AI Evals, Part 2: Error Analysis The Unglamorous Superpower Behind Good Evals
Dev.to / 6/13/2026
💬 OpinionIdeas & Deep AnalysisTools & Practical UsageModels & Research
Key Points
- The post argues that most teams choose the wrong starting point for AI evals by jumping to generic metrics without first defining what failures to measure.
- It frames “error analysis” as the highest-leverage step in the eval pipeline because it generates the real signal that downstream dashboards and processes operationalize.
- It explains the “comprehension gap” between developers and how the model behaves on real inputs at production scale, noting that metrics cannot bridge this gap unless failure modes are already identified.
- It describes error analysis as a deliberately low-tech loop: sample 50–100 real outputs, read them carefully, and open-code each failure with precise free-text notes about what went wrong.
- The article positions error analysis as a truth-over-scale approach, using careful sampling to discover issues the team’s initial assumptions may miss.
Continue reading this article on the original site.
Read original →Related Articles

Black Hat USA
AI Business
Meta’s months-old AI unit is a soul-crushing gulag, say the engineers stuck inside it
TechCrunch
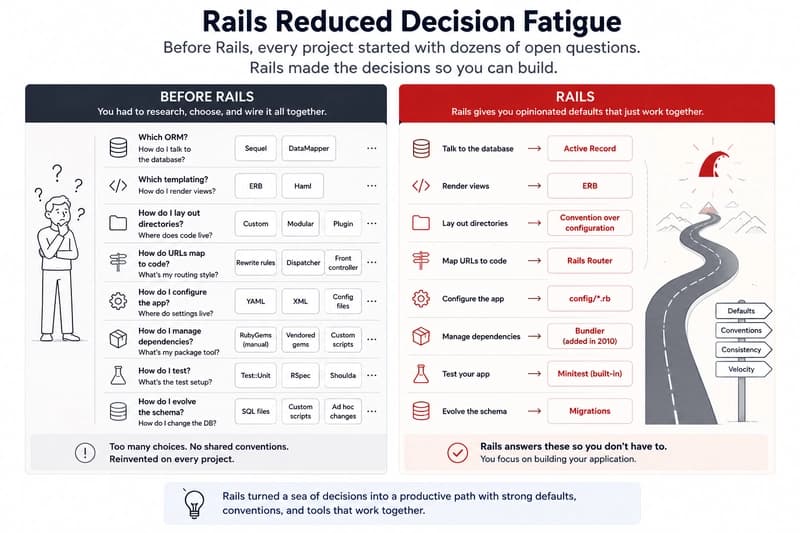
Rails Won Because It Had Opinions. AI-Native Apps Need the Same Thing.
Dev.to
Kimi K2.7-Code Cuts AI Costs, but Benchmarks Crack
Dev.to
AI's Existential Dread: A Day of Digital Delight
Dev.to