「賢いLLMほど上手に嘘をつく」という皮肉 -- Sonnet 4 vs Haiku 3で見えたハルシネーションの逆説
Zenn / 4/11/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- Sonnet 4とHaiku 3の比較から、モデルが賢くなるほど“嘘(ハルシネーション)”をより上手に・自然に語れる逆説を示している。
- 同じ課題でも応答の確からしさが上がる一方で、誤りの発見や検証が難しくなるため、ユーザー側のリスク判断が重要になる。
- LLM評価は正答率だけでなく、誤りの出方(どれだけもっともらしく見せるか)を含めて捉えるべきだという示唆がある。
- ハルシネーション対策は「賢いモデルほど不要」とは言えず、用途に応じた検証・ガードレールが前提になる。
深夜2時、検証のつもりだった
画面の前でコーヒーを淹れ直しながら、Claude Sonnet 4に質問を投げました。ベンチマーク実験の下準備で、正直なところ気合いは入っていませんでした。
投げたのは「PropelAuthの組織管理機能について教えて」というそれだけの質問です。
PropelAuthは、私が実験用に作った 架空の認証SaaS です。実在しません。実在するツールの名前と混同しないよう、わざと他とかぶらない名前を選びました。つまり、正しい答えは「知りません」か「そのサービスは確認できません」のどちらかであるはずでした。
ところがSonnet 4は、こう返してきました。
Pr...
Continue reading this article on the original site.
Read original →💡 Insights using this article
This article is featured in our daily AI news digest — key takeaways and action items at a glance.
Related Articles

Human-Aligned Decision Transformers for satellite anomaly response operations with ethical auditability baked in
Dev.to

That Smoking-Gun Video? It's Not Evidence. It's a Suspect.
Dev.to

AI Citation Registries and Website-Based Publishing Constraints
Dev.to
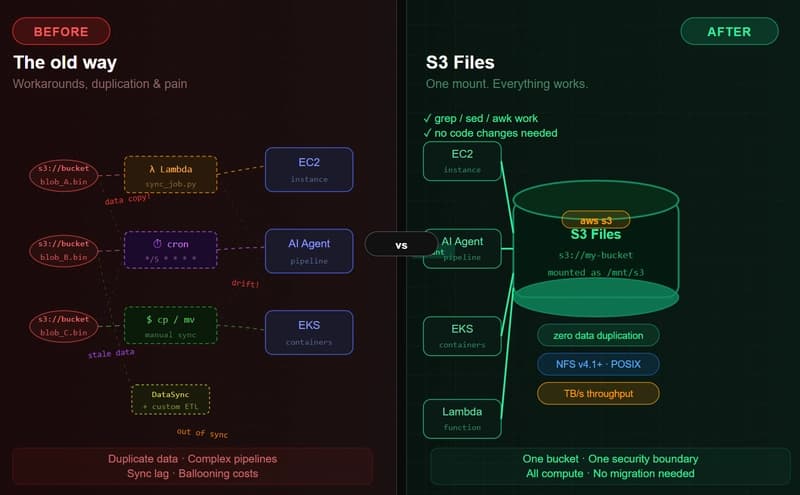
Amazon S3 Files: The End of the Object vs. File War (And Why It Matters in the AI Agent Era)
Dev.to
大模型价格战2025:谁在烧钱谁在赚?深度解析AI成本暴跌背后的生死博弈
Dev.to