Dear friends,
The anti-AI coalition continues to maneuver to find arguments to slow down AI progress. If someone has a sincere concern about a specific effect of AI, for instance that it may lead to human extinction, I respect their intellectual honesty, even if I deeply disagree with their position. However, I am concerned about organizations that are surveying the public to find whatever messages will turn people against AI, and how the public reacts as these messages are spread by lobbyists or by politicians seeking to alarm constituents, companies pursuing regulatory capture or seeking to promote the power of their technology, and individuals seeking to gain attention or to profit by being provocative.
A large study (hat tip to the AI Panic blog) by a UK group tested different messages that are designed to raise alarm about AI. Their study found that saying AI will cause human extinction has largely failed. Doomsayers were pushing this argument a couple of years ago, and fortunately our community beat it back. But AI-enabled warfare and environmental concerns resonate better. We should be prepared for a flood of messages (which is already underway) arguing against AI on these grounds. Further, job loss and harm to children are messages that motivate people to act.
To be clear, I find AI-enabled warfare alarming; we need to continue serious efforts to monitor and mitigate the environmental impact of AI; any job losses are tragic and hurt individuals and families; and as a father, I hold dearly the importance of every child’s welfare. Each of these topics deserves serious attention and treatment with the greatest of care.
But when anti-AI propagandists take a one-sided view of complex issues to benefit their own organizations at the expense of the public at large — for instance, when big AI companies argue that AI is dangerous to block the free distribution of open source projects that compete with their offerings — then we all lose.
For example, public perception of data centers’ environmental impact is already far worse than the reality — data centers are incredibly efficient for the work they do, and hampering their buildout will hurt rather than help the environment. While job loss is a real problem, the “AI washing” of layoffs — in which businesses that had over-hired during the pandemic blame AI for recent layoffs, although AI hasn’t yet affected their operations — has led to overblown fears about the impact of AI on employment.

Unfortunately, this sort of propaganda easily leads to regulations that create worse outcomes for everyone. For example, oil companies worked for years to create fear of nuclear energy. The result is that overblown concerns about the safety of nuclear power plants has stifled nuclear power development, leading to millions of premature deaths from air pollution that was caused by other energy sources and a massive increase in CO2 emissions. Let’s make sure overblown concerns about AI do not lead to a similar fate for the many people that would benefit from faster AI development.
This week, the White House proposed a national legislative framework for AI. A key component is a federal preemption framework to prevent a patchwork of state regulations that hamper AI development. I support this.
After failing to gain traction at the federal level, a lot of anti-AI propaganda has shifted to the state level. If just one of the 50 states passes a law that limits AI in an unproductive way, it could lead to stifling AI development across all the states and potentially across the globe. The White House proposal rightfully respects each state’s rights to control its own zoning, how it enforces general laws to protect consumers, and how it uses AI. But if a state were to pass laws that limit AI development, federal rules would preempt the state law.
The White House proposal remains a proposal for now. However, if the U.S. Congress enacts it, it will clear the way for ongoing efforts to develop AI in beneficial ways.
Where do we go from here? Let’s support limiting applications — those that use AI, and those that don’t — that harm people. When the anti-AI coalition argues against AI, in addition to considering the merits of the argument, I consider whether their position is consistent and persuasive, or if they are just promoting whatever concerns they think will sway the public at a given moment. And, let’s also keep using a scientific approach to weighing AI’s benefits against likely harms, so we don’t end up with overblown concerns that limit the benefits that AI can bring everyone.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

“Agent Skills with Anthropic” shows you how to make agents more reliable by moving workflow logic out of prompts and into reusable skills. Learn how to design and apply skills across coding, data analysis, research, and other workflows. Sign up here!
News
Open-Source Speed Demon
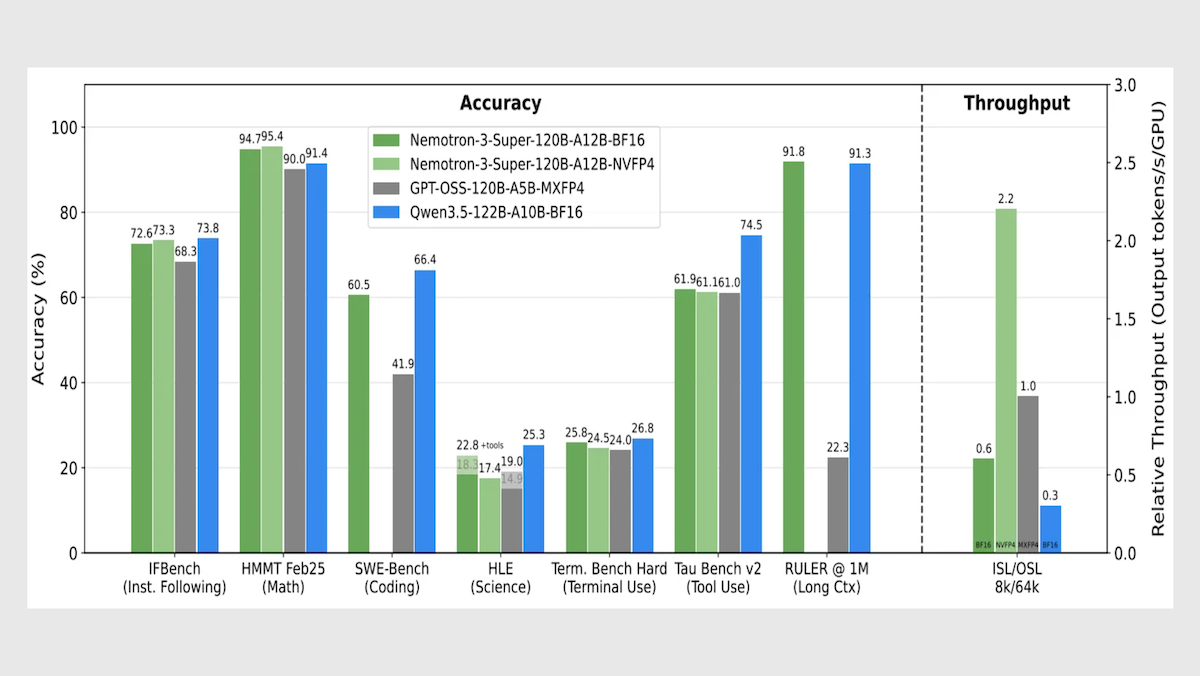
Nvidia, the dominant supplier of AI chips, released a competitive open-source large language model whose speed tops its size class — the first open-weights leader to come from the United States since last year, when Meta delivered Llama 4.
What’s new: Nvidia released Nemotron 3 Super 120B-A12B, a large language model designed for agentic applications, including not only weights but also training datasets and recipes. It is the second in a planned family of three: Nvidia released Nemotron 3 Nano-39B-A3B in December 2025, and Nemotron 3 Ultra-500B-A50B is forthcoming.
- Input/output: Text in (up to 1 million tokens), text out (up to 1 million tokens)
- Knowledge cutoff: June 2025 (pretraining data), February 2026 (fine-tuning data)
- Architecture: Hybrid mamba-2/transformer/mixture-of-experts with multi-token prediction layers (120 billion parameters, 12 billion active per token)
- Training data: 25 trillion tokens of curated data scraped from the web and synthesized in 20 natural languages and 43 programming languages
- Features: Tool calling, structured outputs, seven languages (Chinese, English, French, German, Italian, Japanese, Spanish), reasoning modes (off, low, regular)
- Performance: Fastest open-weights model of its size (442 output tokens per second), leads open-weights models on PinchBench test of agentic tasks
- Availability/price: Weights and datasets free to download under a license that permits noncommercial and commercial uses (rights terminate if safety guardrails are removed without replacement or if the user files patent or copyright litigation against Nvidia), free chat via Nvidia and OpenRouter, API around $0.30/$0.80 per 1 million tokens of input/output via third-party providers
How it works: Nemotron 3 Super’s hybrid architecture interleaves mamba-2, attention, and modified MoE layers with multi-token prediction heads that generate a number of tokens per forward pass.
- Most of Nemotron 3 Super’s layers are mamba-2 layers. Unlike attention layers, which consume quadratically more processing power as input length increases, mamba-2 layers compress earlier context into a compact representation at each step. Nemotron 3 Super interleaves attention layers selectively to handle tasks that require precise retrieval from distant parts of an input, which mamba-2 layers struggle with.
- The MoE layers use Nvidia’s LatentMoE design that compresses each token's representation to 1/4 its usual size before the MoE router decides which experts to activate. This compression enables the model to actiate 22 experts per token using roughly the same amount of processing power as five or six experts typically would require.
- Multi-token prediction (MTP) heads predict multiple output tokens per forward pass. During training, this encourages the model to learn longer-range patterns. During inference, the MTP heads accelerate output by drafting tokens that the model verifies in a single pass. It keeps those that are consistent with its probability distributions and discards the rest.
- The team pretrained in NVFP4, the 4-bit floating-point numerical format that’s built into Nvidia Blackwell GPU architecture, so the model learned to work with reduced precision rather than being quantized after training.
- The team fine-tuned the model on more than 7 million sequences that comprised a prompt, reasoning, tool calls, and final output. The sequences were generated by DeepSeek V3.2 and Kimi K2 for some tasks, including math, code, and multilingual queries, and by Qwen3-Coder-480B for software engineering tasks. Reinforcement learning followed in three stages: tasks with objectively verifiable outputs in domains such as math, coding, science, puzzles, and agentic tool use; a dedicated software engineering stage in which the model solved GitHub issues using test execution as a reward signal; and reinforcement learning from human feedback to improve conversational quality. The team described its PivotRL fine-tuning approach in a paper.
Performance: Nemotron 3 Super leads its size class in speed and processing long contexts, with competitive metrics in overall intelligence and agentic tasks.
- Nemotron 3 Super set to reasoning (level unspecified) generates roughly 442 tokens per second, well ahead of OpenAI gpt-oss-120b set to high reasoning (278 tokens per second) and Google Gemini 3.1 Flash-Lite set to reasoning (266 tokens per second).
- On Artificial Analysis’ Intelligence Index, a weighted average of 10 benchmarks that focus on economically useful work, Nemotron 3 Super set to reasoning (36) fell behind Qwen3.5-122B set to reasoning (42) but outperformed gpt-oss-120b set to high reasoning (33).
- On RULER, a long-context evaluation developed by Nvidia, given 1 million input tokens, Nemotron 3 Super (91.75 percent accuracy) slightly outperformed Qwen3.5-122B (91.33 percent accuracy) and came out well ahead of gpt-oss-120b (22.30 percent a accuracy).
- On PinchBench, which evaluates how well a model completes tasks as the decision-making core of an autonomous agent (OpenClaw), Nemotron 3 Super (85.6 percent) outperformed much larger open-weights contenders including the 1 trillion-parameter Kimi K2.5 (84.8 percent) and the 744 billion-parameter GLM-5 (84.1 percent), as well as the similarly sized Qwen3.5-122B (84.5 percent).
Behind the news: Nvidia plans to invest $26 billion over five years to develop open-weights models — a substantial commitment. The announcement coincides with shifts in the open-weights landscape that could affect Nvidia’s business. Chinese companies, including Alibaba, Moonshot AI, and Z.ai, lately have built the most capable open-weights models, and they are building alternatives to Nvidia GPUs and Cuda software. For instance, DeepSeek has reportedly trained an upcoming model entirely on Huawei’s Ascend chips and Cann software.
Why it matters: Nemotron 3 Super gives developers a fast, fully open model for agentic applications, with training data, recipes, and tools alongside the weights. This openness also serves Nvidia’s business goals. Chinese open-weights models are growing more capable and increasingly streamlined to run on non-Nvidia chips, creating a risk that developers who previously relied on Nvidia will look elsewhere. Nemotron gives them a reason not to.
We’re thinking: Who better to optimize a model for GPUs than the company that designs the GPUs? From custom numerical formats to inference software, Nvidia can co-design hardware and software in ways that few model developers can match. Nvidia is betting that building models will help sell chips and vice versa.

OpenAI Tracks Agent States on AWS
OpenAI partnered with Amazon to build infrastructure for agents on the world’s largest cloud platform, a further sign that its close relationship with Microsoft is weakening.
What’s new: OpenAI and Amazon announced a “stateful runtime environment,” a forthcoming computing infrastructure designed for AI agents. The companies did not disclose the projected launch date. The partnership diversifies OpenAI’s cloud-computing resources beyond Microsoft Azure and lets Amazon use OpenAI models in its own products. As part of the deal, Amazon invested $15 billion in OpenAI with an additional $35 billion to come if certain undisclosed conditions are met, or if OpenAI offers it stock to the public prior to 2029, according to an analysis of related documents by GeekWire. Moreover, if the cloud partnership terminates, Amazon’s remaining $35 billion commitment will die with it. The investment was a part of a gargantuan $110 billion funding round that included Nvidia and Softbank and valued OpenAI at $730 billion. (Disclosure: Andrew Ng is a member of Amazon’s Board of Directors.)
- OpenAI and Amazon Web Services (AWS) will develop a stateful runtime environment that will run on Amazon Bedrock, Amazon’s platform for building and deploying AI applications. Expected to launch within months, the environment is designed to manage agents’ working states including memories, tool connections, and user permissions.
- AWS is the exclusive third-party cloud provider of OpenAI Frontier, a platform for building, deploying, and managing AI agents across a company. Customers who buy Frontier through Amazon will be served via Amazon Bedrock, while those that buy directly from OpenAI will be served via Microsoft Azure.
- OpenAI and Amazon will develop custom models for Amazon’s products.
- OpenAI committed to use Amazon Trainium chips, which are designed by Amazon for AI workloads). OpenAI promised to consume 2 gigawatts’ worth of Tranium processing, expanding its previous $38 billion agreement with AWS by $100 billion over 8 years.
How it works: Many developers interact with AI models through stateless APIs for which each request is independent. A developer sends a prompt, receives a response, and the model retains no memory of the exchange, so developers must pass all context into every request. The stateful runtime environment aims to handle that context, helping agents to execute long, multi-step workflows without losing track of where they are. In addition, customers will have access to customized versions of open-weights OpenAI models that run on AWS, The Information reported.
- OpenAI argues that stateless APIs are insufficient for AI agents in production, which depend on outputs from multiple tools, require human approvals, and must resume if they’re interrupted.
- The distinction between stateful and stateless — a typical attribute of APIs — also serves a legal purpose. The agreement between OpenAI and Microsoft makes Azure the exclusive host for OpenAI’s stateless APIs, but a runtime environment falls outside the scope of Microsoft’s right. Azure will host stateless API calls to OpenAI models that arise from the Amazon collaboration
- The environment will be integrated with Amazon Bedrock AgentCore, Amazon’s tools for deploying and managing AI agents, and will run in customers’ existing environments with AWS.
Behind the news: The partnership between OpenAI and Amazon marks the latest step in the dissolution of the tight cloud partnerships that defined the early generative AI era. In 2019, Microsoft invested $1 billion (which subsequently rose beyond $13 billion) in OpenAI and became its exclusive cloud provider. In 2023, Amazon invested up to $4 billion in Anthropic and became its primary cloud provider. Each deal paired an AI startup with a cloud giant. Both ties have since loosened.
- By late 2024, both Microsoft and OpenAI were working to reduce their interdependence, as OpenAI’s needs outstripped the computational resources Microsoft was willing to build, and Microsoft put more attention into developing its own AI capabilities.
- In October 2025, when OpenAI restructured itself as a for-profit public benefit corporation, the terms gave Microsoft a 27 percent stake and 20 percent of OpenAI’s revenue but removed its right of first refusal on cloud business, freeing OpenAI to work with other providers.
- On the day the Amazon deal was announced, Microsoft and OpenAI issued a joint statement that their partnership was ongoing. Microsoft retains its exclusive access to OpenAI’s intellectual property, such as model weights, and will continue to share in revenue from OpenAI’s partnerships with other cloud providers.
- A mirror image has played out on Amazon’s side. Anthropic, Amazon’s primary AI partner, had been on Google Cloud since before Amazon invested in it, and later it expanded to Microsoft. In November 2025, Microsoft invested up to $5 billion in Anthropic and made Claude models available on Azure, making Claude the first leading model family available on all three major cloud platforms.
- According to documents filed with the U.S. Securities Exchange Commission and reviewed by GeekWire, Amazon’s equity investment and cloud partnership are contractually linked. If the agreement terminates, Amazon’s remaining $35 billion commitment will die with it.
Why it matters: Developers who build AI agents typically build their own state management, tool orchestration, and fault recovery on top of stateless APIs. A runtime environment that’s designed to handle these functions as infrastructure could lower the barrier to deploying AI agents. On the flip side, depending on exactly what state is stored and how portable it is, it may increase the cost to switch to a different cloud vendor. That it will run on AWS, the largest cloud provider by market share, will make it available to a wide swath of the developer community.
We’re thinking: Distinguishing between stateless and stateful may be clever legal engineering, but it also reflects a real technical shift. As AI applications move toward autonomy, the infrastructure behind agents may matter as much as the models.

xAI’s Cost-Effective Video Generator
xAI launched a video generator that topped an independent quality ranking at a fraction of competitors’ prices.
What’s new: Grok Imagine 1.0 takes text with images and/or video, and produces video clips that can include dialogue, sound effects, and music.
- Input/output: Text, image (optional), video (optional) in, video with audio out (up to 10 seconds at 1,280x720 pixels via chat interfaces, up to 15 seconds at 1,280x720 pixels or 854x480 pixels via API)
- Performance: Topped Artificial Analysis Video Arena in both text-to-video and image-to-video at launch
- Capabilities: Video alteration via text instructions, camera motion (pan, tilt, zoom); add, remove, and swap objects within scenes; style transfer; multiple aspect ratios
- Availability/price: Web interface via grok.com, x.com, and Grok mobile app (free for X Basic and Premium users; Premium users can generate longer videos), API $4.20 per minute of output
- Undisclosed: xAI disclosed no information about Grok Imagine 1.0’s underlying technology and how it was built.
Performance: Grok Imagine 1.0 debuted at the top of the Artificial Analysis Video Arena, a blind, head-to-head test of preferences judged by human viewers. It’s slower than some competitors but generally less expensive. (Disclosure: Andrew Ng has a personal investment in Artificial Analysis.)
- At launch, Artificial Analysis’ leaderboards ranked Grok Imagine 1.0 first in both the text-to-video and image-to-video categories, ahead of Runway Gen-4.5, Kling 2.5 Turbo, and Google Veo 3.1.
- On LM Arena’s video leaderboards, grok-imagine-video-720p ranked first in image-to-video (1,400 Elo), ahead of Google Veo 3.1 (1,395 Elo), and fourth in text-to-video (1,362 Elo), behind Google Veo 3.1 (1,371 Elo) and OpenAI Sora 2 Pro (1,369 Elo).
- In xAI’s head-to-head tests using IVEBench (which evaluates the quality of instruction-guided video alterations), human raters preferred Grok Imagine 1.0 over Runway Aleph (64.1 percent of the time) and Kling O1 (57 percent of the time).
- According to Artificial Analysis, on average, Grok Imagine 1.0 generated a video (duration unspecified) in 110.1 seconds, slower than Kling 2.5 Turbo (89.2 seconds) and Vidu Q2 (39.1 seconds) but faster than OpenAI Sora 2 Pro (448.4 seconds) and MiniMax Hailuo 2.3 (167.1 seconds).
- At $4.20 per minute of generated video (with audio), Grok Imagine 1.0 matches the price of Kling 2.5 Turbo (without audio) and costs less than Google Veo 3.1 Preview ($12 per minute with audio) and OpenAI Sora 2 Pro ($30 per minute with audio).
Behind the news: Unlike video generators from Google, OpenAI, and Runway, which are available as standalone products and/or via APIs, Grok Imagine 1.0 is integrated with the X social network. This enables X users to generate and share video directly on X, where they have caused controversy. In late 2025, X users exploited Grok to produce nonconsensual sexualized images of real people, including children, resulting in investigations and bans in several countries. The phenomenon persisted after xAI promised to address it, Reuters reported.
Why it matters: Generating a video that matches your vision typically requires many iterations of adjusting prompts, regenerating, and comparing results. xAI says that early partners told the company that quality alone was not useful if latency and cost made iteration untenable. Third-party benchmarks show Grok Imagine 1.0 matches or exceeds leading models on quality at a lower cost than premium competitors, a combination that lowers the cost of experimentation.
We’re thinking: Image generation went from novelty to table stakes in roughly two years. Video generation is following a similar path. The seven-fold price gap between Grok Imagine 1.0 and the now-shuttered OpenAI Sora 2 Pro suggests that prices still have plenty of room to fall.
Context As An External Variable
When processing long contexts, large language models often lose track of details or devolve into nonsense. Researchers reduced these effects by managing context externally.
What’s new: MIT’s Alex L. Zhang, Tim Kraska, and Omar Khattab developed Recursive Language Models (RLMs) that process long prompts encountered in books, web searches, and codebases by offloading prompts to an external environment and managing them programmatically.
Key insight: A language model can process long inputs, including inputs larger than its context window, by treating input text as a persistent variable in an external programming environment. The model can write code to fetch only the necessary chunks of text. For example, it can look for keywords and retrieve the paragraphs that surround them. Writing code Iteratively enables the model to break down long-context tasks into sub-tasks before approaching the tasks as a whole.
How it works: RLMs read and manipulate tasks (a user’s prompt and associated documents) using Python code execution in a simple read-evaluate-print loop (REPL) environment. The tasks involved analyzing, understanding, or retrieving details from long documents. The model generated a program that invoked new instances of itself, or submodels, to handle each subtask and fed each instance’s output back into the root model.
- The authors built RLM systems based on Qwen3-8B (which has a 32,768-token context window), GPT-5 (400,000-token context window), and Qwen3-Coder-480B (256,000-token context window). Each system comprised a model and a custom agentic framework that read and wrote to a Python environment and called submodels.
- The RLM systems loaded task data into a Python interpreter as a variable rather than feeding it directly into the model.
- A system prompt instructed the root model to generate Python code to interact with the REPL environment and address stored tasks. For example, the model inspected the length of a prompt, found keywords, split it into logical chunks (like chapters or sections), and called a different submodel to answer questions about each chunk.
- Each submodel processed its chunk according to the root model’s instructions or questions and passed its results back to the root model.
- The system stored the submodels’ outputs as variables. The root model used these intermediate results to construct its final output.
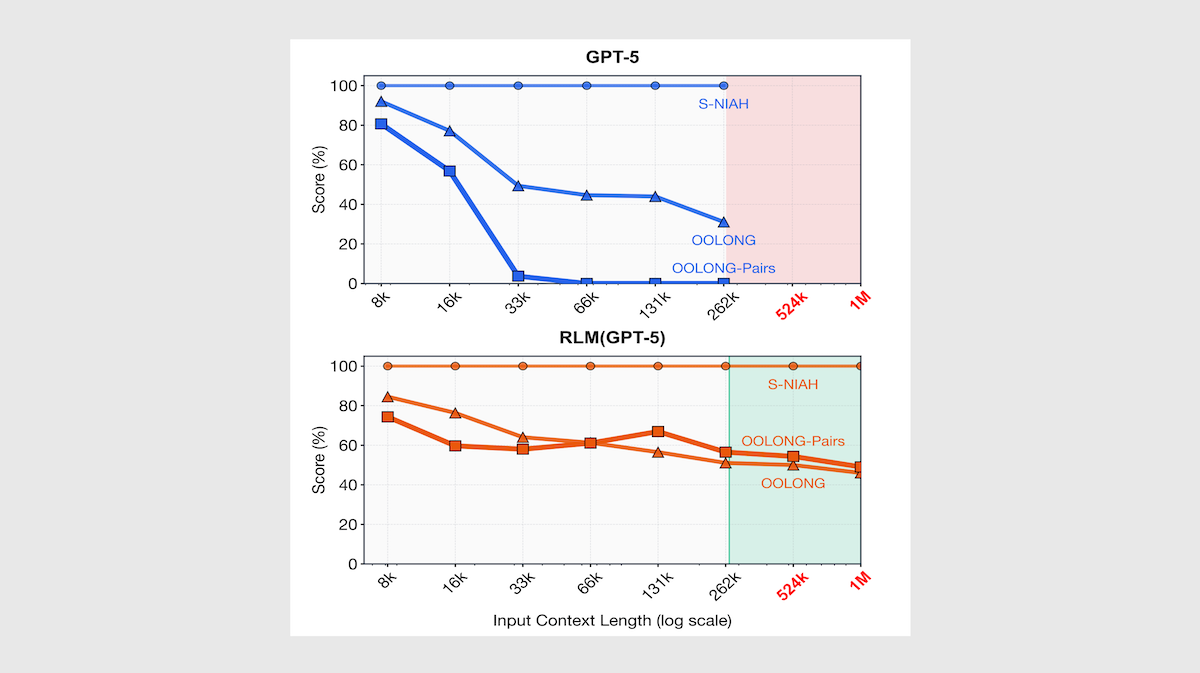
Results: The authors compared RLMs based on Qwen3-8B, GPT-5 with medium reasoning, and Qwen3-Coder-480B to the original models using using benchmarks that involve retrieval and reasoning over documents up to 1 million tokens long. They also compared the RLMs to CodeAct agents with retrieval tools and custom agents that compacted or summarized context. The RLMs significantly outperformed both the stock models and other agentic strategies on tasks that require understanding of multiple documents, up to 11 million tokens total.
- On BrowseComp+, a question-answering benchmark that requires reasoning over multiple documents, the RLM-GPT-5 (91.3 percent accuracy) outperformed GPT-5, which ran into context length limitations and was unable to produce an answer. It also outperformed the summary agent that used GPT-5 (70.5 percent accuracy). Similarly, RLM-Qwen3-Coder-480B (44.7 percent accuracy) outperformed Qwen3-Coder-480B with a summary agent (38.0 percent accuracy). RLM-Qwen3-8B (14 percent accuracy) outperformed Qwen3-8B (0 percent accuracy.)
- The authors tested the models on OOLONG-PAIRS, a version of the OOLONG long-context reasoning benchmark. OOLONG-PAIRS requires aggregating paired chunks to construct a final output (for instance, “list all pairs of user IDs […] where both users have at least [a value or location]”). RLM-GPT-5 (58 percent accuracy) outperformed GPT-5 (nearly 0 percent accuracy) and retrieval and summary agents (about 0.3 percent accuracy) at 32,000 tokens of context. RLM-GPT-5 maintained approximately 50 percent accuracy even at 1 million tokens of context. RLM-Qwen3-8B (5.2 percent accuracy) outperformed Qwen3-8B (0 percent accuracy) at 32,000 tokens of context.
Why it matters: Earlier approaches often handle long contexts by using retrieval or summarization, which can lose critical details. By decomposing tasks into recursive sub-calls, a model can maintain high precision across more tokens. This method provides a blueprint for building agents that can reason coherently over numbers of tokens that far exceed a model’s input limit.
We’re thinking: An RLM pays attention only to the parts of the context it needs at any given moment. This approach seems akin to the human method of processing long documents one section at a time.
