Empirical Characterization of Rationale Stability Under Controlled Perturbations for Explainable Pattern Recognition
arXiv cs.AI / 4/7/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The paper proposes a new metric to quantify rationale (explanation) stability across inputs that share the same label and under label-preserving perturbations, addressing a gap in instance-centric XAI evaluation.
- It implements the metric using SHAP-based feature importance computed from a pre-trained BERT model on SST-2, with robustness checks across RoBERTa, DistilBERT, and IMDB.
- The metric measures cosine similarity of SHAP value vectors to detect inconsistent explanation behaviors, such as over-reliance on particular features or drifting reasoning for similar predictions.
- Experiments test whether the metric can identify misaligned predictions and inconsistencies in explanations, benchmarking against standard fidelity metrics.
- The work includes a publicly available codebase and is positioned as a framework for more robust verification of rationale stability in trustworthy pattern recognition systems.
Related Articles

Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Could it be that this take is not too far fetched?
Reddit r/LocalLLaMA

npm audit Is Broken — Here's the Claude Code Skill I Built to Fix It
Dev.to

Meta Launches Muse Spark: A New AI Model for Everyday Use
Dev.to
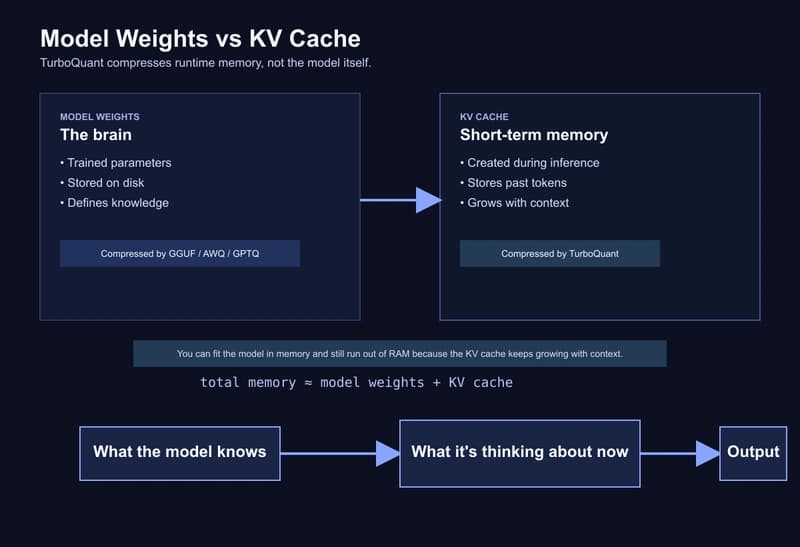
TurboQuant on a MacBook: building a one-command local stack with Ollama, MLX, and an automatic routing proxy
Dev.to