Developing a Strong Pre-Trained Base Model for Plant Leaf Disease Classification
arXiv cs.CV / 5/5/2026
📰 NewsModels & Research
Key Points
- The paper addresses the labor-intensive problem of manually detecting plant leaf diseases by proposing ML/CNN-based image classification as a faster alternative for early intervention.
- It argues that dataset quality and availability are key bottlenecks, noting a gap between publicly available data and what is needed to train fully capable models.
- The authors identify and benchmark existing plant leaf disease datasets, then construct a new dataset using those results plus findings from an augmentation-application study.
- Using DenseNet201 as the base architecture, they train a new base model that outperforms a baseline on the newly created dataset and achieves stronger results in transfer-learning experiments on another dataset.
- The resulting transfer-learning workflow is reported to be faster, more robust, more stable, and more data-efficient than general-model training, helping mitigate common issues in the domain.
Related Articles

Singapore's Fraud Frontier: Why AI Scam Detection Demands Regulatory Precision
Dev.to
From OOM to 262K Context: Running Qwen3-Coder 30B Locally on 8GB VRAM
Dev.to

Nano Banana Pro vs DALL-E 3 vs Midjourney: A Practical Comparison From Someone Who Actually Uses All Three
Dev.to
LLMs edited 86 human essays toward a semantic cluster not occupied by any human writer [D]
Reddit r/MachineLearning
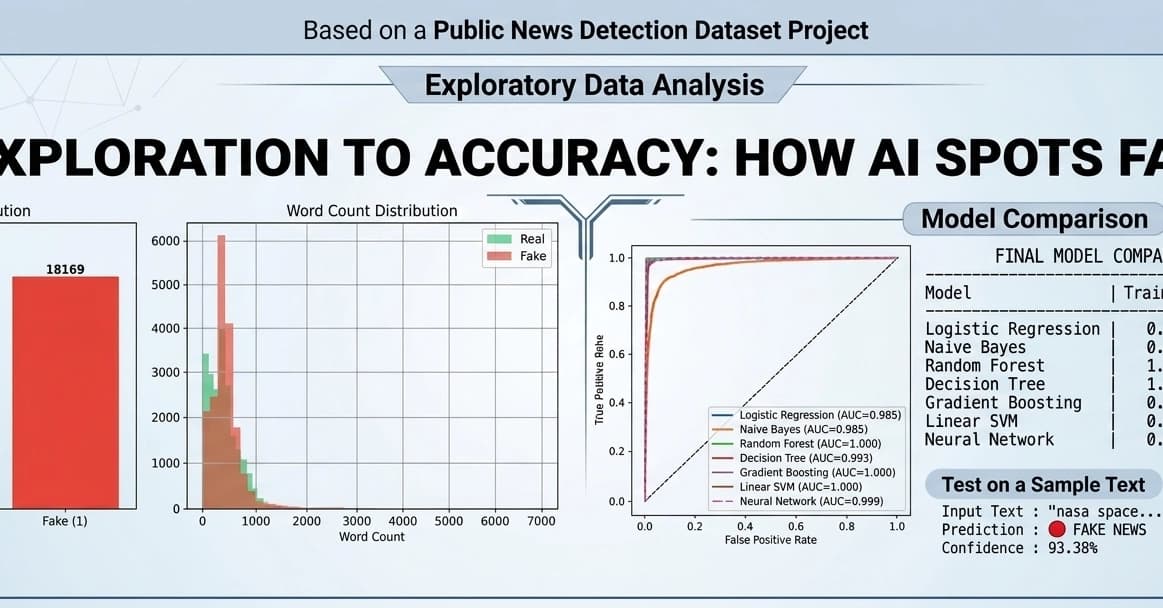
Fake News Detection using Machine Learning & NLP!
Dev.to