
生成AIに引用されやすい文章は、何が違うのか

今回の研究は、文章の意味や内容そのものではなく、見出し、段落、箇条書き、表、強調表示といった文章の構造が、生成AIに引用される確率にどのように影響するのかを検証したものになります。
研究の方法
Yu, J et al. (2026). Structural feature engineering for generative engine optimization: How content structure shapes citation behavior.
従来の生成AIエンジン最適化(以下、GEO)の研究では、「権威的」な表現(研究によれば〜、専門家の見解では〜、エビデンスが示している、など)を入れる、統計に関連する具体的な数値を追加する、引用しやすい文体に整えるといった、文章自体の内容や表現の変更が主に扱われてきましたが [1] 、今回の研究は文章の内容ではなく、構造の部分にフォーカスしています。
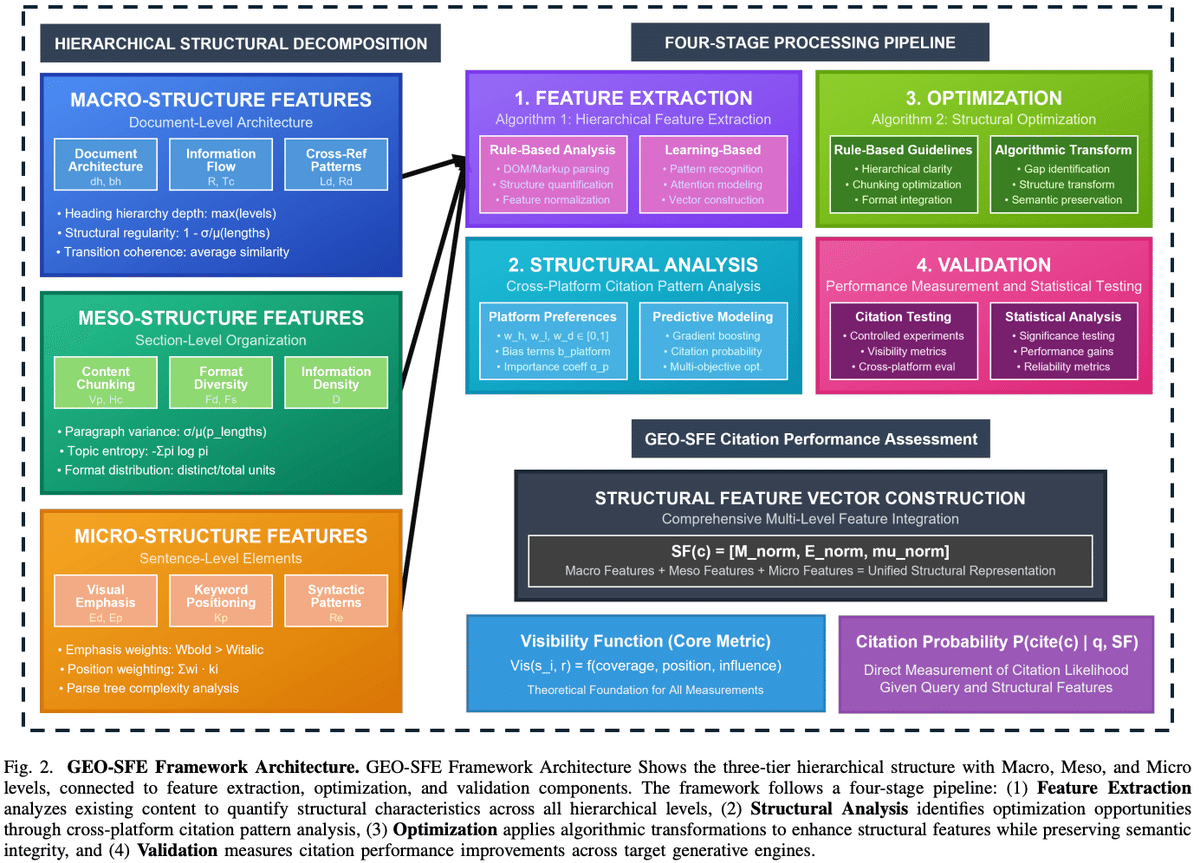
1. 文章を分解する
まず、著者らは文章の構造を以下の3つの階層に分けました。
Macro-structure(文書レベル)
見出し階層、ナビゲーション、内部リンク、文書全体の流れMeso-structure(節・段落レベル)
段落の長さ、箇条書き、表、情報のまとまり方Micro-structure(文レベル)
太字・斜体などの強調表示、キーワードの配置、構文のパターン(読みやすさ)
これらの文章の構造ごとに内容が評価されますが、評価の際は感覚や経験則ではなく、数値に変換されてから評価されます。
例えば、
見出しの深さ(どのくらい階層が深いか)
節の長さのばらつき(長い節と短い節のバランス)
段落ごとの情報の密度(短い文にどれだけ情報が詰まっているか)
強調の比率(太字・斜体などの割合)
内部リンクの密度(ページ内でどれだけ相互にリンクしているか)
こうした指標を組み合わせて、「構造特徴ベクトル」 という数値のまとまりに変換されたのち、文章が評価されます。
2. 生成AIのタイプによって、重みをつける
著者らは、生成AIのタイプによって引用のされやすさに影響する要素が異なると考え、大きく以下の3つに分けて、それぞれで重みを変えています。
検索してからまとめるタイプ
一度検索して、その結果をまとめて回答を作るタイプ(Google SGE、Bing Chat)繰り返し改善するタイプ
何度か検索を繰り返しながら、徐々に精度を上げていくタイプ(Perplexity AI、Phind)検索と生成を同時に行うタイプ
回答を生成しながら、リアルタイムで検索も行うタイプ(ChatGPT、Claude)
それぞれのタイプでは、AIが情報を読み取る順番や、どこに注目しやすいかが異なります。そのため、どの構造の特徴をどれだけ重視するか(重み)もタイプごとに変えています。
3. 文章の構造の最適化
実験に使う文章の最適化にあたっては、以下のような具体的な目安が示されています。
見出しの深さ:3~5階層くらい
段落の長さ:150~300語くらい
箇条書き・表などの要素の割合:全体の25~35%くらい
強調表示(太字・斜体など)の割合:5~10%くらい
内部リンクの密度:15~20%くらい
加えて、文の最初や節の境目など、AIが特に注目しやすい位置に重要なキーワードを置くことも重視されています。
一方で、著者らは「構造をいじっても、意味は変えてはならない」 という点も重視しており、次のようなルールを設けています。
文レベル:書き換え前後で、文の意味が大きく変わらないようにする
段落レベル:段落同士のつながりや話題の流れが維持されるようにする
文書レベル:全体を通してのトピックや情報の分布が大きく変わらないようにする
この制約を守りながら、「全体の構造→段落や書式→文」の順番で、大きな構造から小さな構造に向かって内容を最適化していきます。
そして、最終的に最適化された文書が、どの程度AIに拾われやすくなったのかを検証しています。
結果
1. 全体の結果
Yu, J et al. (2026). Structural feature engineering for generative engine optimization: How content structure shapes citation behavior.
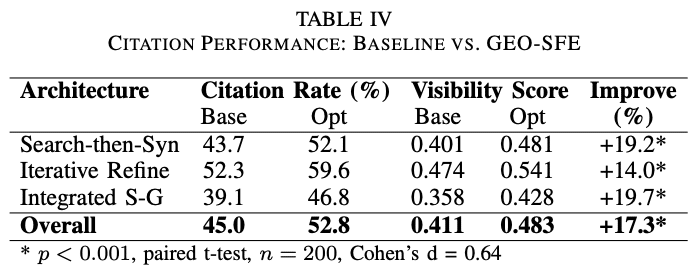
最適化された文章を用いることで、全体の引用率が45.0%から52.8%に上昇し、可視性も0.411から0.483に改善しました。改善率は平均17.3% (p < 0.001、効果量Cohen’s d = 0.64)と報告されており、統計的に有意に中程度の改善がみられたと解釈できます。
生成AIのタイプ別に見ると、検索してからまとめるタイプで43.7%→52.1%、検索と生成を同時に行うタイプで39.1%→46.8%と大きく改善が見られました。
つまり、内容を変えずに構造を整えるだけでも、生成AIに引用される確率が上がる可能性が示唆された、ということになります。
2. 読んだときの印象はどう変わったか
Yu, J et al. (2026). Structural feature engineering for generative engine optimization: How content structure shapes citation behavior.
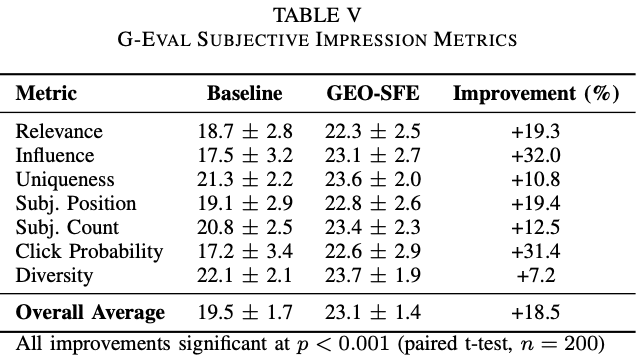
人間にアンケートを取る代わりに、生成AIに評価者役をさせて文章の質や印象を採点するG-Evalという方法を用いて、実際に文書を読んだときの印象も評価されています。
その結果、構造を最適化したバージョンは全体平均でスコアが18.5%向上し、特に伸びが大きかった項目を見てみると、影響力・説得力は32.0%、クリックされやすさは31.4%向上していました。
著者らはこのような結果が得られた理由として、文書全体の見通しが良くなったことと、箇条書きや表などの構造が整理されたことによって、情報の説得力や魅力が増加して見えたためであると解釈しています。
もちろん、これは実際の人間のクリック数ではなく、生成AIによる評価に基づいています。
それでも、構造を整えるだけで「読まれそう」「信頼できそう」という印象がこれだけ変わるのは、文章の構造の影響が無視できないことを示しています。
3. 文書の階層のうち、どの階層が重要だったか
Yu, J et al. (2026). Structural feature engineering for generative engine optimization: How content structure shapes citation behavior.
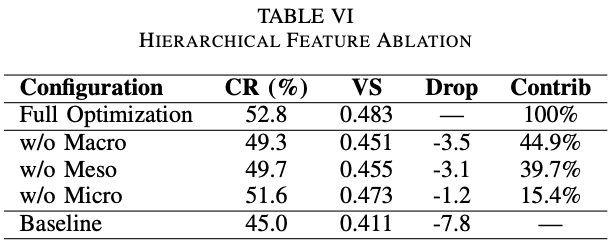
Table 6 の結果から、macro-structure(文書レベル)の寄与率が44.9%と最も高く、meso-structure(節・段落レベル)は39.7%、micro-structure(文レベル)は15.4%という結果になりました。
つまり、細かい書体(太字、斜体など)やキーワードの位置より、文書全体の見出しの構造や文章の流れのほうが重要であるということが示唆されました。
注意点
対象となった生成AIは6種類ですが、これらは仕様の変化が早く、今回の結果が今後も参考になるとは限りません。
読んだときの印象の評価は生成AIによるもののため、実際の人間が読んだ場合は異なる評価になる可能性も考えられます。
生成AIが引用したからといって…
今回の研究では、文章の内容の適切な構造化により、6種類の生成AIで平均17.3%の引用率の改善が見られたと報告されていますが、これは正しい情報がより多く引用されたという意味ではなく、構造の改善により生成AIに拾われやすくなったことを示唆する結果です。
言い換えると、AIが引用した内容の正確さまでは保証されていないことに注意が必要ということになります。
恐らく生成AIは、複数の情報を統合して回答を生成する過程で、明らかに信憑性に欠ける情報を除外している可能性はありますが、それでも引用された情報全てが正確である保証はありません。
ゆえに、AIに引用されたこと自体を情報源の正確さの根拠とすべきではなく、必ず自分の目でその内容を確認する必要があります。
例えば、薬局内の文書をNotebookLM等で管理するとき
今回の研究の内容は、noteやブログなどで全世界に向けて情報を発信する時に役立つ考え方に見えますが、この考え方はNotebookLM等で薬局内の文書を管理するときにも応用できると考えられます。
例えば、文書の階層ごとに分けて考えると、以下のような改善案が有効かもしれません。
文書レベルの改善
NotebookLMに資料をアップロードするときは1ファイル1テーマを意識する、資料の見出しを整理する、冒頭に結論を書く、例外は最後に独立させて書く、よくある質問をまとめる節・段落レベルの改善
長文で書くより、「基本手順」「例外」「記録の方法」「よくあるミス」のように区切り、必要に応じて箇条書きや表にする文レベルの改善
見出しや文章のテキストを、実際に利用する側(スタッフ)が質問として入力しそうな内容にする、表記揺れを減らして表現を統一する
以前投稿した記事で、NotebookLMは「人間に対して根拠を提示する補助ツールとしては、有用である可能性が高い」とお伝えしましたが、このような工夫により、さらに正確に情報を引用してくれるようになるかもしれません。
ただし、これらの工夫でより良い出力を得るためには、アップロードする資料自体の品質が保証されていなければなりません。
ゆえに、最初に資料をアップロードするときは人間側が責任を持って品質をチェックし、アップロードした後も必要に応じて内容を改訂するなどして、常に最新かつ正確な情報源がNotebookLMにアップロードされている状態を維持しましょう。
<関連記事>
参考文献
[1] Kumar, A., & Lakkaraju, H. (2024). Manipulating large language models to increase product visibility. arXiv:2404.07981.
最後までお読みいただき、ありがとうございました。
Webサイト「薬剤師のためのAIノート」も、是非ご覧ください。
記事に関する内容以外のお問い合わせは、以下のフォームよりお願いいたします。
また、書籍「超知能時代の調剤薬局」発売中です。
Kindle Unlimited会員の方は無料で読むことができます。



