Qwen3.6-35B-A3B GGUF from Unsloth is quite a bit slower?
Reddit r/LocalLLaMA / 4/18/2026
💬 OpinionDeveloper Stack & InfrastructureSignals & Early TrendsTools & Practical Usage
Key Points
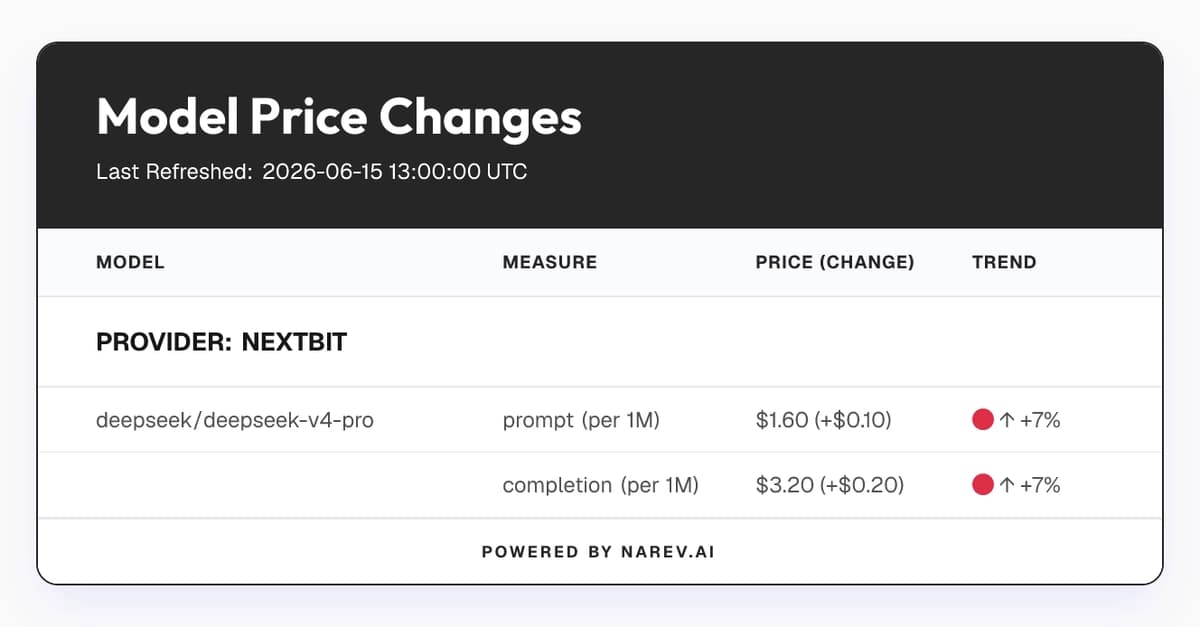
- A Reddit user reports that Unsloth-produced GGUFs for Qwen3.6-35B run noticeably slower on a CPU-only Debian 13 setup with llama.cpp, yielding about 30% fewer tokens per second than similar models from other creators.
- They observe longer latency for follow-up responses with the Unsloth GGUFs (e.g., ~25–29 seconds vs ~14–20 seconds in the reported comparisons), suggesting performance differences beyond just initial tokens.
- The comparison includes two quantization variants (IQ4_NL) and two model sizes within the Qwen3.6-35B family, where Unsloth builds show lower tokens/sec (about ~5.9–6.1 t/s) than the alternatives (~8.7–8.8 t/s).
- The user suggests there may be room for optimization and shares a snippet of llama.cpp startup logs (CPU backend, n_parallel auto→4, thread counts, and model loading) as context for troubleshooting.
- The claim is framed as potentially configuration/model-build dependent, and the user invites others to reproduce/verify the slowdown and look for causes in the GGUF generation or runtime settings.
Continue reading this article on the original site.
Read original →