "content": "Capital of France?" }, { "role": "assistant", "content": "Paris" }, { "role": "user", "content": "Germany?" } ] }'
Prior to 0.32, LLM modeled these as conversations:
model = llm.get_model("gpt-5.5") conversation = model.conversation() r1 = conversation.prompt("Capital of France?") print(r1.text()) # Outputs "Paris" r2 = conversation.prompt("Germany?") print(r2.text()) # Outputs "Berlin"
This worked if you were building a conversation with the model from scratch, but it didn’t provide a way to feed in a previous conversation from the start. This made tasks like building an emulation of the OpenAI chat completions API much harder than they should have been.
The llm CLI tool worked around this through a custom mechanism for persisting and inflating conversations using SQLite, but that never became a stable part of the LLM API—and there are many places you might want to use the Python library without committing to SQLite as the storage layer.
The new alpha now supports this:
import llm from llm import user, assistant model = llm.get_model("gpt-5.5") response = model.prompt(messages=[ user("Capital of France?"), assistant("Paris"), user("Germany?"), ]) print(response.text())
The llm.user() and llm.assistant() functions are new builder functions designed to be used within that messages=[] array.
The previous prompt= option still works, but LLM upgrades it to a single-item messages array behind the scenes.
You can also now reply to a response, as an alternative to building a conversation:
response2 = response.reply("How about Hungary?") print(response2) # Default __str__() calls .text()
Streaming parts
The other major new interface in the alpha concerns streaming results back from a prompt.
Previously, LLM supported streaming like this:
response = model.prompt("Generate an SVG of a pelican riding a bicycle") for chunk in response: print(chunk, end="")
Or this async variant:
import asyncio import llm model = llm.get_async_model("gpt-5.5") response = model.prompt("Generate an SVG of a pelican riding a bicycle") async def run(): async for chunk in response: print(chunk, end="", flush=True) asyncio.run(run())
Many of today’s models return mixed types of content. A prompt run against Claude might return reasoning output, then text, then a JSON request for a tool call, then more text content.
Some models can even execute tools on the server-side, for example OpenAI’s code interpreter tool or Anthropic’s web search. This means the results from the model can combine text, tool calls, tool outputs and other formats.
Multi-modal output models are starting to emerge too, which can return images or even snippets of audio intermixed into that streaming response.
The new LLM alpha models these as a stream of typed message parts. Here’s what that looks like as a Python API consumer:
import asyncio import llm model = llm.get_model("gpt-5.5") prompt = "invent 3 cool dogs, first talk about your motivations" def describe_dog(name: str, bio: str) -> str: """Record the name and biography of a hypothetical dog.""" return f"{name}: {bio}" def sync_example(): response = model.prompt( prompt, tools=[describe_dog], ) for event in response.stream_events(): if event.type == "text": print(event.chunk, end="", flush=True) elif event.type == "tool_call_name": print(f" Tool call: {event.chunk}(", end="", flush=True) elif event.type == "tool_call_args": print(event.chunk, end="", flush=True) async def async_example(): model = llm.get_async_model("gpt-5.5") response = model.prompt( prompt, tools=[describe_dog], ) async for event in response.astream_events(): if event.type == "text": print(event.chunk, end="", flush=True) elif event.type == "tool_call_name": print(f" Tool call: {event.chunk}(", end="", flush=True) elif event.type == "tool_call_args": print(event.chunk, end="", flush=True) sync_example() asyncio.run(async_example())
Sample output (from just the first sync example):
My motivation: create three memorable dogs with distinct “cool” styles—one cinematic, one adventurous, and one charmingly chaotic—so each feels like they could star in their own story.
Tool call: describe_dog({"name": "Nova Jetpaw", "bio": "A sleek silver-gray whippet who wears tiny aviator goggles and loves sprinting along moonlit beaches. Nova is fearless, elegant, and rumored to outrun drones just for fun."}
Tool call: describe_dog({"name": "Mochi Thunderbark", "bio": "A fluffy corgi with a dramatic black-and-gold bandana and the confidence of a rock star. Mochi is short, loud, loyal, and leads a neighborhood 'security patrol' made entirely of squirrels."}
Tool call: describe_dog({"name": "Atlas Snowfang", "bio": "A massive white husky with ice-blue eyes and a backpack full of trail snacks. Atlas is calm, heroic, and always knows the way home—even during blizzards, fog, or confusing camping trips."}
At the end of the response you can call response.execute_tool_calls() to actually run the functions that were requested, or send a response.reply() to have those tools called and their return values sent back to the model:
print(response.reply("Tell me about the dogs"))
This new mechanism for streaming different token types means the CLI tool can now display “thinking” text in a different color from the text in the final response. The thinking text goes to stderr so it won’t affect results that are piped into other tools.
This example uses Claude Sonnet 4.6 (with an updated streaming event version of the llm-anthropic plugin) as Anthropic’s models return their reasoning text as part of the response:
llm -m claude-sonnet-4.6 'Think about 3 cool dogs then describe them' \
-o thinking_display 1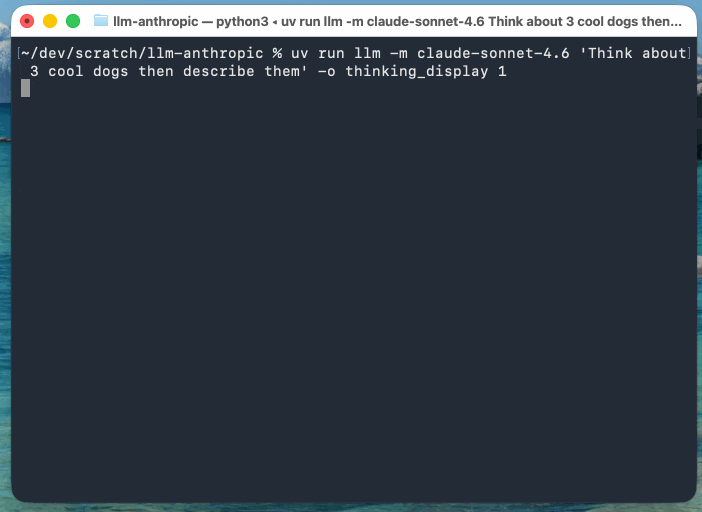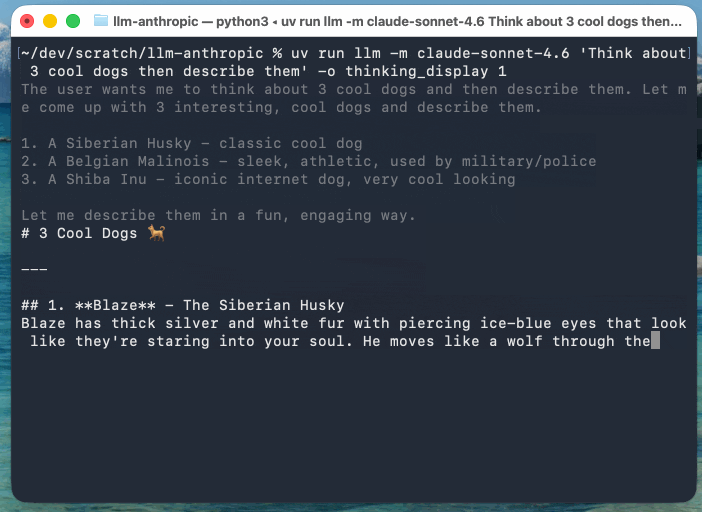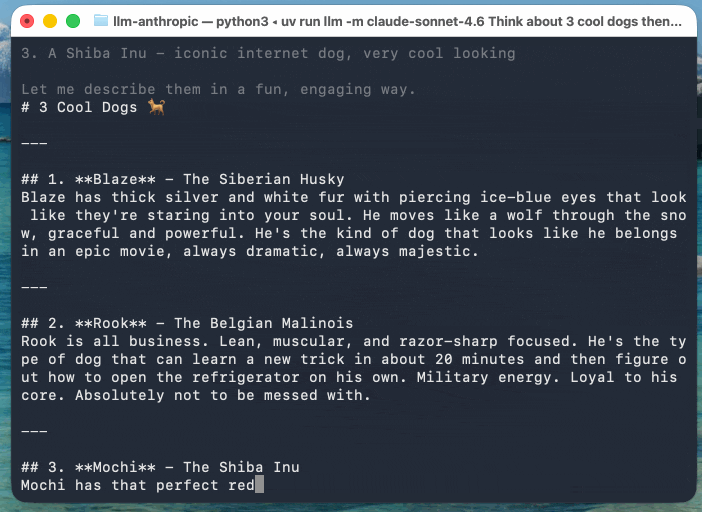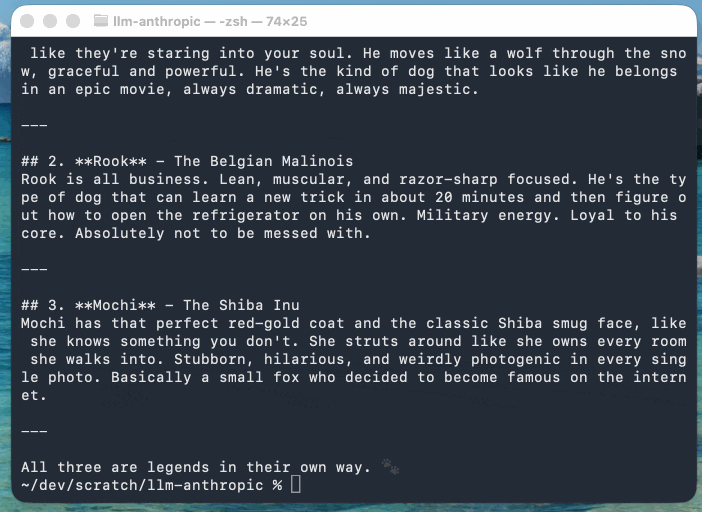
You can suppress the output of reasoning tokens using the new -R/--no-reasoning flag. Surprisingly that ended up being the only CLI-facing change in this release.
A mechanism for serializing and deserializing responses
As mentioned earlier, LLM has quite inflexible code at the moment for persisting conversations to SQLite. I’ve added a new mechanism in 0.32a0 that should provide Python API users a way to roll their own alternative:
serializable = response.to_dict() # serializable is a JSON-style dictionary # store it anywhere you like, then inflate it: response = Response.from_dict(serializable)
The dictionary this returns is actually a TypedDict defined in the new llm/serialization.py module.
What’s next?
I’m releasing this as an alpha so I can upgrade various plugins and exercise the new design in real world environments for a few days. I expect the stable 0.32 release will be very similar to this alpha, unless alpha testing reveals some design flaw in the way I’ve put this all together.
There’s one remaining large task: I’d like to redesign the SQLite logging system to better capture the more finely grained details that are returned by this new abstraction.
Ideally I’d like to model this as a graph, to best support situations like an OpenAI-style chat completions API where the same conversations are constantly extended and then repeated with every prompt. I want to be able to store those without duplicating them in the database.
I’m undecided as to whether that should be a feature in 0.32 or I should hold it for 0.33.
More recent articles
- Tracking the history of the now-deceased OpenAI Microsoft AGI clause - 27th April 2026
- DeepSeek V4 - almost on the frontier, a fraction of the price - 24th April 2026
This is LLM 0.32a0 is a major backwards-compatible refactor by Simon Willison, posted on 29th April 2026.
Part of series New releases of LLM
- Feed a video to a vision LLM as a sequence of JPEG frames on the CLI (also LLM 0.25) - May 5, 2025, 5:38 p.m.
- Large Language Models can run tools in your terminal with LLM 0.26 - May 27, 2025, 8:35 p.m.
- LLM 0.27, the annotated release notes: GPT-5 and improved tool calling - Aug. 11, 2025, 11:57 p.m.
- LLM 0.32a0 is a major backwards-compatible refactor - April 29, 2026, 7:01 p.m.
Previous: Tracking the history of the now-deceased OpenAI Microsoft AGI clause
Monthly briefing
Sponsor me for $10/month and get a curated email digest of the month's most important LLM developments.
Pay me to send you less!
Sponsor & subscribe


