Dear friends,
AI-native software engineering teams operate very differently than traditional teams. The obvious difference is that AI-native teams use coding agents to build products much faster, but this leads to many other changes in how we operate. For example, some great engineers now play broader roles than just writing code. They are partly product managers, designers, sometimes marketers. Further, small teams who work in the same office, where they can communicate face-to-face, can move incredibly quickly.
Because we can now build fast, a greater fraction of time must be spent deciding what to build. To deal with this project-management bottleneck, some teams are pushing engineer:product manager (PM) some teams are pushing engineer:product manager (PM) ratios downward from, say, 8:1 to as low as 1:1. But we can do even better: If we have one PM who decides what to build and one engineer who builds it, the communication between them becomes a bottleneck. This is why the fastest-moving teams I see tend to have engineers who know how to do some product work (and, optionally, some PMs who know how to do some engineering work). When an engineer understands users and can make decisions on what to build and build it directly, they can execute incredibly quickly.
I’ve seen engineers successfully expand their roles to including making product decisions, and PMs expand their roles to building software. The tech industry has more engineers than PMs, but both are promising paths. If you are an engineer, you’ll find it useful to learn some product management skills, and if you’re a PM, please learn to build!
Looking beyond the product-management bottleneck, I also see bottlenecks in design, marketing, legal compliance, and much more. When we speed up coding 10x or 100x, everything else becomes slow in comparison. For example, some of my teams have built great features so quickly that the marketing organization was left scrambling to figure out how to communicate them to users — a marketing bottleneck. Or when a team can build software in a day that the legal department needs a week to review, that’s a legal compliance bottleneck. In this way, agentic coding isn’t just changing the workflow of software engineering, it’s also changing all the teams around it.

When smaller, AI-enabled teams can get more done, generalists excel. Traditional companies need to pull together people from many specialties — engineering, product management, design, marketing, legal, etc. — to execute projects and create value. This has resulted in large teams of specialists who work together. But if a team of 2 persons is to get work done that require 5 different specialities, then some of those individuals must play roles outside a single speciality. In some small teams, individuals do have deep specializations. For example, one might be a great engineer and another a great PM. But they also understand the other key functions needed to move a project forward, and can jump into thinking through other kinds of problems as needed. Of course, proficiency with AI tools is a big help, since it helps us to think through problems that involve different roles.
Even in a two-person team, to move fast, communication bottlenecks also must be minimized. This is why I value teams that work in the same location. Remote teams can perform well too, but the highest speed is achieved by having everyone in the room, able to communicate instantaneously to solve problems.
This letter focuses on AI-native teams with around 2-10 persons, but not everything can be done by a small team. I'll address the coordination of larger teams in the future.
I realize these shifts to job roles are tough to navigate for many people. At the same time, I am encouraged that individuals and small teams who are willing to learn the relevant skills are now able to get far more done than was possible before. This is the golden age of learning and building!
Keep building,
Andrew
A MESSAGE FROM DEEPLEARNING.AI

In “Spec-Driven Development,” you will learn a disciplined workflow for working with coding agents. Write specs, guide implementation step by step, and stay in control of what you build! Join in for free
News
Life After Llama
Meta pivoted from its open-weights strategy to deliver a closed alternative.
What’s new: Meta introduced its first AI model in a year and the first product of its nine-month-old Superintelligence Labs. Muse Spark is a natively multimodal reasoning model with support for tool use and multi-agent orchestration. It leads in some health and multimodal benchmarks but falls short in coding and agentic work, which Meta frames as validating an architectural redesign on which the company plans to build larger models.
- Input/output: Text, image, speech in (up to 262,000 tokens), text out
- Performance: Fourth place on the Artificial Analysis Intelligence Index
- Availability: Free via meta.ai and Meta AI app; coming to WhatsApp, Instagram, Facebook, Messenger, and Ray-Ban Meta AI glasses; API preview for selected partners
- Features: Three reasoning modes (instant, thinking, contemplating), shopping mode
- Undisclosed: Parameter count, architecture, training data and methods, output size limit
How it works: Meta disclosed limited technical details about Muse Spark but highlighted gains in training efficiency and multi-agent orchestration plus a domain-specific investment in health.
- The company reworked its pretraining approach, model architecture, optimization, and data curation. Meta says Muse Spark matches Llama 4 Maverick’s capabilities with over an order of magnitude less processing devoted to training.
- Post-training involved reinforcement learning in which the team penalized the model for using excessive reasoning tokens, a process the team calls thought compression. Under this penalty, the model first improved by reasoning longer, then learned to compress its reasoning, and then extended its reasoning for further improvement.
- Rather than processing a single chain of thought, contemplating mode launches multiple agents that propose solutions, refine them, and aggregate the results in parallel. Meta says this achieves better performance while incurring comparable latency.
- To improve health reasoning, Meta enlisted more than 1,000 physicians to help curate training data aimed at producing more accurate and thorough health responses.
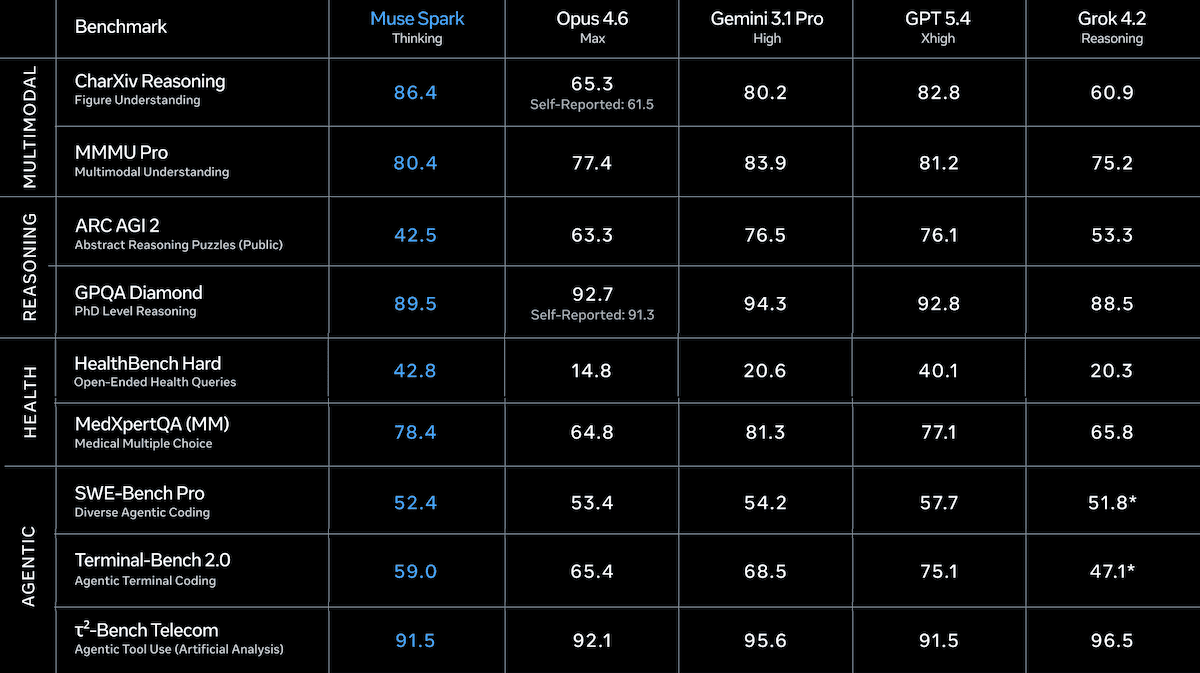
Results: Muse Spark’s benchmark performance is generally competitive and notably token-efficient. Meta acknowledged that it shows gaps in coding and agentic performance.
- On the Artificial Analysis Intelligence Index, a composite of 10 benchmarks of economically useful tasks, Muse Spark set to reasoning (52) places fourth overall behind the tied-for-third Gemini 3.1 Pro Preview set to high reasoning and GPT-5.4 set to xhigh reasoning (both 57), and Claude Opus 4.6 set to max reasoning (53). Muse Spark used around 59 million tokens to complete the index, compared to roughly 158 million tokens for Claude Opus 4.6 and 116 million tokens for GPT-5.4.
- Muse Spark earns top marks in at least one multimodal benchmark. On CharXiv Reasoning (understanding charts and figures), Muse Spark (86.4 percent) outperformed GPT-5.4 (82.8 percent) and Gemini 3.1 Pro (80.2 percent), according to Meta. On MMMU Pro (solving multidisciplinary visual problems), Muse Spark (81 percent) placed second behind Gemini 3.1 Pro (82 percent), according to Artificial Analysis.
- On Artificial Analysis’ Coding Index, a weighted average of coding benchmarks, Muse Spark (47) fell behind GPT-5.4 (57), Gemini 3.1 Pro Preview (56), and Claude Sonnet 4.6 set to max reasoning (51).
- Artificial Analysis independently measured Muse Spark in Thinking mode at 39.9 percent on Humanity’s Last Exam, trailing Gemini 3.1 Pro Preview (44.7 percent) and GPT-5.4 (41.6 percent). However, Meta reports 58 percent when Muse Spark used contemplating mode.
- In Meta’s tests, Muse Spark outperformed all models on HealthBench Hard, a subset of OpenAI’s health benchmark, at 42.8 percent, ahead of second-best GPT-5.4 (40.1 percent). Muse Spark also led DeepSearchQA, an agentic browsing evaluation, at 74.8 percent, ahead of Claude Opus 4.6 Max (73.7 percent).
Behind the news: Muse Spark is the Meta’s first new model since it reorganized its AI labs after critics alleged that the training data for Llama 4 been contaminated with benchmark answers. In June 2025, Meta spent $14.3 billion for a 49 percent stake in Scale AI, brought in cofounder Alexandr Wang as chief AI officer, and launched a hiring spree with pay packages worth hundreds of millions of dollars. The proprietary release has raised concerns among developers, many of whom have built projects on open-weights Llama models.
Why it matters: Meta is investing in the capabilities that matter most for its product ambitions: multimodal perception for billions of camera-equipped users, health reasoning for one of the most common categories of AI queries, and multi-agent coordination for multi-step tasks. With a private API preview in progress, it’s positioning itself to compete for business customers alongside OpenAI, Google, and Anthropic. However, its pivot away from being the leading U.S. champion of open weights is a significant loss for the developer community.
We’re thinking: Muse Spark’s contemplating mode and Kimi K2.5’s Agent Swarm point to an emerging pattern: More labs are scaling performance by training models to orchestrate multiple agents at inference time rather than training ever-larger single models.
Big Pharma Bets Big on AI
Generative AI has proven that it can produce text, images, audio, video, and code. The world’s most valuable pharmaceutical company is betting billions that it can produce drugs as well.
What’s new: Pharma giant Eli Lilly agreed to give as much as $2.75 billion to Insilico Medicine, a Hong Kong-based biotechnology company that applies generative AI across its drug-discovery pipeline. Initially, Lilly will pay $115 million for exclusive rights to develop and sell undisclosed drugs that have not yet been tested in humans, while further payments will be tied to developmental, regulatory, and commercial milestones, Fierce Biotech reported. This is the third agreement between the companies following an AI software license in 2023 and a $100 million research collaboration in November 2025.
AI drug-discovery: Founded in 2014, Insilico has used AI to develop 28 candidate drugs, roughly half of which are in clinical trials. The most advanced one, Rentosertib, targets idiopathic pulmonary fibrosis (IPF), a disease in which scarring progressively reduces lung function. A Phase 2a trial (an early, small-scale test of efficacy) showed positive results. A second drug, Garutadustat, which is intended to treat inflammatory bowel disease, entered Phase 2a in January 2026.
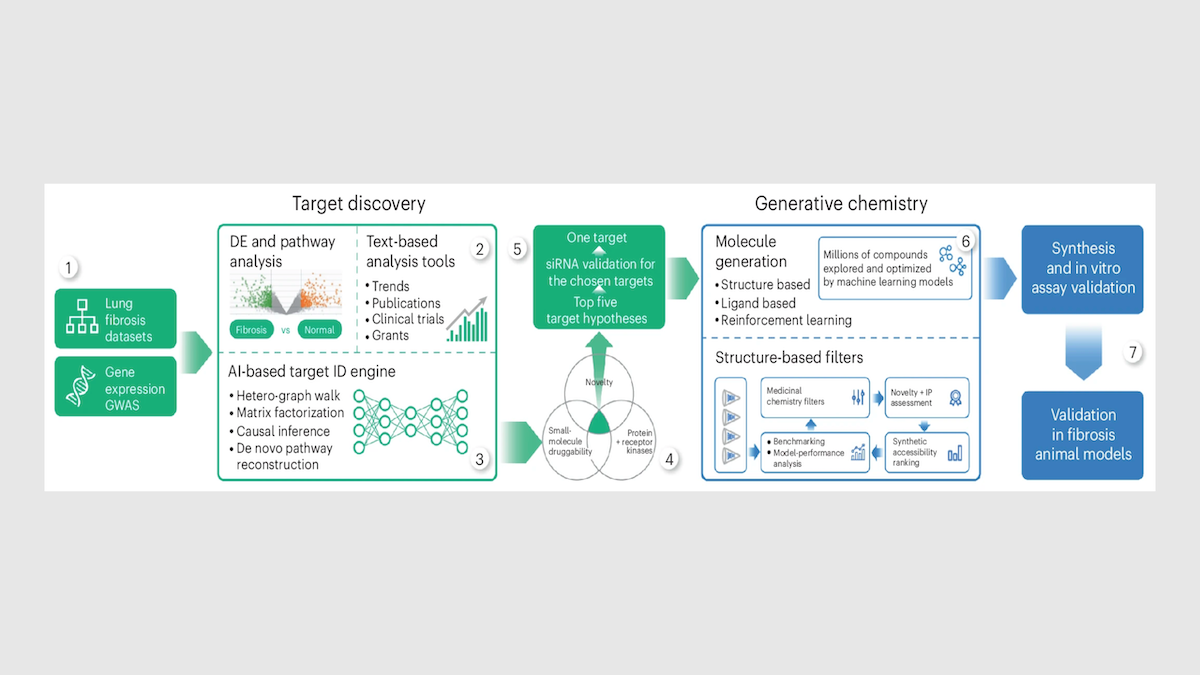
How it works: After choosing a disease, Insilico applies proprietary generative models to two stages of drug discovery: identifying which protein to target and designing a molecule to act on that protein.
- To find targets, Insilico uses a tool called PandaOmics to analyze biological datasets, published research, patents, clinical trials, and grant applications. Deep learning models rank candidate targets by relevance to a disease, suitability as drug targets, and novelty. For IPF, PandaOmics identified TNIK, a protein involved in the scarring that characterizes IPF and related diseases, as the top candidate. No one had previously tried to treat IPF by blocking TNIK.
- To design a molecule to block TNIK, the team used Chemistry42. Roughly 30 generative models ran in parallel to produce candidate molecular structures, each one optimized for binding strength, toxicity, solubility, and other properties. Scientists evaluated and refined the output over multiple rounds. The process yielded a lead molecule after Insilico synthesized and tested fewer than 80 compounds. In conventional drug discovery, teams often screen 200,000 to 1 million existing compounds before synthesizing and testing hundreds of candidates.
- The time from identifying targets to synthesizing molecules that are ready for preclinical safety testing took roughly 18 months, compared to a typical five to six years. That pace held steady across more than 20 Insilico programs between 2021 and 2024, each of which synthesized and tested around 60 to 200 molecules to find one preclinical candidate.
Behind the news: Developing a new drug typically takes 10 to 15 years and costs more than $2 billion, and roughly 86 percent of candidates fail to reach approval. A growing number of drug developers apply AI to accelerate the process. A peer-reviewed analysis catalogued 173 AI-enabled drug programs across clinical stages as of mid-2025. Nonetheless, no AI-discovered drug has received regulatory approval. Of the drug candidates that reach Phase 2, 70 percent fail to reach the next phase, including AI-designed drugs from BenevolentAI and Recursion Pharmaceuticals.
Why it matters: Insilico’s pipeline suggests generative AI can tackle one of the hardest problems in science: finding a molecule that binds to a particular protein, is absorbed by the body, isn’t toxic, and helps patients. In Rentosertib’s Phase 2a trial, participants who took the highest dose gained an average of 98.4 milliliters in forced vital capacity (a measure of lung function), while those who took a placebo declined by 20.3 milliliters. That is early but concrete evidence that AI-generated drugs can help patients.
We’re thinking: AI is accelerating drug development, but it remains to be seen whether those accelerated compounds will pass clinical trials at a higher rate than those developed in traditional ways.
US States Move Forward With AI Laws
U.S. states are continuing to enact laws that regulate AI, despite President Trump’s efforts to discourage state-by-state legislation in favor of national laws.
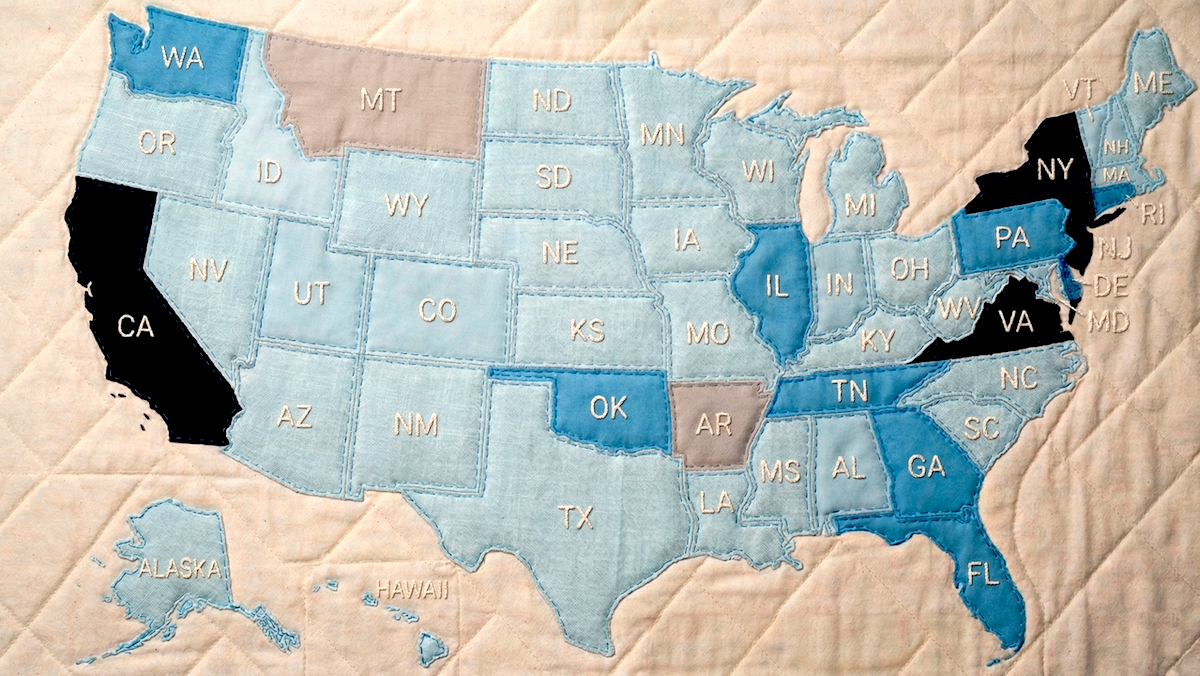
What’s new: Many states have moved to regulate AI this year, contributing to a growing patchwork of legislation that stands to complicate developers’ efforts to meet legal requirements. Collectively, the states are considering numerous bills — more than 1,500, by one tally — in addition to more than 100 existing laws enacted by 40 states that are designed to discourage use of chatbots by young people, require permission to train AI systems on copyrighted material, or require security testing of AI systems, The New York Times reported.
How it works: California governor Gavin Newsom has been the most visible opponent of the Trump Administration’s effort to discourage state-by-state regulation of AI. But more than 40 states are in the process of passing their own laws. Among them are:
- California. Often a bellwether for regulation in the U.S. and beyond, California has established the nation’s most comprehensive AI laws. On March 30, Governor Newsom issued an executive order requiring that AI tools used by the state protect privacy, support civil rights, and mitigate bias. Starting in August, large tech platforms and AI providers must apply an invisible watermark to AI-generated output. These provisions add to a variety of laws that took effect in January. For instance, developers of advanced AI models must assess catastrophic risks and report serious safety incidents. LLM providers must prevent chatbots from discussing self-harm or sex with minors and remind users periodically when they are chatting with AI.
- Colorado. In 2024, Colorado passed a sweeping AI law with some of the most stringent regulations in the county. Scheduled to go into effect in July, it requires “developers and deployers of high-risk AI systems” to protect consumers from algorithmic discrimination by systems that are designed to make decisions in high-stakes fields such as education, employment, finance, healthcare, and housing. Developers must document system limitations, training data, and efforts to mitigate risks, while those who deploy models must assess their impact annually and alert consumers when AI makes a decision that affects them. However, pressure from businesses and tech companies has prompted the General Assembly to consider relaxing a requirement for annual impact assessments and other burdens.
- Minnesota. Minnesota moved early in 2023 by prohibiting deepfake election interference. Now the legislature is considering a bill that would ban use of AI to remove clothing from photos of people or set prices dynamically based on personal behavior. In August, a law will take effect that prohibits health insurance companies from using AI to deny care without a review by a relevant doctor.
- New York. This state has established some of the nation’s most stringent AI regulations, from early protections against deepfakes to broader restrictions in 2026. Starting in January 2027, model makers that have revenue of over $500 million must observe strict protocols to block users from creating bioweapons or autonomous hacking tools. They must audit these efforts annually and report incidents promptly.
- Ohio. A law that took effect in late March prohibits use of AI to replicate a person’s voice or likeness to sell a product or produce intimate images without permission. Ohio is considering a bill that would deny AI systems legal personhood and legal rights in the roles of spouse, manager, or property owner. It is also considering a ban on using AI to coordinate retail and rental prices among competitors.
- Utah. In 2026 alone, the Utah legislature passed several bills that refined the state’s 2024 Artificial Intelligence Policy Act. For instance, a bill that’s scheduled to take effect in coming months prohibits platform companies from distributing nonconsensual, sexually explicit deepfakes. Another prohibits health insurers from using AI to deny care without a doctor’s input. The state lets AI companies apply for temporary relief from certain regulations while they test new technology under regulatory supervision.
Behind the news: The Trump Administration started promoting national regulations over state laws as worries grew that a state-by-state patchwork could impede U.S. leadership in AI. In December, President Trump signed an executive order designed to discourage state-level legislation. The order targets laws that would stifle innovation as well as anti-bias regulations that could be perceived to have a political slant. It threatens to withhold federal funds from states that pass or enforce “onerous” AI laws and urges Congress to block state regulations. In March, it followed up with guidelines for federal legislation. The guidelines support protections for children and controls on electricity price hikes driven by AI data centers’ increasing consumption of energy.
Why it matters: An increasingly complex regulatory landscape around AI creates a potential minefield for compliance in the U.S. and contributes to unfocused, contradictory regulation worldwide. A given AI model may be required to pass a bias audit in Colorado, provide watermarking in California, and meet reporting thresholds in New York — all while the federal government moves to preempt these requirements. This jurisdictional tug-of-war increases the cost of building AI systems, adds to the legal risk of deploying new applications and services, and raises the possibility that government funding may be withheld for complying with state mandates the federal government considers onerous.
We’re thinking: Some current state-level mandates are sensible. Users should be able to rely on AI companies to preserve their privacy, for instance, and children should be protected from AI slop generated by and for adults. But such requirements should be imposed at the national level. We call on Congress to build a more cohesive, stable regulatory environment.
Simulating Diverse Human Cohorts
If you want to understand how the public will respond to your offerings, large language models can simulate users who answer questions about capabilities, features, promotions, or prices. However, LLMs don't respond with the range of variations that humans do. Researchers developed a method that prompts LLMs to take on personas with a customizable variety of attitudes.
What’s new: Davide Paglieri, Logan Cross, and colleagues at Google proposed Persona Generators. Their approach produces code that prompts an LLM to compose prompts for 25 personas that cover the map.
Key insight: Making an LLM take on a human persona typically is a matter of composing an effective prompt (for instance, “Answer the following question as if in politics today, you considered yourself a Democrat. . . .”). However, this approach tends to elicit average responses that don’t reflect the range that a human population would provide — even if the prompt explicitly directs the LLM to adopt specific demographic characteristics. An alternative is to direct a model to modify persona prompts programmatically until they produce output that covers a specific range of opinions, attitudes, or concerns. Given guidelines that define the scope of the persona population (specifically attitudes ranked by degrees of agreement to disagreement), an evolutionary algorithm can push the model to produce a set of prompts that elicit the full range of responses.
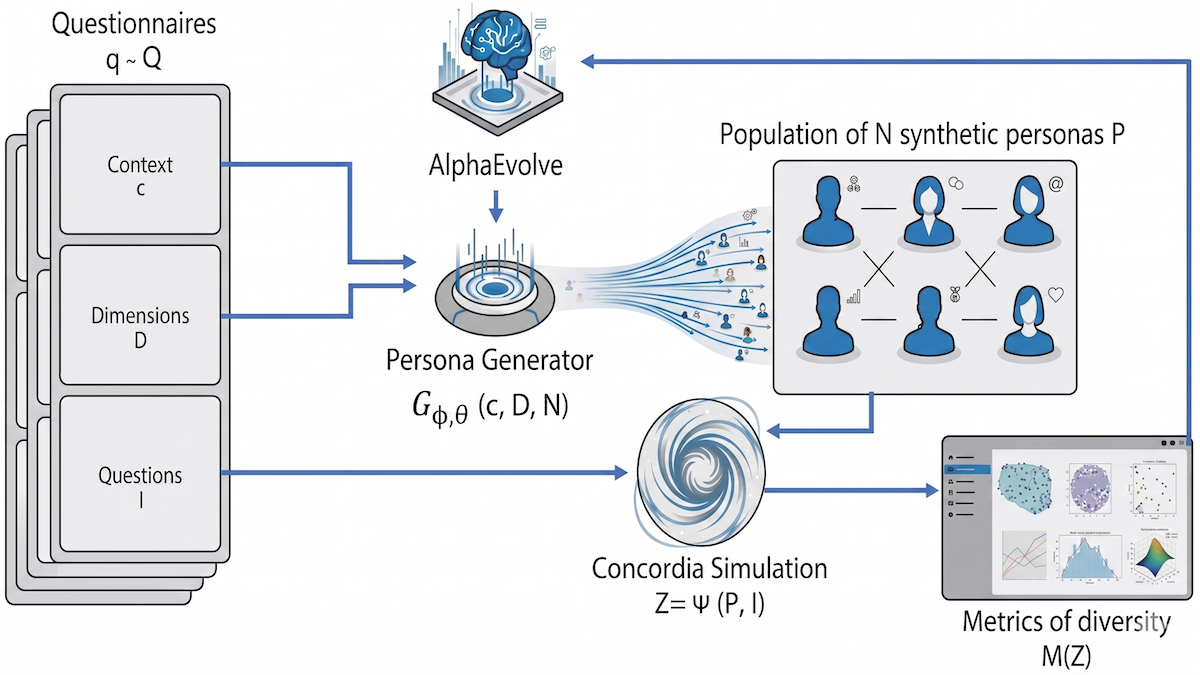
How it works: The authors used the evolutionary method AlphaEvolve to generate code that (i) generated 25 prompts for personas and (ii) maximized the diversity of their attitudes based on their answers to a set of generated questionnaires.
- The authors started by using Gemini 2.5 Pro to generate 30 questionnaires on a variety of subject matter such as health care, financial literacy, and conspiracy theories. Each questionnaire included a context (description of the topic), a set of “diversity axes" (such as tolerance of risk or trust in institutions), and questions related to the axes to be answered on a scale between 1 (strongly agree) to 5 (strongly disagree).
- They created code (initially written by the authors, then updated iteratively by AlphaEvolve) to produce 25 persona prompts per questionnaire.
- To automate production of the personas’ responses, the authors used Concordia, a library for building agent-based simulations, to prompt Gemma 3-27B-IT. The LLM adopted each persona in turn and responded to the corresponding questionnaire. For each persona, they converted its answers into a vector.
- To evaluate diversity among the personas that answered each questionnaire, they computed six metrics, such as average distance between any two vectors and the degree to which the population of personas covered all possible responses.
- AlphaEvolve worked in parallel on 10 different versions of the code, iteratively updating them to maximize the diversity metrics across all the personas. After 500 iterations, the authors chose the code that maximized the average of all diversity metrics.
- At inference, given a context and a set of diversity axes, the system created 25 diverse personas.
Results: Given a fresh context and diversity axes, the resulting personas consistently exceeded the diversity metrics of Nemotron Personas, a large dataset of persona prompts that are based on U.S. demographic statistics, and persona prompts produced by a Concordia memory generator based on generated memories from childhood to adulthood. Given a set of test questionnaires, the authors’ personas covered 82 percent of possible responses, while Nemotron Personas covered 76 percent and Concordia memory generator covered 46 percent.
Why it matters: Organizations that aim to expand their audiences can benefit from synthetic personas that broadly reflect public sentiment, and those that create synthetic personas to match their real-world audiences can gain insights from a more diverse crowd. This work shifts the objective from matching training data (which tends to generate the most probable outputs and not the outliers) to covering all desired possibilities. Optimizing the persona generator, rather than individual personas, unlocks a broader representation of likely user behavior.
We’re thinking: Synthetic personas offer an intriguing possibility for navigating the product-management bottleneck, the difficulty of deciding what to build when you can build easily by prompting an LLM.



